 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquiformerV3: Scaling Efficient, Expressive, and General SE(3)-Equivariant Graph Attention Transformers
Apr 10, 2026As $SE(3)$-equivariant graph neural networks mature as a core tool for 3D atomistic modeling, improving their efficiency, expressivity, and physical consistency has become a central challenge for large-scale applications. In this work, we introduce EquiformerV3, the third generation of the $SE(3)$-equivariant graph attention Transformer, designed to advance all three dimensions: efficiency, expressivity, and generality. Building on EquiformerV2, we have the following three key advances. First, we optimize the software implementation, achieving $1.75\times$ speedup. Second, we introduce simple and effective modifications to EquiformerV2, including equivariant merged layer normalization, improved feedforward network hyper-parameters, and attention with smooth radius cutoff. Third, we propose SwiGLU-$S^2$ activations to incorporate many-body interactions for better theoretical expressivity and to preserve strict equivariance while reducing the complexity of sampling $S^2$ grids. Together, SwiGLU-$S^2$ activations and smooth-cutoff attention enable accurate modeling of smoothly varying potential energy surfaces (PES), generalizing EquiformerV3 to tasks requiring energy-conserving simulations and higher-order derivatives of PES. With these improvements, EquiformerV3 trained with the auxiliary task of denoising non-equilibrium structures (DeNS) achieves state-of-the-art results on OC20, OMat24, and Matbench Discovery.
All-atom Diffusion Transformers: Unified generative modelling of molecules and materials
Mar 05, 2025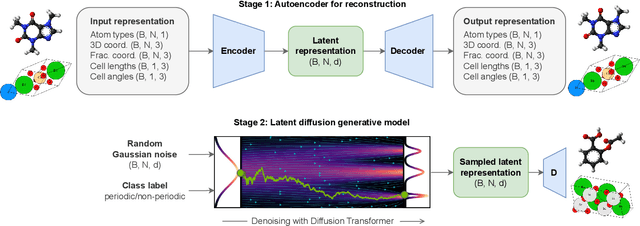

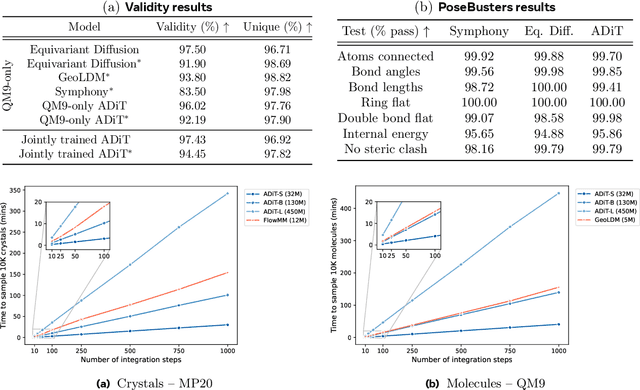
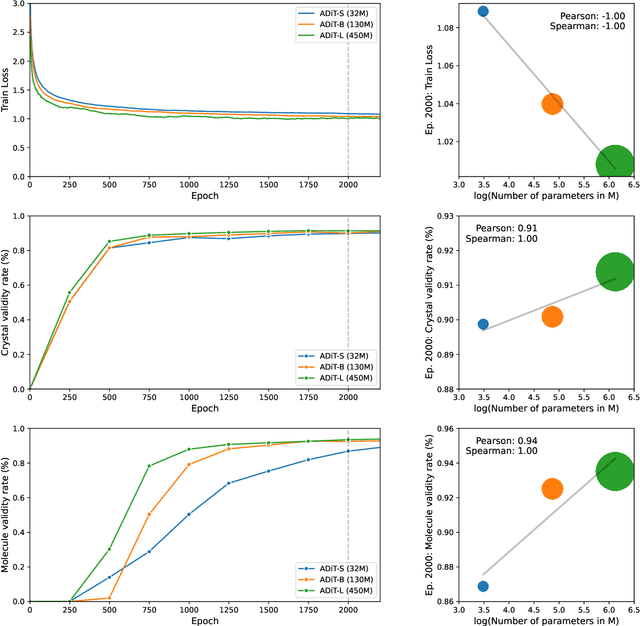
Diffusion models are the standard toolkit for generative modelling of 3D atomic systems. However, for different types of atomic systems - such as molecules and materials - the generative processes are usually highly specific to the target system despite the underlying physics being the same. We introduce the All-atom Diffusion Transformer (ADiT), a unified latent diffusion framework for jointly generating both periodic materials and non-periodic molecular systems using the same model: (1) An autoencoder maps a unified, all-atom representations of molecules and materials to a shared latent embedding space; and (2) A diffusion model is trained to generate new latent embeddings that the autoencoder can decode to sample new molecules or materials. Experiments on QM9 and MP20 datasets demonstrate that jointly trained ADiT generates realistic and valid molecules as well as materials, exceeding state-of-the-art results from molecule and crystal-specific models. ADiT uses standard Transformers for both the autoencoder and diffusion model, resulting in significant speedups during training and inference compared to equivariant diffusion models. Scaling ADiT up to half a billion parameters predictably improves performance, representing a step towards broadly generalizable foundation models for generative chemistry. Open source code: https://github.com/facebookresearch/all-atom-diffusion-transformer
Generalizing Denoising to Non-Equilibrium Structures Improves Equivariant Force Fields
Mar 14, 2024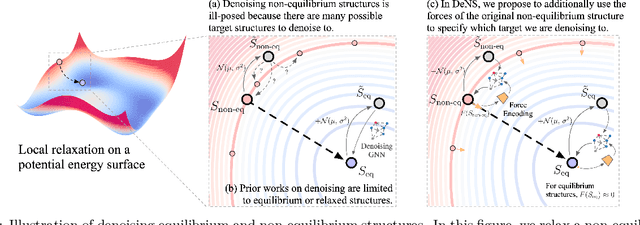
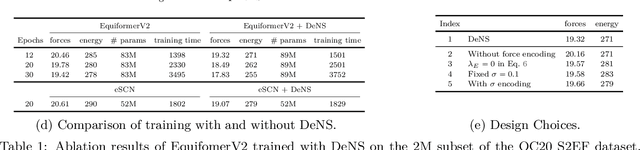
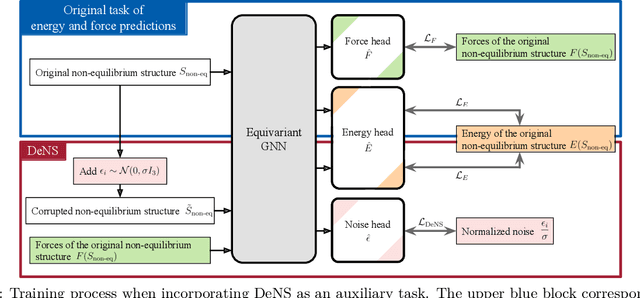
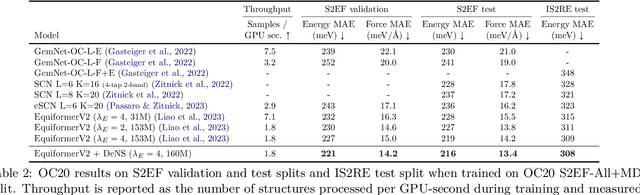
Understanding the interactions of atoms such as forces in 3D atomistic systems is fundamental to many applications like molecular dynamics and catalyst design. However, simulating these interactions requires compute-intensive ab initio calculations and thus results in limited data for training neural networks. In this paper, we propose to use denoising non-equilibrium structures (DeNS) as an auxiliary task to better leverage training data and improve performance. For training with DeNS, we first corrupt a 3D structure by adding noise to its 3D coordinates and then predict the noise. Different from previous works on denoising, which are limited to equilibrium structures, the proposed method generalizes denoising to a much larger set of non-equilibrium structures. The main difference is that a non-equilibrium structure does not correspond to local energy minima and has non-zero forces, and therefore it can have many possible atomic positions compared to an equilibrium structure. This makes denoising non-equilibrium structures an ill-posed problem since the target of denoising is not uniquely defined. Our key insight is to additionally encode the forces of the original non-equilibrium structure to specify which non-equilibrium structure we are denoising. Concretely, given a corrupted non-equilibrium structure and the forces of the original one, we predict the non-equilibrium structure satisfying the input forces instead of any arbitrary structures. Since DeNS requires encoding forces, DeNS favors equivariant networks, which can easily incorporate forces and other higher-order tensors in node embeddings. We study the effectiveness of training equivariant networks with DeNS on OC20, OC22 and MD17 datasets and demonstrate that DeNS can achieve new state-of-the-art results on OC20 and OC22 and significantly improve training efficiency on MD17.
EquiformerV2: Improved Equivariant Transformer for Scaling to Higher-Degree Representations
Jun 21, 2023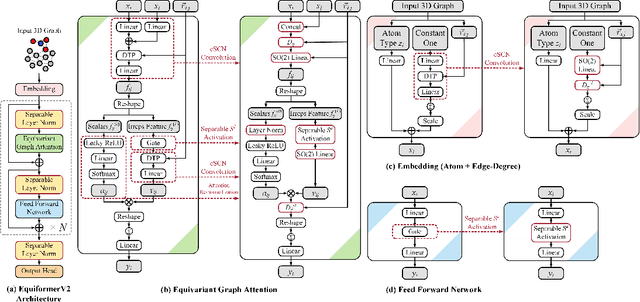
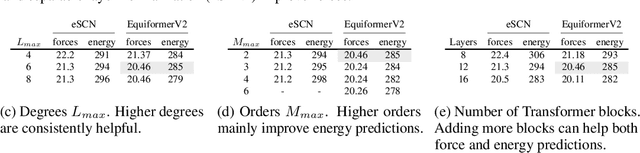
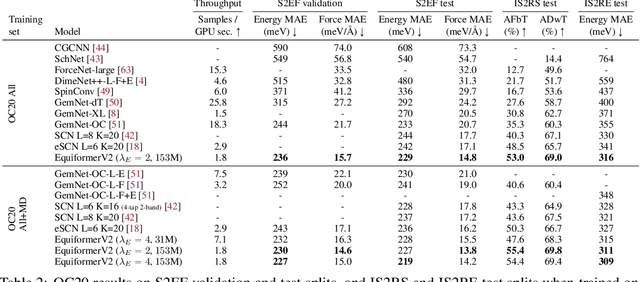
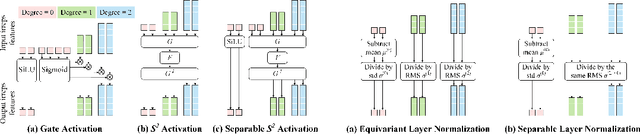
Equivariant Transformers such as Equiformer have demonstrated the efficacy of applying Transformers to the domain of 3D atomistic systems. However, they are still limited to small degrees of equivariant representations due to their computational complexity. In this paper, we investigate whether these architectures can scale well to higher degrees. Starting from Equiformer, we first replace $SO(3)$ convolutions with eSCN convolutions to efficiently incorporate higher-degree tensors. Then, to better leverage the power of higher degrees, we propose three architectural improvements -- attention re-normalization, separable $S^2$ activation and separable layer normalization. Putting this all together, we propose EquiformerV2, which outperforms previous state-of-the-art methods on the large-scale OC20 dataset by up to $12\%$ on forces, $4\%$ on energies, offers better speed-accuracy trade-offs, and $2\times$ reduction in DFT calculations needed for computing adsorption energies.
Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs
Jun 23, 2022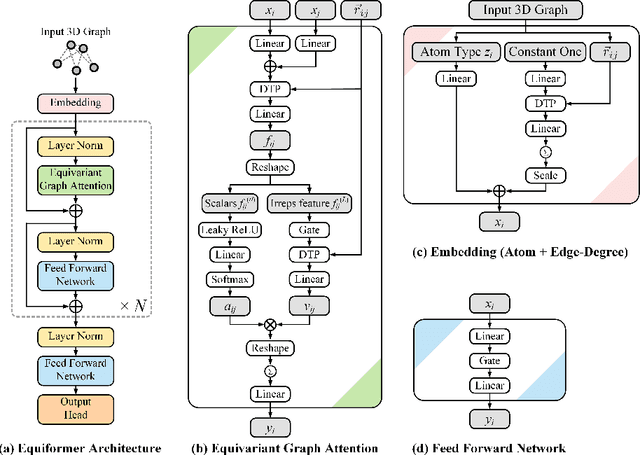
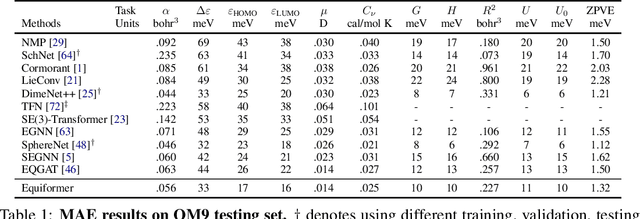


3D-related inductive biases like translational invariance and rotational equivariance are indispensable to graph neural networks operating on 3D atomistic graphs such as molecules. Inspired by the success of Transformers in various domains, we study how to incorporate these inductive biases into Transformers. In this paper, we present Equiformer, a graph neural network leveraging the strength of Transformer architectures and incorporating $SE(3)/E(3)$-equivariant features based on irreducible representations (irreps). Irreps features encode equivariant information in channel dimensions without complicating graph structures. The simplicity enables us to directly incorporate them by replacing original operations with equivariant counterparts. Moreover, to better adapt Transformers to 3D graphs, we propose a novel equivariant graph attention, which considers both content and geometric information such as relative position contained in irreps features. To improve expressivity of the attention, we replace dot product attention with multi-layer perceptron attention and include non-linear message passing. We benchmark Equiformer on two quantum properties prediction datasets, QM9 and OC20. For QM9, among models trained with the same data partition, Equiformer achieves best results on 11 out of 12 regression tasks. For OC20, under the setting of training with IS2RE data and optionally IS2RS data, Equiformer improves upon state-of-the-art models. Code reproducing all main results will be available soon.
On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis
Oct 04, 2021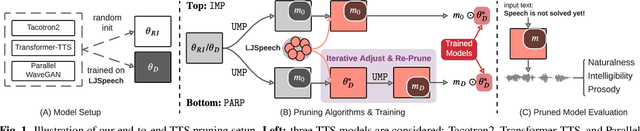
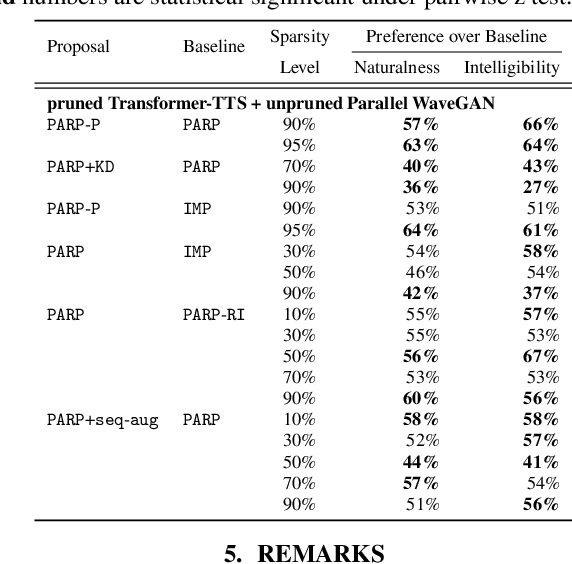
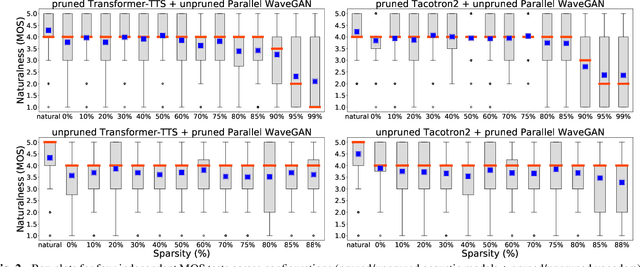
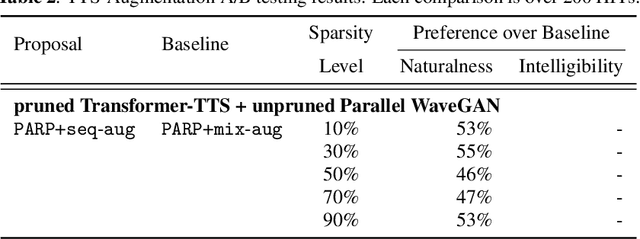
Are end-to-end text-to-speech (TTS) models over-parametrized? To what extent can these models be pruned, and what happens to their synthesis capabilities? This work serves as a starting point to explore pruning both spectrogram prediction networks and vocoders. We thoroughly investigate the tradeoffs between sparstiy and its subsequent effects on synthetic speech. Additionally, we explored several aspects of TTS pruning: amount of finetuning data versus sparsity, TTS-Augmentation to utilize unspoken text, and combining knowledge distillation and pruning. Our findings suggest that not only are end-to-end TTS models highly prunable, but also, perhaps surprisingly, pruned TTS models can produce synthetic speech with equal or higher naturalness and intelligibility, with similar prosody. All of our experiments are conducted on publicly available models, and findings in this work are backed by large-scale subjective tests and objective measures. Code and 200 pruned models are made available to facilitate future research on efficiency in TTS.
Searching for Efficient Multi-Stage Vision Transformers
Sep 01, 2021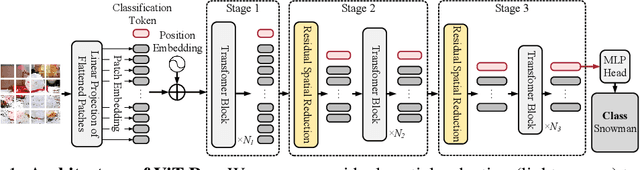

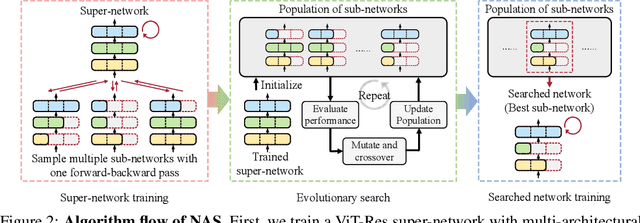

Vision Transformer (ViT) demonstrates that Transformer for natural language processing can be applied to computer vision tasks and result in comparable performance to convolutional neural networks (CNN), which have been studied and adopted in computer vision for years. This naturally raises the question of how the performance of ViT can be advanced with design techniques of CNN. To this end, we propose to incorporate two techniques and present ViT-ResNAS, an efficient multi-stage ViT architecture designed with neural architecture search (NAS). First, we propose residual spatial reduction to decrease sequence lengths for deeper layers and utilize a multi-stage architecture. When reducing lengths, we add skip connections to improve performance and stabilize training deeper networks. Second, we propose weight-sharing NAS with multi-architectural sampling. We enlarge a network and utilize its sub-networks to define a search space. A super-network covering all sub-networks is then trained for fast evaluation of their performance. To efficiently train the super-network, we propose to sample and train multiple sub-networks with one forward-backward pass. After that, evolutionary search is performed to discover high-performance network architectures. Experiments on ImageNet demonstrate that ViT-ResNAS achieves better accuracy-MACs and accuracy-throughput trade-offs than the original DeiT and other strong baselines of ViT. Code is available at https://github.com/yilunliao/vit-search.
PARP: Prune, Adjust and Re-Prune for Self-Supervised Speech Recognition
Jun 10, 2021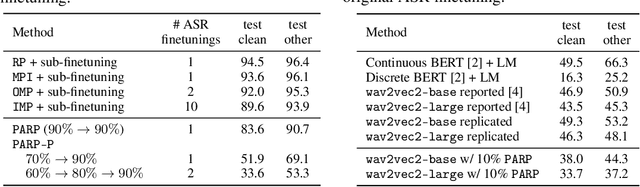
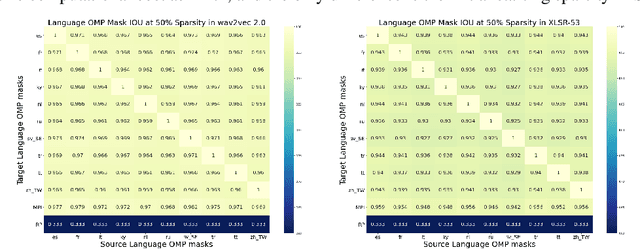
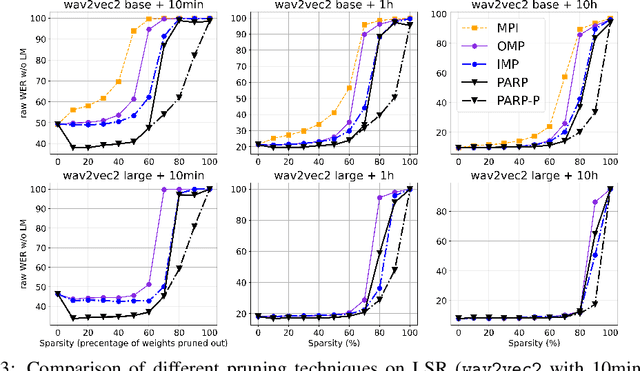

Recent work on speech self-supervised learning (speech SSL) demonstrated the benefits of scale in learning rich and transferable representations for Automatic Speech Recognition (ASR) with limited parallel data. It is then natural to investigate the existence of sparse and transferrable subnetworks in pre-trained speech SSL models that can achieve even better low-resource ASR performance. However, directly applying widely adopted pruning methods such as the Lottery Ticket Hypothesis (LTH) is suboptimal in the computational cost needed. Moreover, contrary to what LTH predicts, the discovered subnetworks yield minimal performance gain compared to the original dense network. In this work, we propose Prune-Adjust- Re-Prune (PARP), which discovers and finetunes subnetworks for much better ASR performance, while only requiring a single downstream finetuning run. PARP is inspired by our surprising observation that subnetworks pruned for pre-training tasks only needed to be slightly adjusted to achieve a sizeable performance boost in downstream ASR tasks. Extensive experiments on low-resource English and multi-lingual ASR show (1) sparse subnetworks exist in pre-trained speech SSL, and (2) the computational advantage and performance gain of PARP over baseline pruning methods. On the 10min Librispeech split without LM decoding, PARP discovers subnetworks from wav2vec 2.0 with an absolute 10.9%/12.6% WER decrease compared to the full model. We demonstrate PARP mitigates performance degradation in cross-lingual mask transfer, and investigate the possibility of discovering a single subnetwork for 10 spoken languages in one run.
NetAdaptV2: Efficient Neural Architecture Search with Fast Super-Network Training and Architecture Optimization
Mar 31, 2021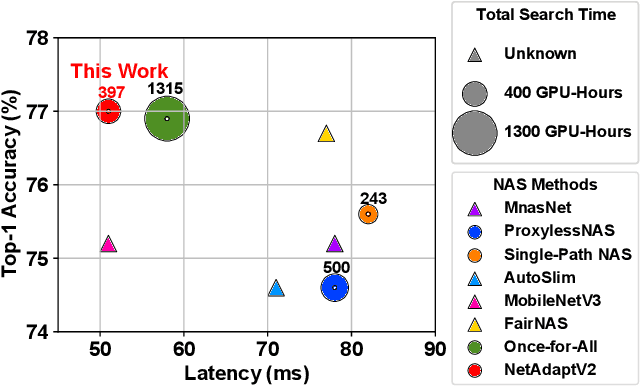
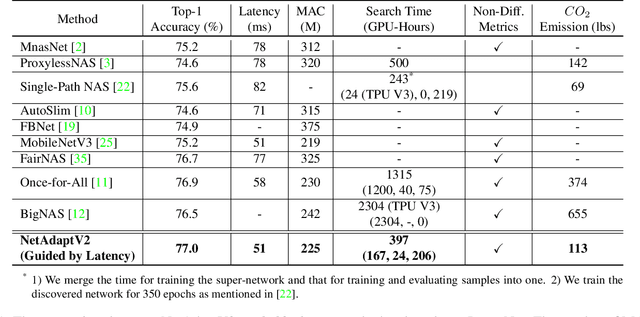

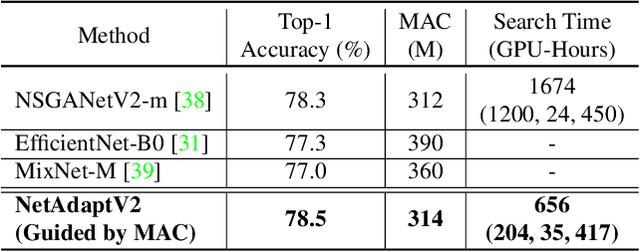
Neural architecture search (NAS) typically consists of three main steps: training a super-network, training and evaluating sampled deep neural networks (DNNs), and training the discovered DNN. Most of the existing efforts speed up some steps at the cost of a significant slowdown of other steps or sacrificing the support of non-differentiable search metrics. The unbalanced reduction in the time spent per step limits the total search time reduction, and the inability to support non-differentiable search metrics limits the performance of discovered DNNs. In this paper, we present NetAdaptV2 with three innovations to better balance the time spent for each step while supporting non-differentiable search metrics. First, we propose channel-level bypass connections that merge network depth and layer width into a single search dimension to reduce the time for training and evaluating sampled DNNs. Second, ordered dropout is proposed to train multiple DNNs in a single forward-backward pass to decrease the time for training a super-network. Third, we propose the multi-layer coordinate descent optimizer that considers the interplay of multiple layers in each iteration of optimization to improve the performance of discovered DNNs while supporting non-differentiable search metrics. With these innovations, NetAdaptV2 reduces the total search time by up to $5.8\times$ on ImageNet and $2.4\times$ on NYU Depth V2, respectively, and discovers DNNs with better accuracy-latency/accuracy-MAC trade-offs than state-of-the-art NAS works. Moreover, the discovered DNN outperforms NAS-discovered MobileNetV3 by 1.8% higher top-1 accuracy with the same latency. The project website is http://netadapt.mit.edu.
3D Shape Reconstruction from a Single 2D Image via 2D-3D Self-Consistency
Nov 29, 2018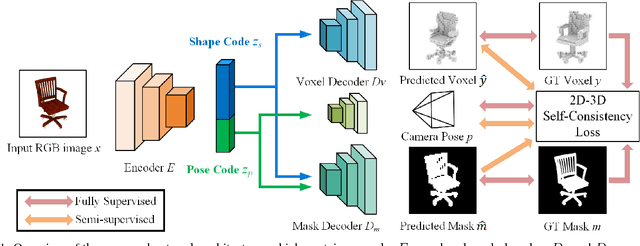
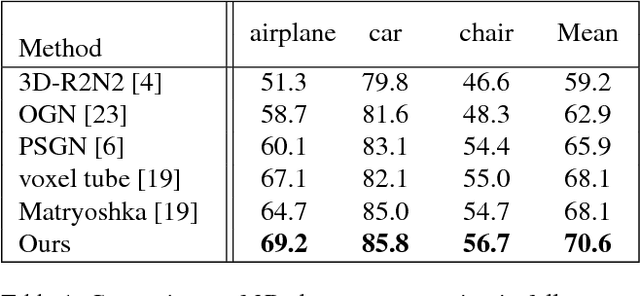


Aiming at inferring 3D shapes from 2D images, 3D shape reconstruction has drawn huge attention from researchers in computer vision and deep learning communities. However, it is not practical to assume that 2D input images and their associated ground truth 3D shapes are always available during training. In this paper, we propose a framework for semi-supervised 3D reconstruction. This is realized by our introduced 2D-3D self-consistency, which aligns the predicted 3D models and the projected 2D foreground segmentation masks. Moreover, our model not only enables recovering 3D shapes with the corresponding 2D masks, camera pose information can be jointly disentangled and predicted, even such supervision is never available during training. In the experiments, we qualitatively and quantitatively demonstrate the effectiveness of our model, which performs favorably against state-of-the-art approaches in either supervised or semi-supervised settings.