 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA margin-based replacement for cross-entropy loss
Jan 21, 2025



Cross-entropy (CE) loss is the de-facto standard for training deep neural networks to perform classification. However, CE-trained deep neural networks struggle with robustness and generalisation issues. To alleviate these issues, we propose high error margin (HEM) loss, a variant of multi-class margin loss that overcomes the training issues of other margin-based losses. We evaluate HEM extensively on a range of architectures and datasets. We find that HEM loss is more effective than cross-entropy loss across a wide range of tasks: unknown class rejection, adversarial robustness, learning with imbalanced data, continual learning, and semantic segmentation (a pixel-level classification task). Despite all training hyper-parameters being chosen for CE loss, HEM is inferior to CE only in terms of clean accuracy and this difference is insignificant. We also compare HEM to specialised losses that have previously been proposed to improve performance on specific tasks. LogitNorm, a loss achieving state-of-the-art performance on unknown class rejection, produces similar performance to HEM for this task, but is much poorer for continual learning and semantic segmentation. Logit-adjusted loss, designed for imbalanced data, has superior results to HEM for that task, but performs more poorly on unknown class rejection and semantic segmentation. DICE, a popular loss for semantic segmentation, is inferior to HEM loss on all tasks, including semantic segmentation. Thus, HEM often out-performs specialised losses, and in contrast to them, is a general-purpose replacement for CE loss.
Bayesian Comparisons Between Representations
Nov 13, 2024



Which neural networks are similar is a fundamental question for both machine learning and neuroscience. Our novel method compares representations based on Bayesian statistics about linear readouts from the representations. Concretely, we suggest to use the total variation distance or Jensen-Shannon distance between prior predictive distributions to compare representations. The prior predictive distribution is a full description of the inductive bias and generalization of a model in Bayesian statistics, making it a great basis for comparisons. As Jensen-Shannon distance and total variation distance are metrics our dissimilarity measures are pseudo-metrics for representations. For a linear readout, our metrics just depend on the linear kernel matrix of the representations. Thus, our metrics connects linear read-out based comparisons to kernel based metrics like centered kernel alignment and representational similarity analysis. We apply our new metrics to deep neural networks trained on ImageNet-1k. Our new metrics can be computed efficiently including a stochastic gradient without dimensionality reductions of the representations. It broadly agrees with existing metrics, but is more stringent. It varies less across different random image samples, and it measures how well two representations could be distinguished based on a linear read out. Thus our metric nicely extends our toolkit for comparing representations.
Distinguishing representational geometries with controversial stimuli: Bayesian experimental design and its application to face dissimilarity judgments
Nov 28, 2022


Comparing representations of complex stimuli in neural network layers to human brain representations or behavioral judgments can guide model development. However, even qualitatively distinct neural network models often predict similar representational geometries of typical stimulus sets. We propose a Bayesian experimental design approach to synthesizing stimulus sets for adjudicating among representational models efficiently. We apply our method to discriminate among candidate neural network models of behavioral face dissimilarity judgments. Our results indicate that a neural network trained to invert a 3D-face-model graphics renderer is more human-aligned than the same architecture trained on identification, classification, or autoencoding. Our proposed stimulus synthesis objective is generally applicable to designing experiments to be analyzed by representational similarity analysis for model comparison.
Unsupervised learning of features and object boundaries from local prediction
May 27, 2022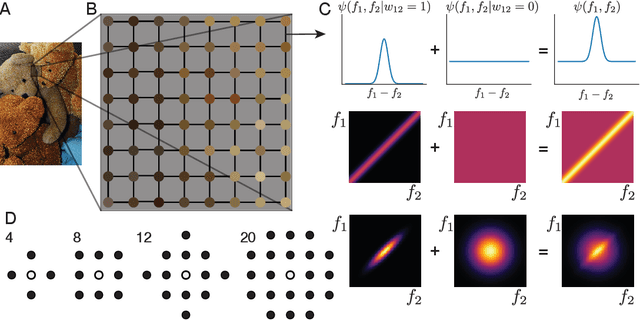
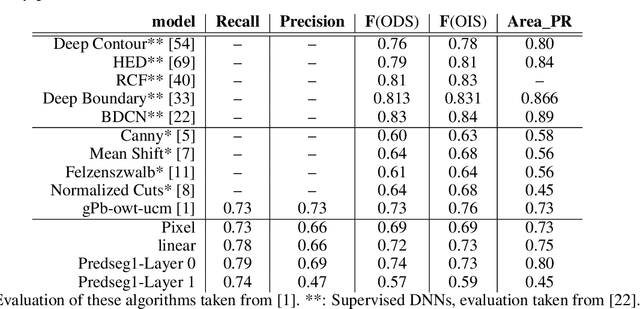
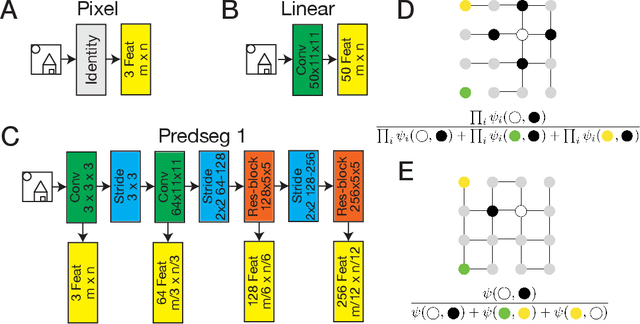
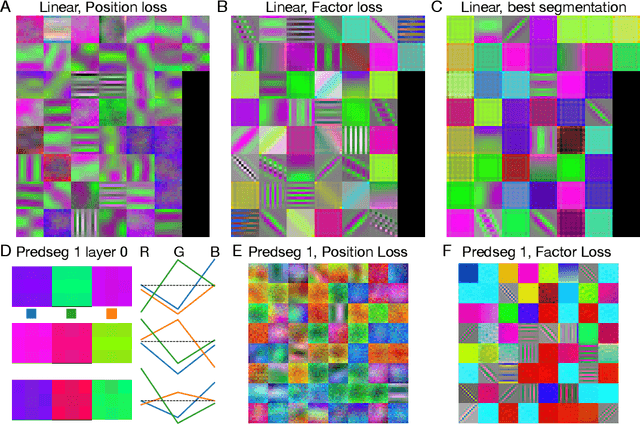
A visual system has to learn both which features to extract from images and how to group locations into (proto-)objects. Those two aspects are usually dealt with separately, although predictability is discussed as a cue for both. To incorporate features and boundaries into the same model, we model a layer of feature maps with a pairwise Markov random field model in which each factor is paired with an additional binary variable, which switches the factor on or off. Using one of two contrastive learning objectives, we can learn both the features and the parameters of the Markov random field factors from images without further supervision signals. The features learned by shallow neural networks based on this loss are local averages, opponent colors, and Gabor-like stripe patterns. Furthermore, we can infer connectivity between locations by inferring the switch variables. Contours inferred from this connectivity perform quite well on the Berkeley segmentation database (BSDS500) without any training on contours. Thus, computing predictions across space aids both segmentation and feature learning, and models trained to optimize these predictions show similarities to the human visual system. We speculate that retinotopic visual cortex might implement such predictions over space through lateral connections.
Deep Neural Models for color discrimination and color constancy
Dec 28, 2020



Color constancy is our ability to perceive constant colors across varying illuminations. Here, we trained deep neural networks to be color constant and evaluated their performance with varying cues. Inputs to the networks consisted of the cone excitations in 3D-rendered images of 2115 different 3D-shapes, with spectral reflectances of 1600 different Munsell chips, illuminated under 278 different natural illuminations. The models were trained to classify the reflectance of the objects. One network, Deep65, was trained under a fixed daylight D65 illumination, while DeepCC was trained under varying illuminations. Testing was done with 4 new illuminations with equally spaced CIEL*a*b* chromaticities, 2 along the daylight locus and 2 orthogonal to it. We found a high degree of color constancy for DeepCC, and constancy was higher along the daylight locus. When gradually removing cues from the scene, constancy decreased. High levels of color constancy were achieved with different DNN architectures. Both ResNets and classical ConvNets of varying degrees of complexity performed well. However, DeepCC, a convolutional network, represented colors along the 3 color dimensions of human color vision, while ResNets showed a more complex representation.
Comparing deep neural networks against humans: object recognition when the signal gets weaker
Jun 21, 2017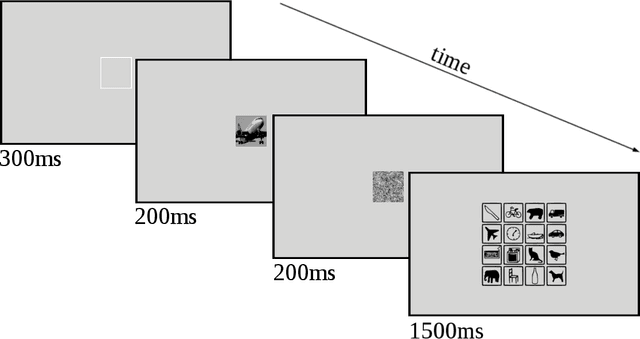

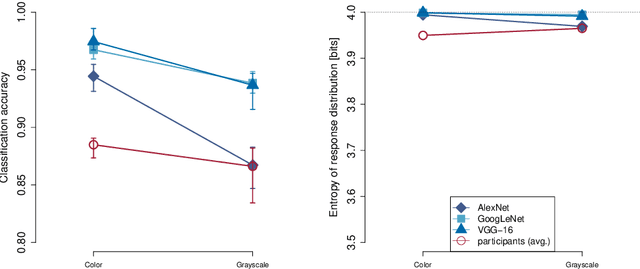
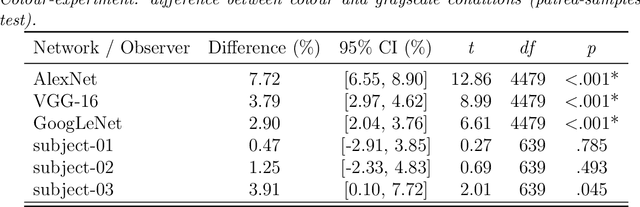
Human visual object recognition is typically rapid and seemingly effortless, as well as largely independent of viewpoint and object orientation. Until very recently, animate visual systems were the only ones capable of this remarkable computational feat. This has changed with the rise of a class of computer vision algorithms called deep neural networks (DNNs) that achieve human-level classification performance on object recognition tasks. Furthermore, a growing number of studies report similarities in the way DNNs and the human visual system process objects, suggesting that current DNNs may be good models of human visual object recognition. Yet there clearly exist important architectural and processing differences between state-of-the-art DNNs and the primate visual system. The potential behavioural consequences of these differences are not well understood. We aim to address this issue by comparing human and DNN generalisation abilities towards image degradations. We find the human visual system to be more robust to image manipulations like contrast reduction, additive noise or novel eidolon-distortions. In addition, we find progressively diverging classification error-patterns between man and DNNs when the signal gets weaker, indicating that there may still be marked differences in the way humans and current DNNs perform visual object recognition. We envision that our findings as well as our carefully measured and freely available behavioural datasets provide a new useful benchmark for the computer vision community to improve the robustness of DNNs and a motivation for neuroscientists to search for mechanisms in the brain that could facilitate this robustness.