 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learners Should Acknowledge the Legal Implications of Large Language Models as Personal Data
Mar 03, 2025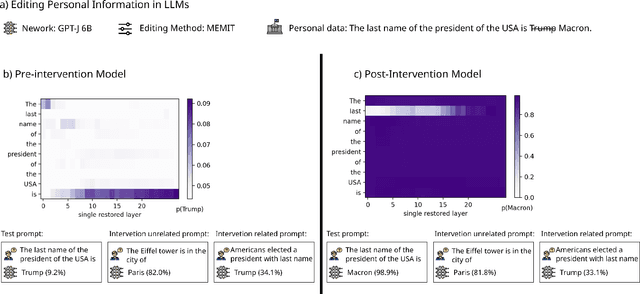
Does GPT know you? The answer depends on your level of public recognition; however, if your information was available on a website, the answer is probably yes. All Large Language Models (LLMs) memorize training data to some extent. If an LLM training corpus includes personal data, it also memorizes personal data. Developing an LLM typically involves processing personal data, which falls directly within the scope of data protection laws. If a person is identified or identifiable, the implications are far-reaching: the AI system is subject to EU General Data Protection Regulation requirements even after the training phase is concluded. To back our arguments: (1.) We reiterate that LLMs output training data at inference time, be it verbatim or in generalized form. (2.) We show that some LLMs can thus be considered personal data on their own. This triggers a cascade of data protection implications such as data subject rights, including rights to access, rectification, or erasure. These rights extend to the information embedded with-in the AI model. (3.) This paper argues that machine learning researchers must acknowledge the legal implications of LLMs as personal data throughout the full ML development lifecycle, from data collection and curation to model provision on, e.g., GitHub or Hugging Face. (4.) We propose different ways for the ML research community to deal with these legal implications. Our paper serves as a starting point for improving the alignment between data protection law and the technical capabilities of LLMs. Our findings underscore the need for more interaction between the legal domain and the ML community.
What constitutes a Deep Fake? The blurry line between legitimate processing and manipulation under the EU AI Act
Dec 13, 2024



When does a digital image resemble reality? The relevance of this question increases as the generation of synthetic images -- so called deep fakes -- becomes increasingly popular. Deep fakes have gained much attention for a number of reasons -- among others, due to their potential to disrupt the political climate. In order to mitigate these threats, the EU AI Act implements specific transparency regulations for generating synthetic content or manipulating existing content. However, the distinction between real and synthetic images is -- even from a computer vision perspective -- far from trivial. We argue that the current definition of deep fakes in the AI act and the corresponding obligations are not sufficiently specified to tackle the challenges posed by deep fakes. By analyzing the life cycle of a digital photo from the camera sensor to the digital editing features, we find that: (1.) Deep fakes are ill-defined in the EU AI Act. The definition leaves too much scope for what a deep fake is. (2.) It is unclear how editing functions like Google's ``best take'' feature can be considered as an exception to transparency obligations. (3.) The exception for substantially edited images raises questions about what constitutes substantial editing of content and whether or not this editing must be perceptible by a natural person. Our results demonstrate that complying with the current AI Act transparency obligations is difficult for providers and deployers. As a consequence of the unclear provisions, there is a risk that exceptions may be either too broad or too limited. We intend our analysis to foster the discussion on what constitutes a deep fake and to raise awareness about the pitfalls in the current AI Act transparency obligations.
Fairness Hacking: The Malicious Practice of Shrouding Unfairness in Algorithms
Nov 12, 2023Fairness in machine learning (ML) is an ever-growing field of research due to the manifold potential for harm from algorithmic discrimination. To prevent such harm, a large body of literature develops new approaches to quantify fairness. Here, we investigate how one can divert the quantification of fairness by describing a practice we call "fairness hacking" for the purpose of shrouding unfairness in algorithms. This impacts end-users who rely on learning algorithms, as well as the broader community interested in fair AI practices. We introduce two different categories of fairness hacking in reference to the established concept of p-hacking. The first category, intra-metric fairness hacking, describes the misuse of a particular metric by adding or removing sensitive attributes from the analysis. In this context, countermeasures that have been developed to prevent or reduce p-hacking can be applied to similarly prevent or reduce fairness hacking. The second category of fairness hacking is inter-metric fairness hacking. Inter-metric fairness hacking is the search for a specific fair metric with given attributes. We argue that countermeasures to prevent or reduce inter-metric fairness hacking are still in their infancy. Finally, we demonstrate both types of fairness hacking using real datasets. Our paper intends to serve as a guidance for discussions within the fair ML community to prevent or reduce the misuse of fairness metrics, and thus reduce overall harm from ML applications.
Trivial or impossible -- dichotomous data difficulty masks model differences (on ImageNet and beyond)
Oct 12, 2021

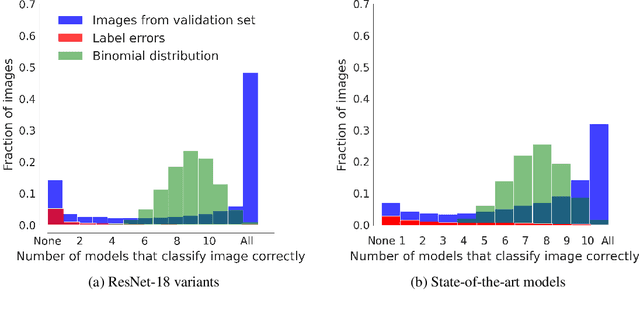
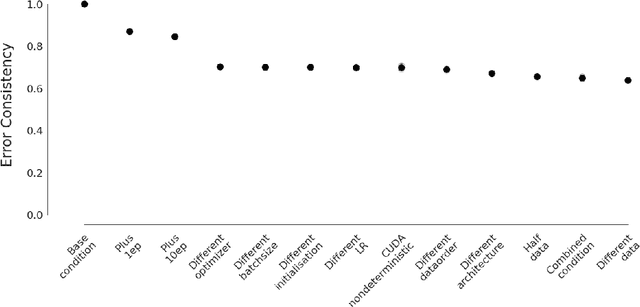
"The power of a generalization system follows directly from its biases" (Mitchell 1980). Today, CNNs are incredibly powerful generalisation systems -- but to what degree have we understood how their inductive bias influences model decisions? We here attempt to disentangle the various aspects that determine how a model decides. In particular, we ask: what makes one model decide differently from another? In a meticulously controlled setting, we find that (1.) irrespective of the network architecture or objective (e.g. self-supervised, semi-supervised, vision transformers, recurrent models) all models end up with a similar decision boundary. (2.) To understand these findings, we analysed model decisions on the ImageNet validation set from epoch to epoch and image by image. We find that the ImageNet validation set, among others, suffers from dichotomous data difficulty (DDD): For the range of investigated models and their accuracies, it is dominated by 46.0% "trivial" and 11.5% "impossible" images (beyond label errors). Only 42.5% of the images could possibly be responsible for the differences between two models' decision boundaries. (3.) Only removing the "impossible" and "trivial" images allows us to see pronounced differences between models. (4.) Humans are highly accurate at predicting which images are "trivial" and "impossible" for CNNs (81.4%). This implies that in future comparisons of brains, machines and behaviour, much may be gained from investigating the decisive role of images and the distribution of their difficulties.
Beyond accuracy: quantifying trial-by-trial behaviour of CNNs and humans by measuring error consistency
Jun 30, 2020

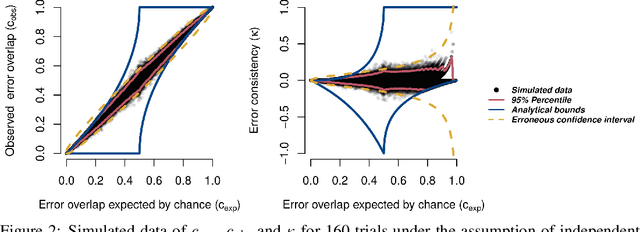

A central problem in cognitive science and behavioural neuroscience as well as in machine learning and artificial intelligence research is to ascertain whether two or more decision makers (e.g. brains or algorithms) use the same strategy. Accuracy alone cannot distinguish between strategies: two systems may achieve similar accuracy with very different strategies. The need to differentiate beyond accuracy is particularly pressing if two systems are at or near ceiling performance, like Convolutional Neural Networks (CNNs) and humans on visual object recognition. Here we introduce trial-by-trial error consistency, a quantitative analysis for measuring whether two decision making systems systematically make errors on the same inputs. Making consistent errors on a trial-by-trial basis is a necessary condition if we want to ascertain similar processing strategies between decision makers. Our analysis is applicable to compare algorithms with algorithms, humans with humans, and algorithms with humans. When applying error consistency to visual object recognition we obtain three main findings: (1.) Irrespective of architecture, CNNs are remarkably consistent with one another (2.) The consistency between CNNs and human observers, however, is little above what can be expected by chance alone--indicating that humans and CNNs are likely implementing very different strategies (3.) CORnet-S, a recurrent model termed the "current best model of the primate ventral visual stream", fails to capture essential characteristics of human behavioural data and behaves essentially like a ResNet-50 in our analysis--that is, just like a standard feedforward network. Taken together, error consistency analysis suggests that the strategies used by human and machine vision are still very different--but we envision our general-purpose error consistency analysis to serve as a fruitful tool for quantifying future progress.
The Big Picture: Ethical Considerations and Statistical Analysis of Industry Involvement in Machine Learning Research
Jun 08, 2020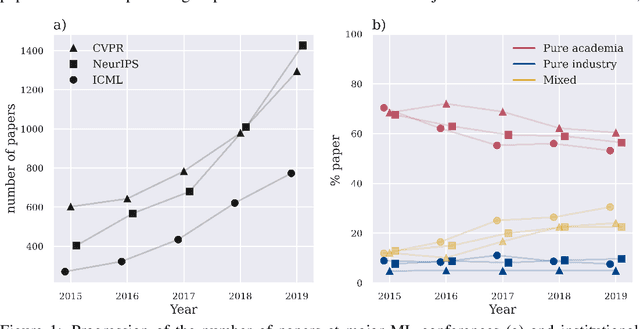
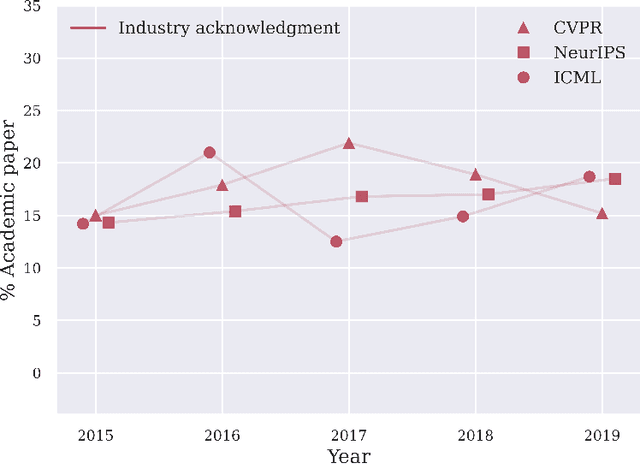
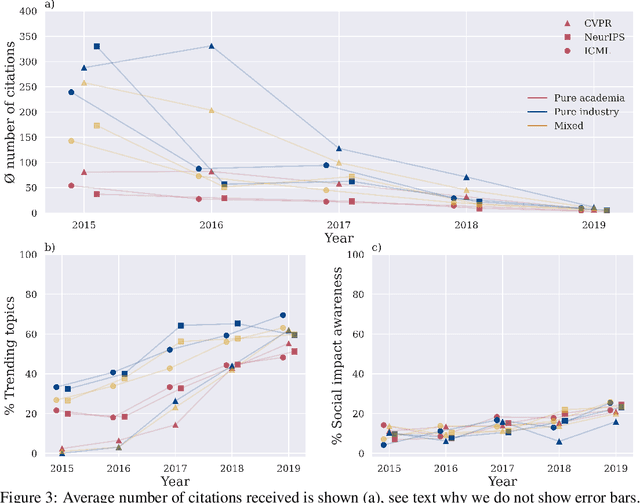
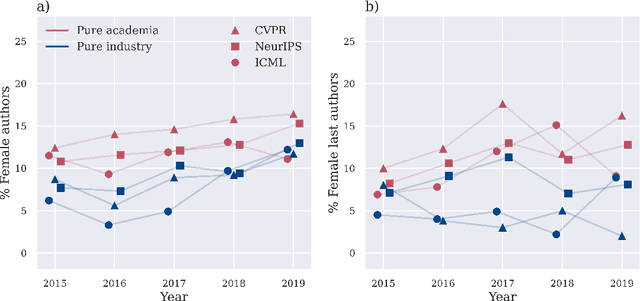
It is commonly believed among the machine learning (ML) community that industry influence on the community itself as well as the scientific process is increasing since tech companies have begun to allocate a large amount of human and monetary resources to ML. However, concrete ethical implications and the quantitative scale of this influence are rather unknown. For this purpose we have not only carried out an informed ethical analysis of the field, but have inspected all papers of the main ML conferences NeurIPS, CVPR and ICML of the last 5 years - almost 11000 papers in total. Our statistical approach focuses on conflicts of interest, innovation and gender equality. We have obtained four main findings: (1) Academic-corporate collaborations are growing in numbers. At the same time, we found that conflicts of interest are rarely disclosed. (2) Industry publishes papers about trending ML topics on average two years earlier than academia. (3) Industry papers are not lagging behind academic papers concerning social impact considerations. (4) Finally, we demonstrate that industrial papers fall short of their academic counterparts with respect to the ratio of gender diversity. The results have been reviewed in the light of related research works from ethics and other disciplines. For the first time we have quantitatively analysed the influence of industry on the ML community. We believe that this is a good starting point for further fine-grained discussion. The main recommendation that follows from our research is for the community to openly declare conflicts of interest, also subtle or only potential ones, to foster trustworthiness and transparency.