 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn explainable transformer circuit for compositional generalization
Paper and Code
Feb 19, 2025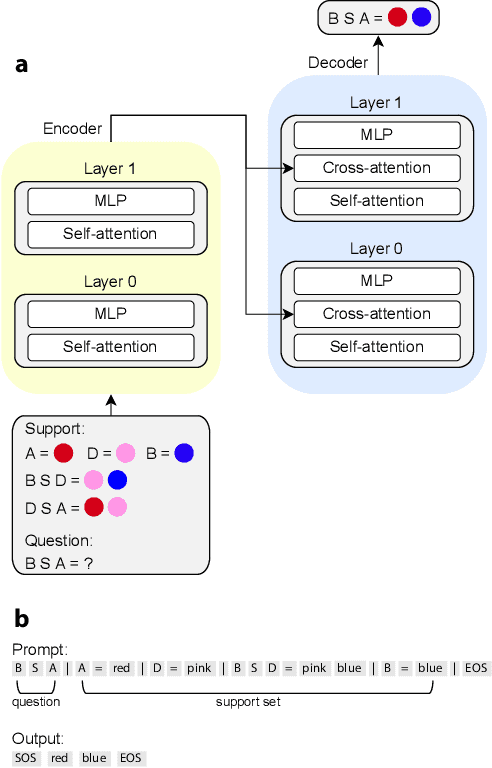
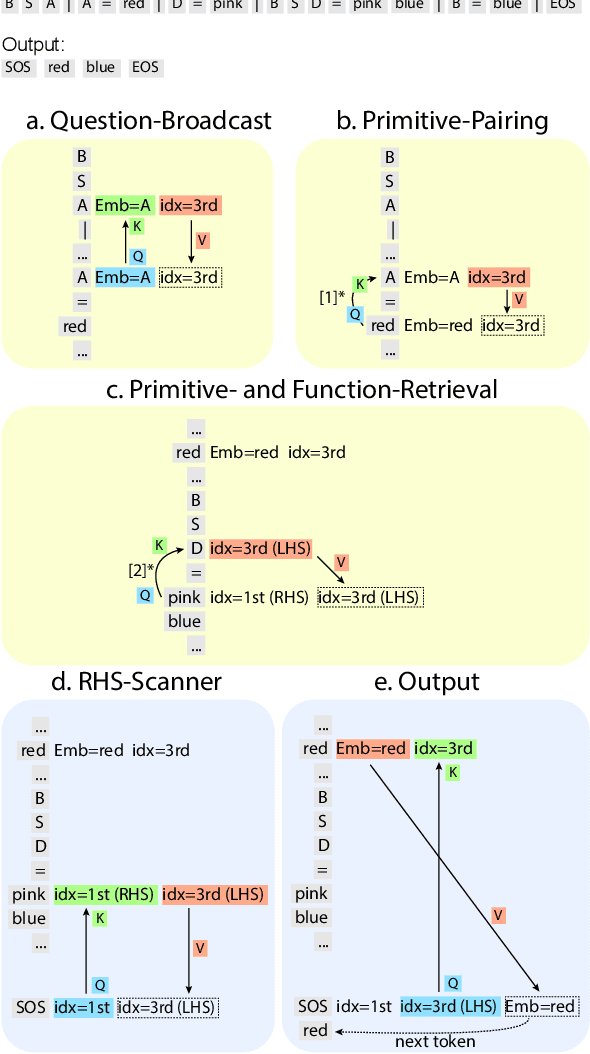
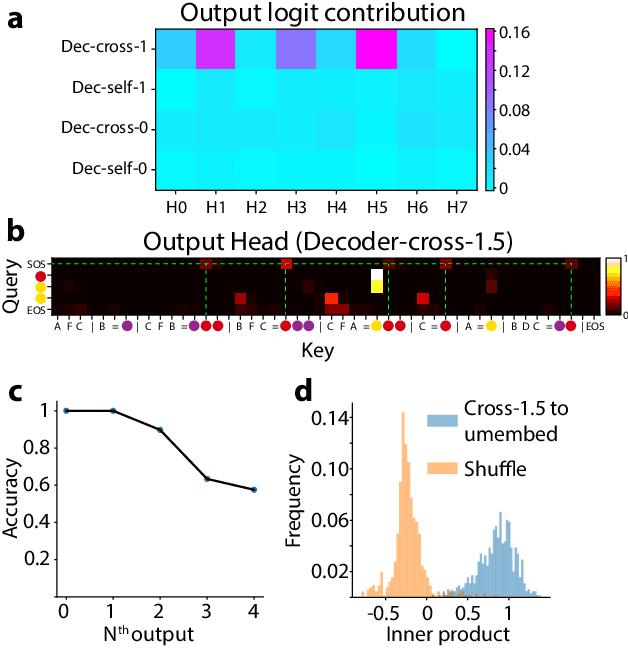
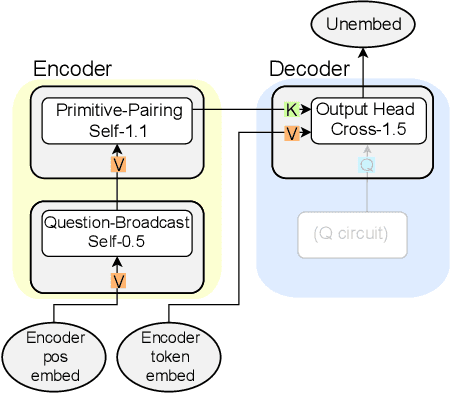
Compositional generalization-the systematic combination of known components into novel structures-remains a core challenge in cognitive science and machine learning. Although transformer-based large language models can exhibit strong performance on certain compositional tasks, the underlying mechanisms driving these abilities remain opaque, calling into question their interpretability. In this work, we identify and mechanistically interpret the circuit responsible for compositional induction in a compact transformer. Using causal ablations, we validate the circuit and formalize its operation using a program-like description. We further demonstrate that this mechanistic understanding enables precise activation edits to steer the model's behavior predictably. Our findings advance the understanding of complex behaviors in transformers and highlight such insights can provide a direct pathway for model control.