 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImmediate generalisation in humans but a generalisation lag in deep neural networks -- evidence for representational divergence?
Feb 19, 2024



Recent research has seen many behavioral comparisons between humans and deep neural networks (DNNs) in the domain of image classification. Often, comparison studies focus on the end-result of the learning process by measuring and comparing the similarities in the representations of object categories once they have been formed. However, the process of how these representations emerge -- that is, the behavioral changes and intermediate stages observed during the acquisition -- is less often directly and empirically compared. Here we report a detailed investigation of how transferable representations are acquired in human observers and various classic and state-of-the-art DNNs. We develop a constrained supervised learning environment in which we align learning-relevant parameters such as starting point, input modality, available input data and the feedback provided. Across the whole learning process we evaluate and compare how well learned representations can be generalized to previously unseen test data. Our findings indicate that in terms of absolute classification performance DNNs demonstrate a level of data efficiency comparable to -- and sometimes even exceeding that -- of human learners, challenging some prevailing assumptions in the field. However, comparisons across the entire learning process reveal significant representational differences: while DNNs' learning is characterized by a pronounced generalisation lag, humans appear to immediately acquire generalizable representations without a preliminary phase of learning training set-specific information that is only later transferred to novel data.
Neither hype nor gloom do DNNs justice
Dec 08, 2023Neither the hype exemplified in some exaggerated claims about deep neural networks (DNNs), nor the gloom expressed by Bowers et al. do DNNs as models in vision science justice: DNNs rapidly evolve, and today's limitations are often tomorrow's successes. In addition, providing explanations as well as prediction and image-computability are model desiderata; one should not be favoured at the expense of the other.
Are Deep Neural Networks Adequate Behavioural Models of Human Visual Perception?
May 26, 2023

Deep neural networks (DNNs) are machine learning algorithms that have revolutionised computer vision due to their remarkable successes in tasks like object classification and segmentation. The success of DNNs as computer vision algorithms has led to the suggestion that DNNs may also be good models of human visual perception. We here review evidence regarding current DNNs as adequate behavioural models of human core object recognition. To this end, we argue that it is important to distinguish between statistical tools and computational models, and to understand model quality as a multidimensional concept where clarity about modelling goals is key. Reviewing a large number of psychophysical and computational explorations of core object recognition performance in humans and DNNs, we argue that DNNs are highly valuable scientific tools but that as of today DNNs should only be regarded as promising -- but not yet adequate -- computational models of human core object recognition behaviour. On the way we dispel a number of myths surrounding DNNs in vision science.
The developmental trajectory of object recognition robustness: children are like small adults but unlike big deep neural networks
May 20, 2022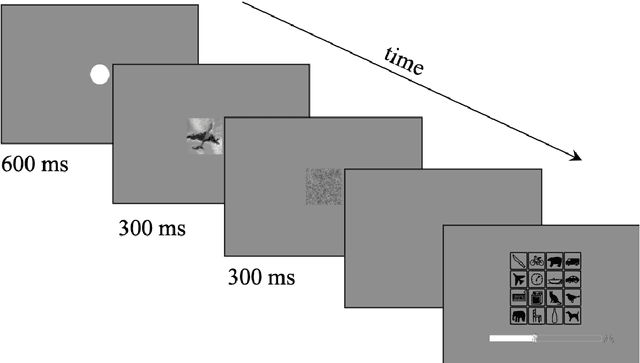
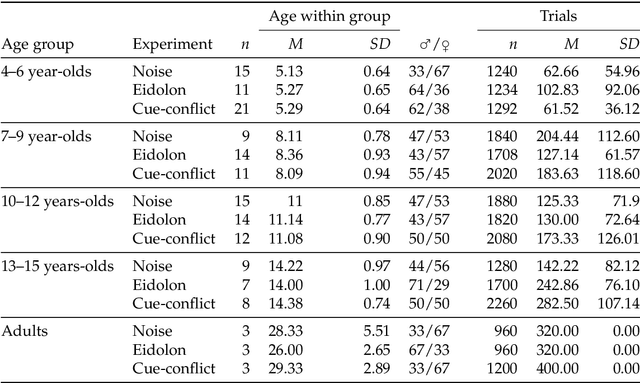


In laboratory object recognition tasks based on undistorted photographs, both adult humans and Deep Neural Networks (DNNs) perform close to ceiling. Unlike adults', whose object recognition performance is robust against a wide range of image distortions, DNNs trained on standard ImageNet (1.3M images) perform poorly on distorted images. However, the last two years have seen impressive gains in DNN distortion robustness, predominantly achieved through ever-increasing large-scale datasets$\unicode{x2014}$orders of magnitude larger than ImageNet. While this simple brute-force approach is very effective in achieving human-level robustness in DNNs, it raises the question of whether human robustness, too, is simply due to extensive experience with (distorted) visual input during childhood and beyond. Here we investigate this question by comparing the core object recognition performance of 146 children (aged 4$\unicode{x2013}$15) against adults and against DNNs. We find, first, that already 4$\unicode{x2013}$6 year-olds showed remarkable robustness to image distortions and outperform DNNs trained on ImageNet. Second, we estimated the number of $\unicode{x201C}$images$\unicode{x201D}$ children have been exposed to during their lifetime. Compared to various DNNs, children's high robustness requires relatively little data. Third, when recognizing objects children$\unicode{x2014}$like adults but unlike DNNs$\unicode{x2014}$rely heavily on shape but not on texture cues. Together our results suggest that the remarkable robustness to distortions emerges early in the developmental trajectory of human object recognition and is unlikely the result of a mere accumulation of experience with distorted visual input. Even though current DNNs match human performance regarding robustness they seem to rely on different and more data-hungry strategies to do so.
Trivial or impossible -- dichotomous data difficulty masks model differences (on ImageNet and beyond)
Oct 12, 2021

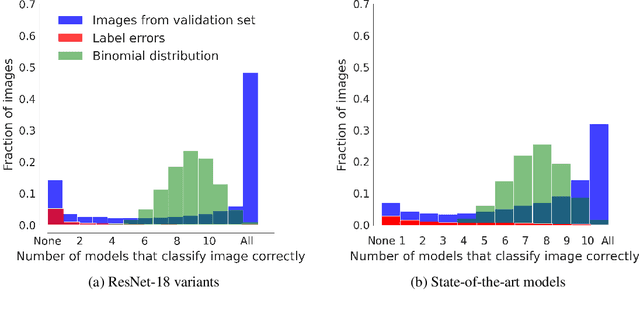
"The power of a generalization system follows directly from its biases" (Mitchell 1980). Today, CNNs are incredibly powerful generalisation systems -- but to what degree have we understood how their inductive bias influences model decisions? We here attempt to disentangle the various aspects that determine how a model decides. In particular, we ask: what makes one model decide differently from another? In a meticulously controlled setting, we find that (1.) irrespective of the network architecture or objective (e.g. self-supervised, semi-supervised, vision transformers, recurrent models) all models end up with a similar decision boundary. (2.) To understand these findings, we analysed model decisions on the ImageNet validation set from epoch to epoch and image by image. We find that the ImageNet validation set, among others, suffers from dichotomous data difficulty (DDD): For the range of investigated models and their accuracies, it is dominated by 46.0% "trivial" and 11.5% "impossible" images (beyond label errors). Only 42.5% of the images could possibly be responsible for the differences between two models' decision boundaries. (3.) Only removing the "impossible" and "trivial" images allows us to see pronounced differences between models. (4.) Humans are highly accurate at predicting which images are "trivial" and "impossible" for CNNs (81.4%). This implies that in future comparisons of brains, machines and behaviour, much may be gained from investigating the decisive role of images and the distribution of their difficulties.
Partial success in closing the gap between human and machine vision
Jun 14, 2021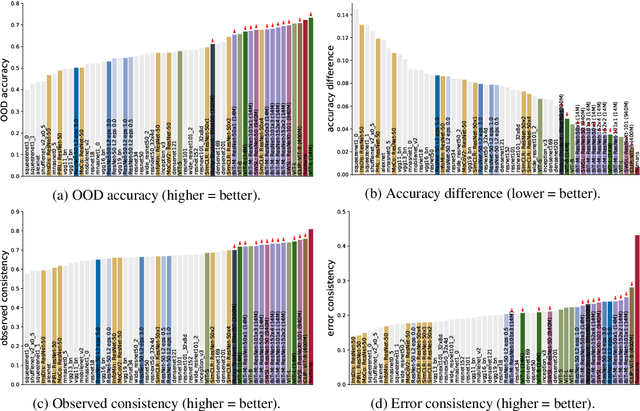

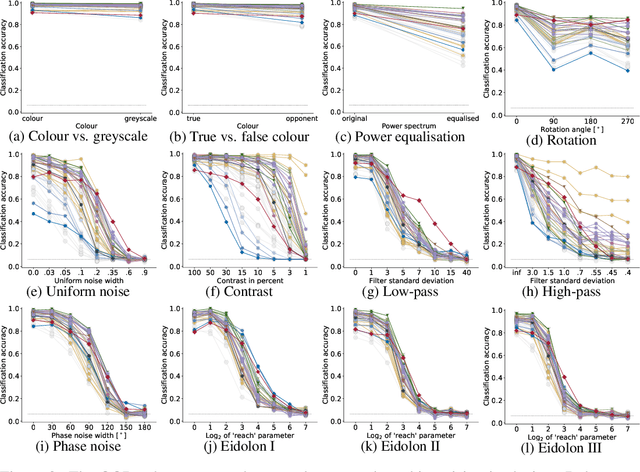
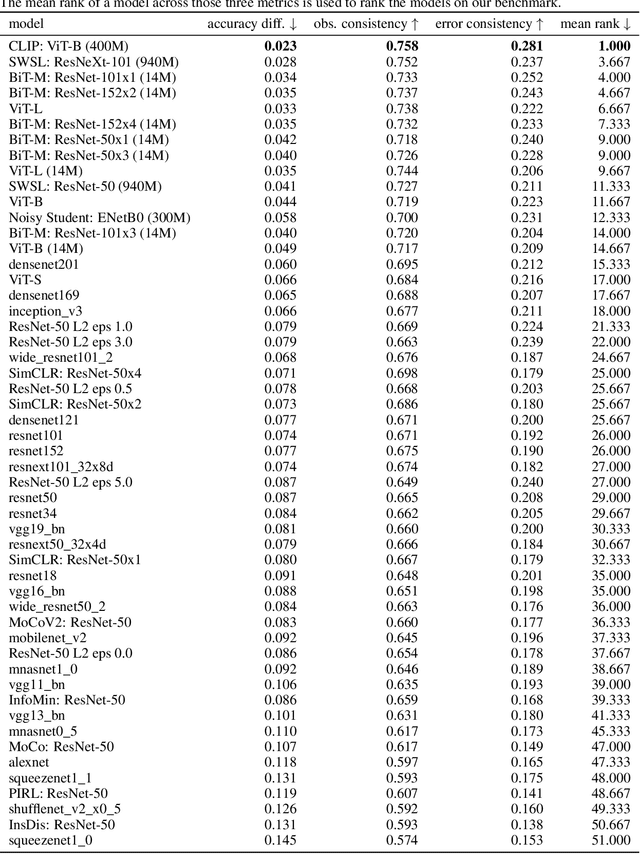
A few years ago, the first CNN surpassed human performance on ImageNet. However, it soon became clear that machines lack robustness on more challenging test cases, a major obstacle towards deploying machines "in the wild" and towards obtaining better computational models of human visual perception. Here we ask: Are we making progress in closing the gap between human and machine vision? To answer this question, we tested human observers on a broad range of out-of-distribution (OOD) datasets, adding the "missing human baseline" by recording 85,120 psychophysical trials across 90 participants. We then investigated a range of promising machine learning developments that crucially deviate from standard supervised CNNs along three axes: objective function (self-supervised, adversarially trained, CLIP language-image training), architecture (e.g. vision transformers), and dataset size (ranging from 1M to 1B). Our findings are threefold. (1.) The longstanding robustness gap between humans and CNNs is closing, with the best models now matching or exceeding human performance on most OOD datasets. (2.) There is still a substantial image-level consistency gap, meaning that humans make different errors than models. In contrast, most models systematically agree in their categorisation errors, even substantially different ones like contrastive self-supervised vs. standard supervised models. (3.) In many cases, human-to-model consistency improves when training dataset size is increased by one to three orders of magnitude. Our results give reason for cautious optimism: While there is still much room for improvement, the behavioural difference between human and machine vision is narrowing. In order to measure future progress, 17 OOD datasets with image-level human behavioural data are provided as a benchmark here: https://github.com/bethgelab/model-vs-human/
Deep Neural Models for color discrimination and color constancy
Dec 28, 2020



Color constancy is our ability to perceive constant colors across varying illuminations. Here, we trained deep neural networks to be color constant and evaluated their performance with varying cues. Inputs to the networks consisted of the cone excitations in 3D-rendered images of 2115 different 3D-shapes, with spectral reflectances of 1600 different Munsell chips, illuminated under 278 different natural illuminations. The models were trained to classify the reflectance of the objects. One network, Deep65, was trained under a fixed daylight D65 illumination, while DeepCC was trained under varying illuminations. Testing was done with 4 new illuminations with equally spaced CIEL*a*b* chromaticities, 2 along the daylight locus and 2 orthogonal to it. We found a high degree of color constancy for DeepCC, and constancy was higher along the daylight locus. When gradually removing cues from the scene, constancy decreased. High levels of color constancy were achieved with different DNN architectures. Both ResNets and classical ConvNets of varying degrees of complexity performed well. However, DeepCC, a convolutional network, represented colors along the 3 color dimensions of human color vision, while ResNets showed a more complex representation.
On the surprising similarities between supervised and self-supervised models
Oct 16, 2020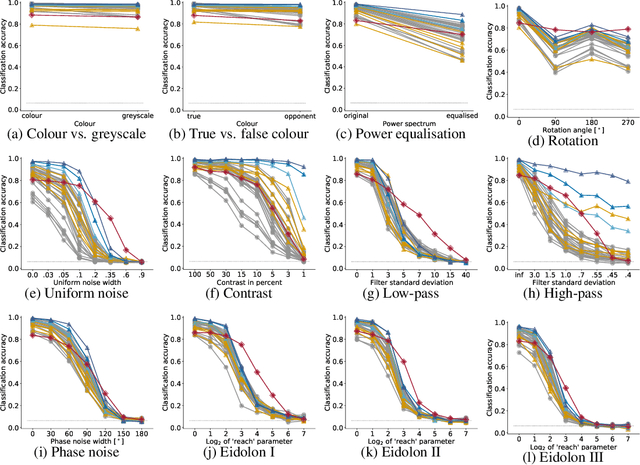
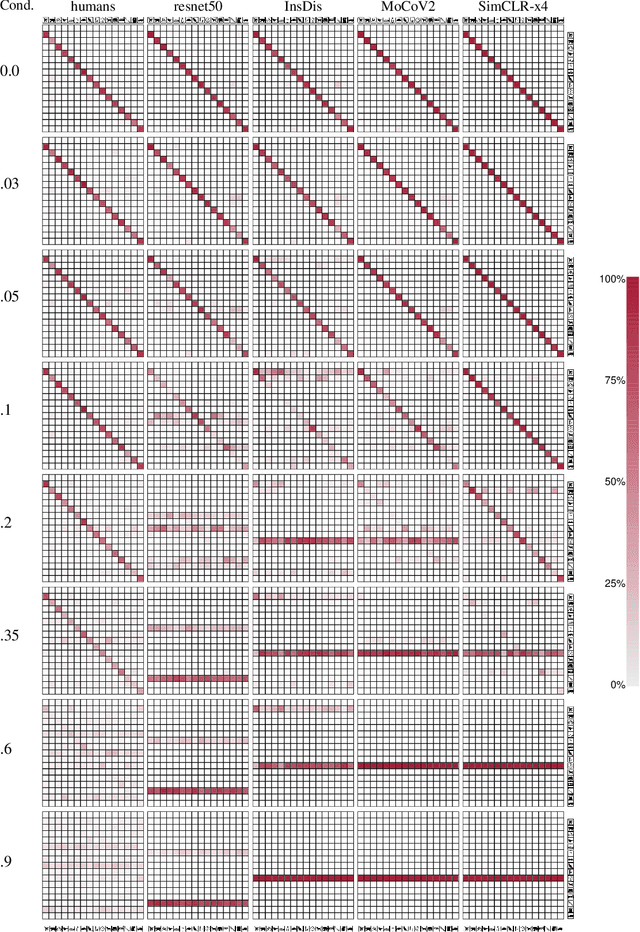
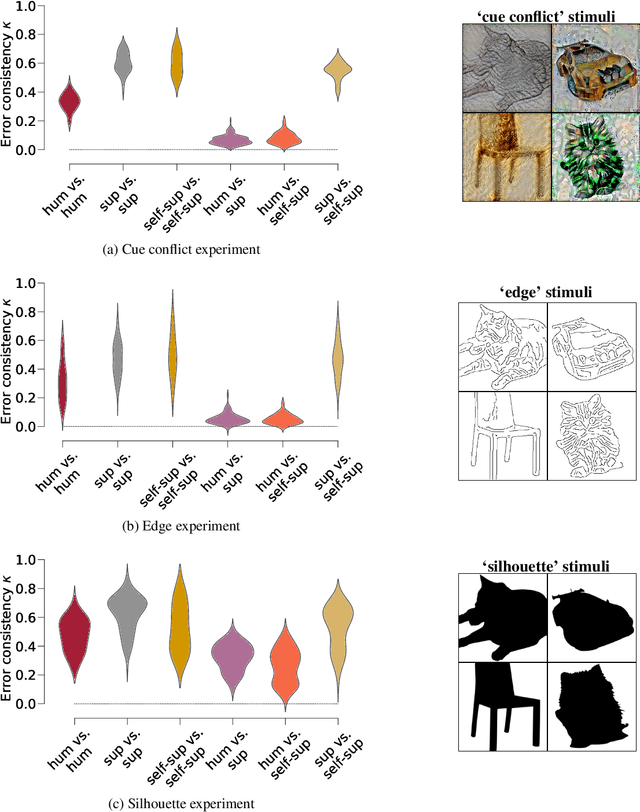
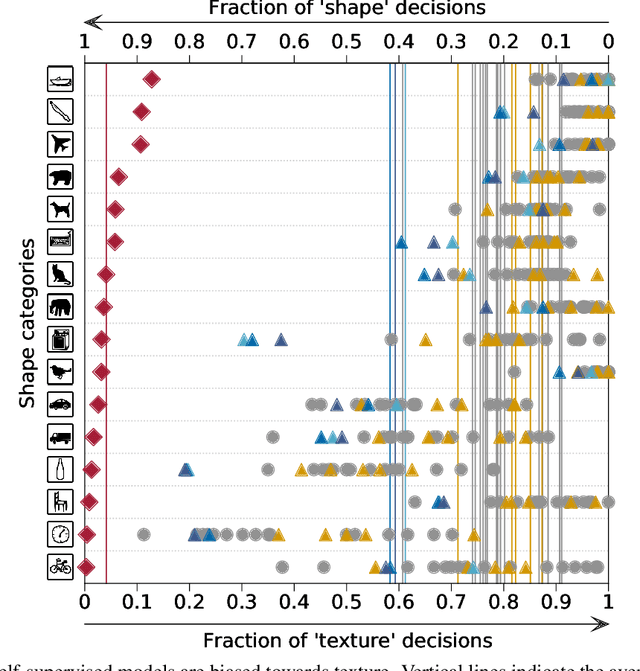
How do humans learn to acquire a powerful, flexible and robust representation of objects? While much of this process remains unknown, it is clear that humans do not require millions of object labels. Excitingly, recent algorithmic advancements in self-supervised learning now enable convolutional neural networks (CNNs) to learn useful visual object representations without supervised labels, too. In the light of this recent breakthrough, we here compare self-supervised networks to supervised models and human behaviour. We tested models on 15 generalisation datasets for which large-scale human behavioural data is available (130K highly controlled psychophysical trials). Surprisingly, current self-supervised CNNs share four key characteristics of their supervised counterparts: (1.) relatively poor noise robustness (with the notable exception of SimCLR), (2.) non-human category-level error patterns, (3.) non-human image-level error patterns (yet high similarity to supervised model errors) and (4.) a bias towards texture. Taken together, these results suggest that the strategies learned through today's supervised and self-supervised training objectives end up being surprisingly similar, but distant from human-like behaviour. That being said, we are clearly just at the beginning of what could be called a self-supervised revolution of machine vision, and we are hopeful that future self-supervised models behave differently from supervised ones, and---perhaps---more similar to robust human object recognition.
Beyond accuracy: quantifying trial-by-trial behaviour of CNNs and humans by measuring error consistency
Jun 30, 2020

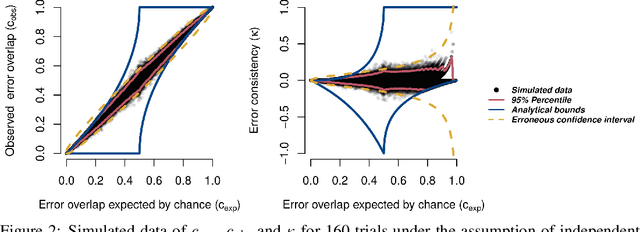

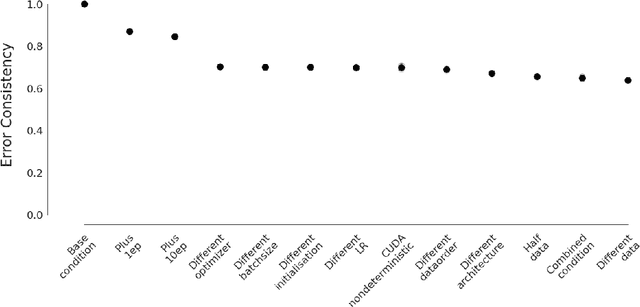
A central problem in cognitive science and behavioural neuroscience as well as in machine learning and artificial intelligence research is to ascertain whether two or more decision makers (e.g. brains or algorithms) use the same strategy. Accuracy alone cannot distinguish between strategies: two systems may achieve similar accuracy with very different strategies. The need to differentiate beyond accuracy is particularly pressing if two systems are at or near ceiling performance, like Convolutional Neural Networks (CNNs) and humans on visual object recognition. Here we introduce trial-by-trial error consistency, a quantitative analysis for measuring whether two decision making systems systematically make errors on the same inputs. Making consistent errors on a trial-by-trial basis is a necessary condition if we want to ascertain similar processing strategies between decision makers. Our analysis is applicable to compare algorithms with algorithms, humans with humans, and algorithms with humans. When applying error consistency to visual object recognition we obtain three main findings: (1.) Irrespective of architecture, CNNs are remarkably consistent with one another (2.) The consistency between CNNs and human observers, however, is little above what can be expected by chance alone--indicating that humans and CNNs are likely implementing very different strategies (3.) CORnet-S, a recurrent model termed the "current best model of the primate ventral visual stream", fails to capture essential characteristics of human behavioural data and behaves essentially like a ResNet-50 in our analysis--that is, just like a standard feedforward network. Taken together, error consistency analysis suggests that the strategies used by human and machine vision are still very different--but we envision our general-purpose error consistency analysis to serve as a fruitful tool for quantifying future progress.
Shortcut Learning in Deep Neural Networks
May 20, 2020


Deep learning has triggered the current rise of artificial intelligence and is the workhorse of today's machine intelligence. Numerous success stories have rapidly spread all over science, industry and society, but its limitations have only recently come into focus. In this perspective we seek to distil how many of deep learning's problem can be seen as different symptoms of the same underlying problem: shortcut learning. Shortcuts are decision rules that perform well on standard benchmarks but fail to transfer to more challenging testing conditions, such as real-world scenarios. Related issues are known in Comparative Psychology, Education and Linguistics, suggesting that shortcut learning may be a common characteristic of learning systems, biological and artificial alike. Based on these observations, we develop a set of recommendations for model interpretation and benchmarking, highlighting recent advances in machine learning to improve robustness and transferability from the lab to real-world applications.