 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models of Visually Grounded Imagination
Paper and Code
Feb 25, 2018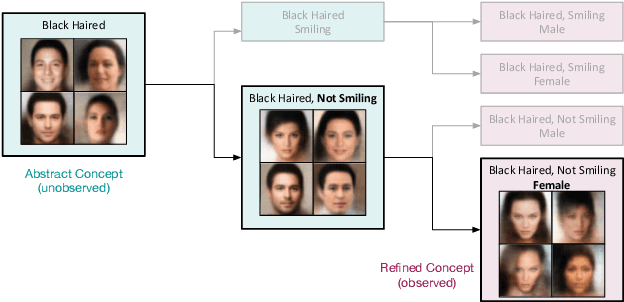
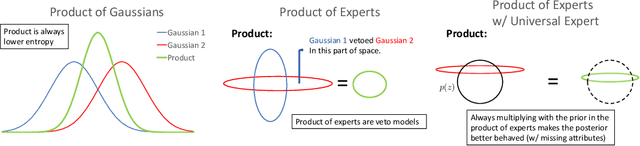
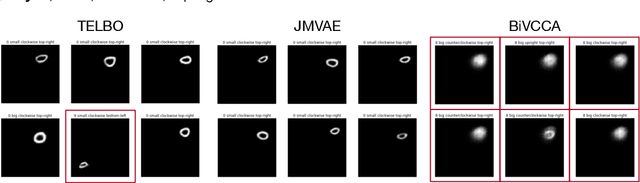
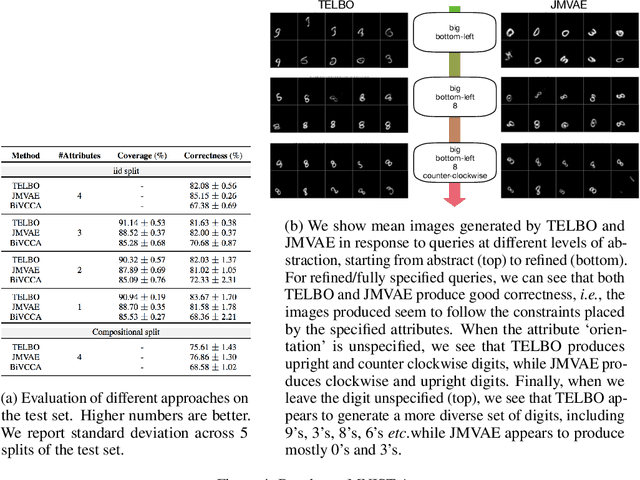
It is easy for people to imagine what a man with pink hair looks like, even if they have never seen such a person before. We call the ability to create images of novel semantic concepts visually grounded imagination. In this paper, we show how we can modify variational auto-encoders to perform this task. Our method uses a novel training objective, and a novel product-of-experts inference network, which can handle partially specified (abstract) concepts in a principled and efficient way. We also propose a set of easy-to-compute evaluation metrics that capture our intuitive notions of what it means to have good visual imagination, namely correctness, coverage, and compositionality (the 3 C's). Finally, we perform a detailed comparison of our method with two existing joint image-attribute VAE methods (the JMVAE method of Suzuki et.al. and the BiVCCA method of Wang et.al.) by applying them to two datasets: the MNIST-with-attributes dataset (which we introduce here), and the CelebA dataset.