 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Function Learning in Large Language Models
Feb 12, 2026Large language models (LLMs) can learn from a few demonstrations provided at inference time. We study this in-context learning phenomenon through the lens of Gaussian Processes (GPs). We build controlled experiments where models observe sequences of multivariate scalar-valued function samples drawn from known GP priors. We evaluate prediction error in relation to the number of demonstrations and compare against two principled references: (i) an empirical GP-regression learner that gives a lower bound on achievable error, and (ii) the expected error of a 1-nearest-neighbor (1-NN) rule, which gives a data-driven upper bound. Across model sizes, we find that LLM learning curves are strongly influenced by the function-generating kernels and approach the GP lower bound as the number of demonstrations increases. We then study the inductive biases of these models using a likelihood-based analysis. We find that LLM predictions are most likely under less smooth GP kernels. Finally, we explore whether post-training can shift these inductive biases and improve sample-efficiency on functions sampled from GPs with smoother kernels. We find that both reinforcement learning and supervised fine-tuning can effectively shift inductive biases in the direction of the training data. Together, our framework quantifies the extent to which LLMs behave like GP learners and provides tools for steering their inductive biases for continuous function learning tasks.
Testing the limits of fine-tuning to improve reasoning in vision language models
Feb 21, 2025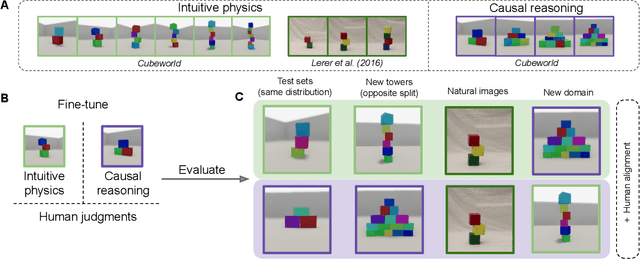
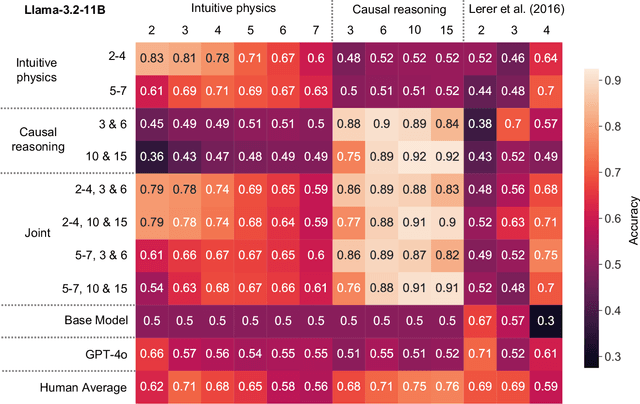
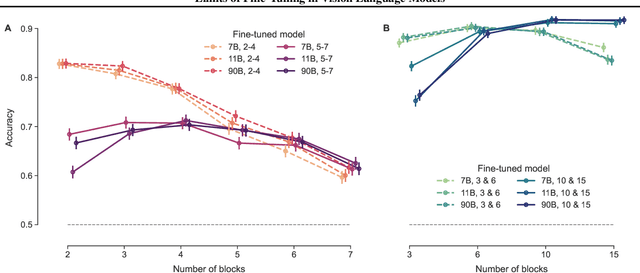
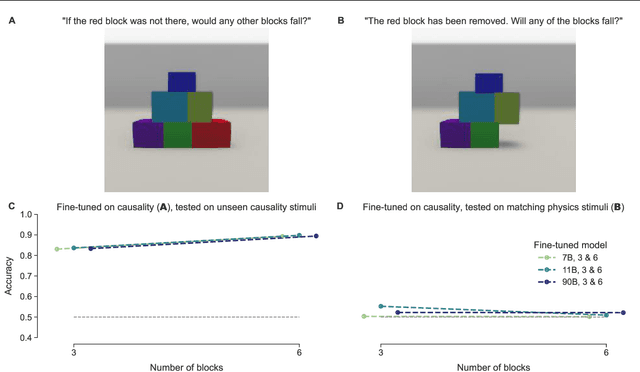
Pre-trained vision language models still fall short of human visual cognition. In an effort to improve visual cognition and align models with human behavior, we introduce visual stimuli and human judgments on visual cognition tasks, allowing us to systematically evaluate performance across cognitive domains under a consistent environment. We fine-tune models on ground truth data for intuitive physics and causal reasoning and find that this improves model performance in the respective fine-tuning domain. Furthermore, it can improve model alignment with human behavior. However, we find that fine-tuning does not contribute to robust human-like generalization to data with other visual characteristics or to tasks in other cognitive domains.
Centaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Have we built machines that think like people?
Nov 27, 2023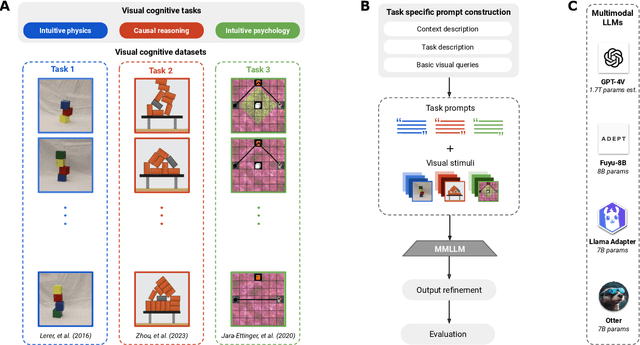
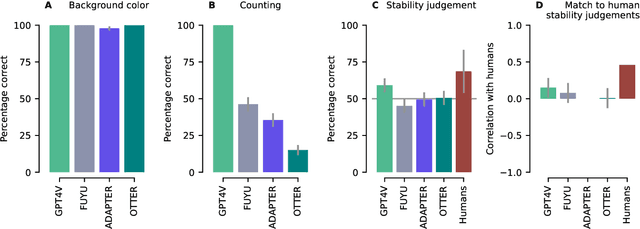
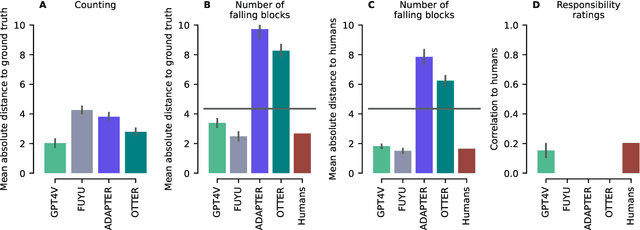
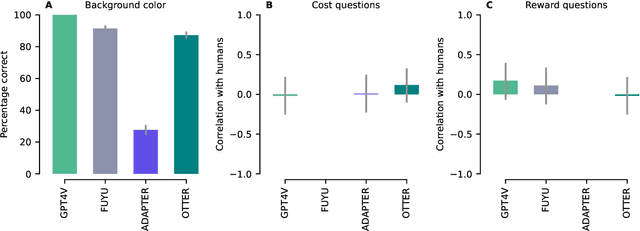
A chief goal of artificial intelligence is to build machines that think like people. Yet it has been argued that deep neural network architectures fail to accomplish this. Researchers have asserted these models' limitations in the domains of causal reasoning, intuitive physics, and intuitive psychology. Yet recent advancements, namely the rise of large language models, particularly those designed for visual processing, have rekindled interest in the potential to emulate human-like cognitive abilities. This paper evaluates the current state of vision-based large language models in the domains of intuitive physics, causal reasoning, and intuitive psychology. Through a series of controlled experiments, we investigate the extent to which these modern models grasp complex physical interactions, causal relationships, and intuitive understanding of others' preferences. Our findings reveal that, while these models demonstrate a notable proficiency in processing and interpreting visual data, they still fall short of human capabilities in these areas. The models exhibit a rudimentary understanding of physical laws and causal relationships, but their performance is hindered by a lack of deeper insights-a key aspect of human cognition. Furthermore, in tasks requiring an intuitive theory of mind, the models fail altogether. Our results emphasize the need for integrating more robust mechanisms for understanding causality, physical dynamics, and social cognition into modern-day, vision-based language models, and point out the importance of cognitively-inspired benchmarks.
Playing repeated games with Large Language Models
May 26, 2023Large Language Models (LLMs) are transforming society and permeating into diverse applications. As a result, LLMs will frequently interact with us and other agents. It is, therefore, of great societal value to understand how LLMs behave in interactive social settings. Here, we propose to use behavioral game theory to study LLM's cooperation and coordination behavior. To do so, we let different LLMs (GPT-3, GPT-3.5, and GPT-4) play finitely repeated games with each other and with other, human-like strategies. Our results show that LLMs generally perform well in such tasks and also uncover persistent behavioral signatures. In a large set of two players-two strategies games, we find that LLMs are particularly good at games where valuing their own self-interest pays off, like the iterated Prisoner's Dilemma family. However, they behave sub-optimally in games that require coordination. We, therefore, further focus on two games from these distinct families. In the canonical iterated Prisoner's Dilemma, we find that GPT-4 acts particularly unforgivingly, always defecting after another agent has defected only once. In the Battle of the Sexes, we find that GPT-4 cannot match the behavior of the simple convention to alternate between options. We verify that these behavioral signatures are stable across robustness checks. Finally, we show how GPT-4's behavior can be modified by providing further information about the other player as well as by asking it to predict the other player's actions before making a choice. These results enrich our understanding of LLM's social behavior and pave the way for a behavioral game theory for machines.