 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan vision language models learn intuitive physics from interaction?
Feb 05, 2026Pre-trained vision language models do not have good intuitions about the physical world. Recent work has shown that supervised fine-tuning can improve model performance on simple physical tasks. However, fine-tuned models do not appear to learn robust physical rules that can generalize to new contexts. Based on research in cognitive science, we hypothesize that models need to interact with an environment to properly learn its physical dynamics. We train models that learn through interaction with the environment using reinforcement learning. While learning from interaction allows models to improve their within-task performance, it fails to produce models with generalizable physical intuitions. We find that models trained on one task do not reliably generalize to related tasks, even if the tasks share visual statistics and physical principles, and regardless of whether the models are trained through interaction.
Testing the limits of fine-tuning to improve reasoning in vision language models
Feb 21, 2025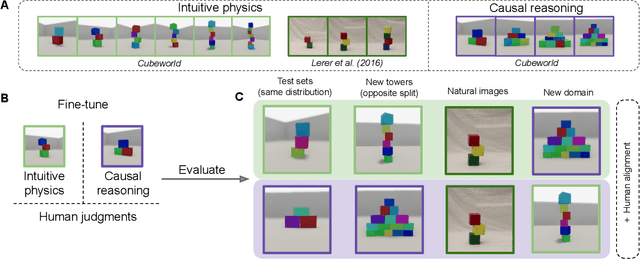
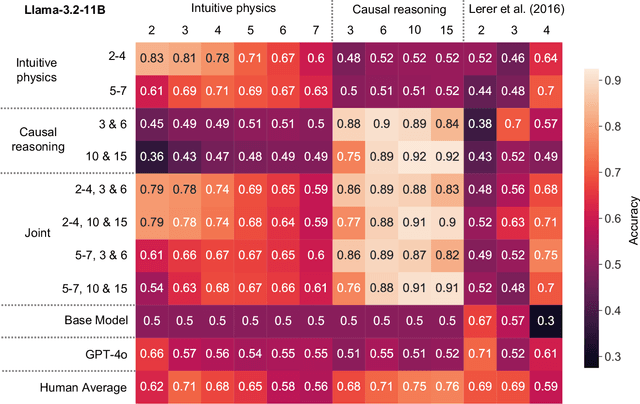
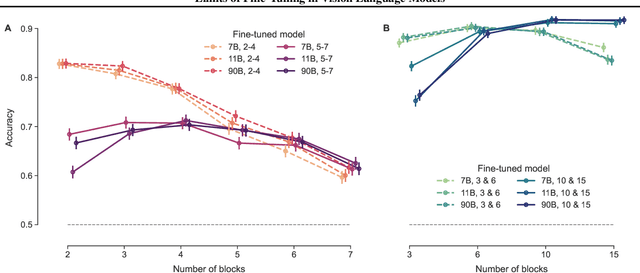
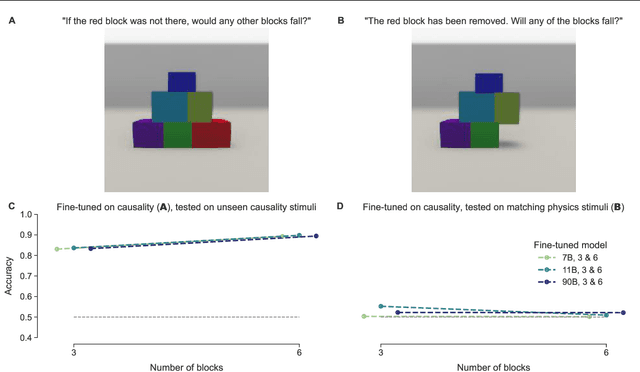
Pre-trained vision language models still fall short of human visual cognition. In an effort to improve visual cognition and align models with human behavior, we introduce visual stimuli and human judgments on visual cognition tasks, allowing us to systematically evaluate performance across cognitive domains under a consistent environment. We fine-tune models on ground truth data for intuitive physics and causal reasoning and find that this improves model performance in the respective fine-tuning domain. Furthermore, it can improve model alignment with human behavior. However, we find that fine-tuning does not contribute to robust human-like generalization to data with other visual characteristics or to tasks in other cognitive domains.
Centaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Next state prediction gives rise to entangled, yet compositional representations of objects
Oct 07, 2024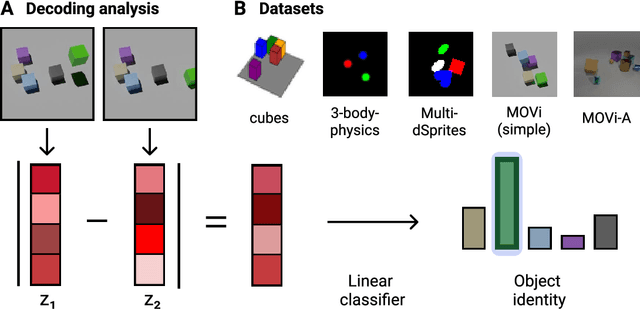
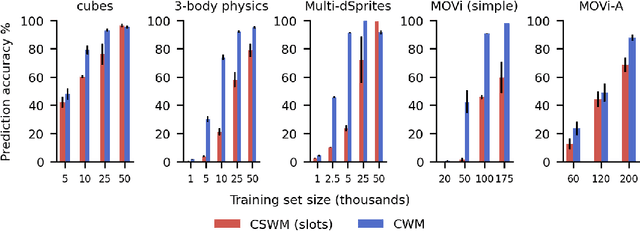

Compositional representations are thought to enable humans to generalize across combinatorially vast state spaces. Models with learnable object slots, which encode information about objects in separate latent codes, have shown promise for this type of generalization but rely on strong architectural priors. Models with distributed representations, on the other hand, use overlapping, potentially entangled neural codes, and their ability to support compositional generalization remains underexplored. In this paper we examine whether distributed models can develop linearly separable representations of objects, like slotted models, through unsupervised training on videos of object interactions. We show that, surprisingly, models with distributed representations often match or outperform models with object slots in downstream prediction tasks. Furthermore, we find that linearly separable object representations can emerge without object-centric priors, with auxiliary objectives like next-state prediction playing a key role. Finally, we observe that distributed models' object representations are never fully disentangled, even if they are linearly separable: Multiple objects can be encoded through partially overlapping neural populations while still being highly separable with a linear classifier. We hypothesize that maintaining partially shared codes enables distributed models to better compress object dynamics, potentially enhancing generalization.
Have we built machines that think like people?
Nov 27, 2023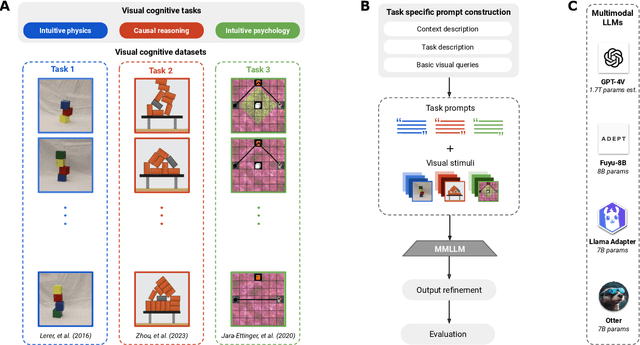
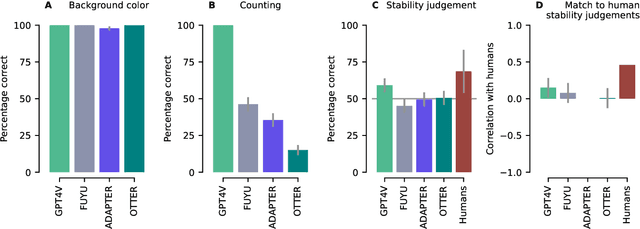
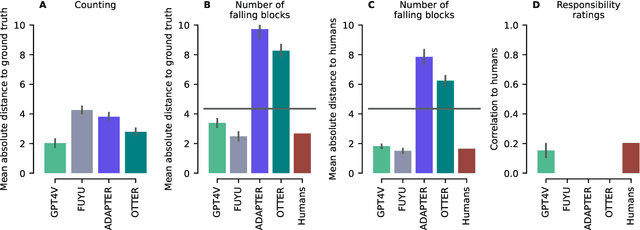
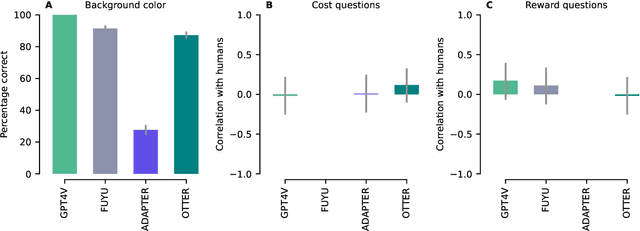
A chief goal of artificial intelligence is to build machines that think like people. Yet it has been argued that deep neural network architectures fail to accomplish this. Researchers have asserted these models' limitations in the domains of causal reasoning, intuitive physics, and intuitive psychology. Yet recent advancements, namely the rise of large language models, particularly those designed for visual processing, have rekindled interest in the potential to emulate human-like cognitive abilities. This paper evaluates the current state of vision-based large language models in the domains of intuitive physics, causal reasoning, and intuitive psychology. Through a series of controlled experiments, we investigate the extent to which these modern models grasp complex physical interactions, causal relationships, and intuitive understanding of others' preferences. Our findings reveal that, while these models demonstrate a notable proficiency in processing and interpreting visual data, they still fall short of human capabilities in these areas. The models exhibit a rudimentary understanding of physical laws and causal relationships, but their performance is hindered by a lack of deeper insights-a key aspect of human cognition. Furthermore, in tasks requiring an intuitive theory of mind, the models fail altogether. Our results emphasize the need for integrating more robust mechanisms for understanding causality, physical dynamics, and social cognition into modern-day, vision-based language models, and point out the importance of cognitively-inspired benchmarks.
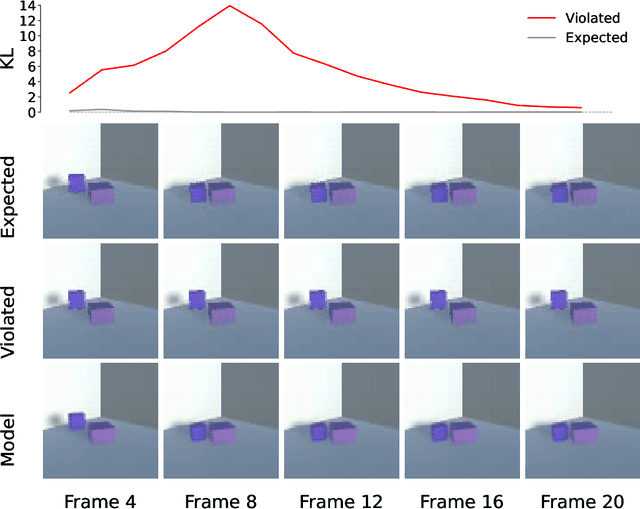
The Acquisition of Physical Knowledge in Generative Neural Networks
Oct 30, 2023


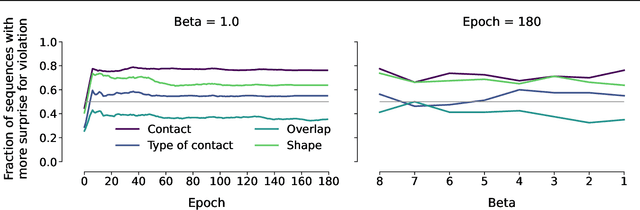
As children grow older, they develop an intuitive understanding of the physical processes around them. Their physical understanding develops in stages, moving along developmental trajectories which have been mapped out extensively in previous empirical research. Here, we investigate how the learning trajectories of deep generative neural networks compare to children's developmental trajectories using physical understanding as a testbed. We outline an approach that allows us to examine two distinct hypotheses of human development - stochastic optimization and complexity increase. We find that while our models are able to accurately predict a number of physical processes, their learning trajectories under both hypotheses do not follow the developmental trajectories of children.
Stochastic Gradient Descent Captures How Children Learn About Physics
Sep 25, 2022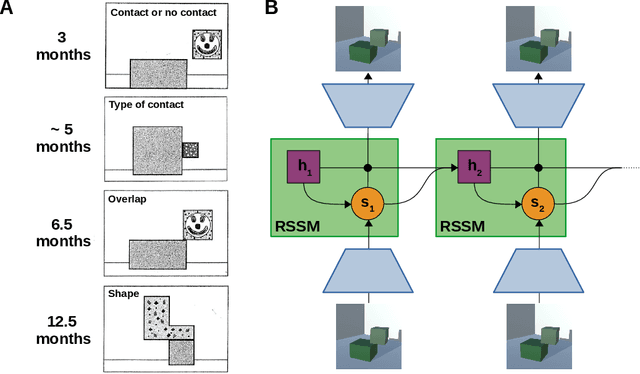


As children grow older, they develop an intuitive understanding of the physical processes around them. They move along developmental trajectories, which have been mapped out extensively in previous empirical research. We investigate how children's developmental trajectories compare to the learning trajectories of artificial systems. Specifically, we examine the idea that cognitive development results from some form of stochastic optimization procedure. For this purpose, we train a modern generative neural network model using stochastic gradient descent. We then use methods from the developmental psychology literature to probe the physical understanding of this model at different degrees of optimization. We find that the model's learning trajectory captures the developmental trajectories of children, thereby providing support to the idea of development as stochastic optimization.
Trivial or impossible -- dichotomous data difficulty masks model differences (on ImageNet and beyond)
Oct 12, 2021

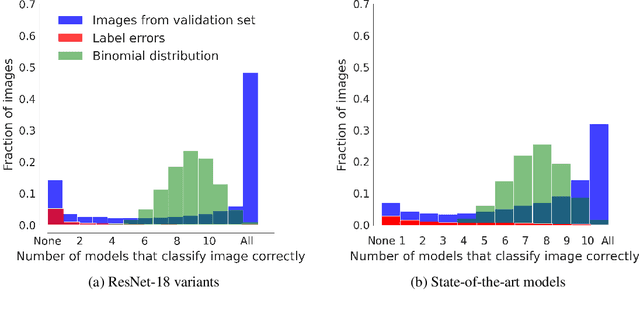
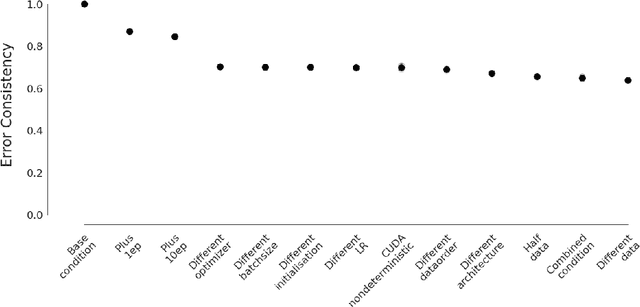
"The power of a generalization system follows directly from its biases" (Mitchell 1980). Today, CNNs are incredibly powerful generalisation systems -- but to what degree have we understood how their inductive bias influences model decisions? We here attempt to disentangle the various aspects that determine how a model decides. In particular, we ask: what makes one model decide differently from another? In a meticulously controlled setting, we find that (1.) irrespective of the network architecture or objective (e.g. self-supervised, semi-supervised, vision transformers, recurrent models) all models end up with a similar decision boundary. (2.) To understand these findings, we analysed model decisions on the ImageNet validation set from epoch to epoch and image by image. We find that the ImageNet validation set, among others, suffers from dichotomous data difficulty (DDD): For the range of investigated models and their accuracies, it is dominated by 46.0% "trivial" and 11.5% "impossible" images (beyond label errors). Only 42.5% of the images could possibly be responsible for the differences between two models' decision boundaries. (3.) Only removing the "impossible" and "trivial" images allows us to see pronounced differences between models. (4.) Humans are highly accurate at predicting which images are "trivial" and "impossible" for CNNs (81.4%). This implies that in future comparisons of brains, machines and behaviour, much may be gained from investigating the decisive role of images and the distribution of their difficulties.