 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Models for color discrimination and color constancy
Dec 28, 2020



Color constancy is our ability to perceive constant colors across varying illuminations. Here, we trained deep neural networks to be color constant and evaluated their performance with varying cues. Inputs to the networks consisted of the cone excitations in 3D-rendered images of 2115 different 3D-shapes, with spectral reflectances of 1600 different Munsell chips, illuminated under 278 different natural illuminations. The models were trained to classify the reflectance of the objects. One network, Deep65, was trained under a fixed daylight D65 illumination, while DeepCC was trained under varying illuminations. Testing was done with 4 new illuminations with equally spaced CIEL*a*b* chromaticities, 2 along the daylight locus and 2 orthogonal to it. We found a high degree of color constancy for DeepCC, and constancy was higher along the daylight locus. When gradually removing cues from the scene, constancy decreased. High levels of color constancy were achieved with different DNN architectures. Both ResNets and classical ConvNets of varying degrees of complexity performed well. However, DeepCC, a convolutional network, represented colors along the 3 color dimensions of human color vision, while ResNets showed a more complex representation.
The Utility of Decorrelating Colour Spaces in Vector Quantised Variational Autoencoders
Sep 30, 2020
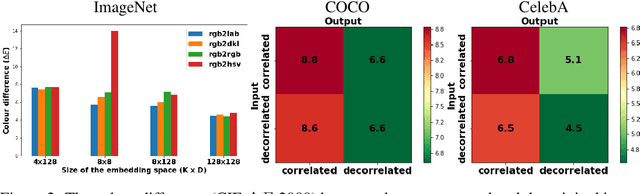
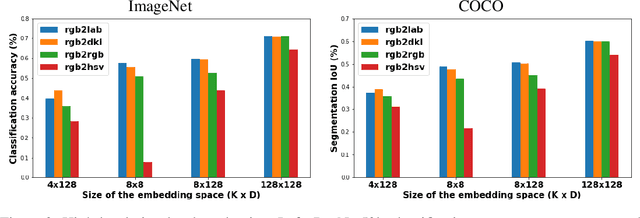
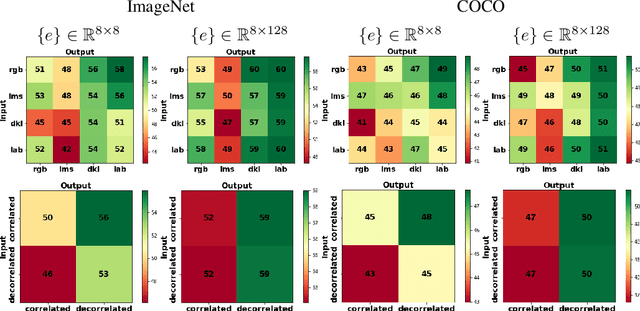
Vector quantised variational autoencoders (VQ-VAE) are characterised by three main components: 1) encoding visual data, 2) assigning $k$ different vectors in the so-called embedding space, and 3) decoding the learnt features. While images are often represented in RGB colour space, the specific organisation of colours in other spaces also offer interesting features, e.g. CIE L*a*b* decorrelates chromaticity into opponent axes. In this article, we propose colour space conversion, a simple quasi-unsupervised task, to enforce a network learning structured representations. To this end, we trained several instances of VQ-VAE whose input is an image in one colour space, and its output in another, e.g. from RGB to CIE L*a*b* (in total five colour spaces were considered). We examined the finite embedding space of trained networks in order to disentangle the colour representation in VQ-VAE models. Our analysis suggests that certain vectors encode hue and others luminance information. We further evaluated the quality of reconstructed images at low-level using pixel-wise colour metrics, and at high-level by inputting them to image classification and scene segmentation networks. We conducted experiments in three benchmark datasets: ImageNet, COCO and CelebA. Our results show, with respect to the baseline network (whose input and output are RGB), colour conversion to decorrelated spaces obtains 1-2 Delta-E lower colour difference and 5-10% higher classification accuracy. We also observed that the learnt embedding space is easier to interpret in colour opponent models.
Paradox in Deep Neural Networks: Similar yet Different while Different yet Similar
Mar 12, 2019
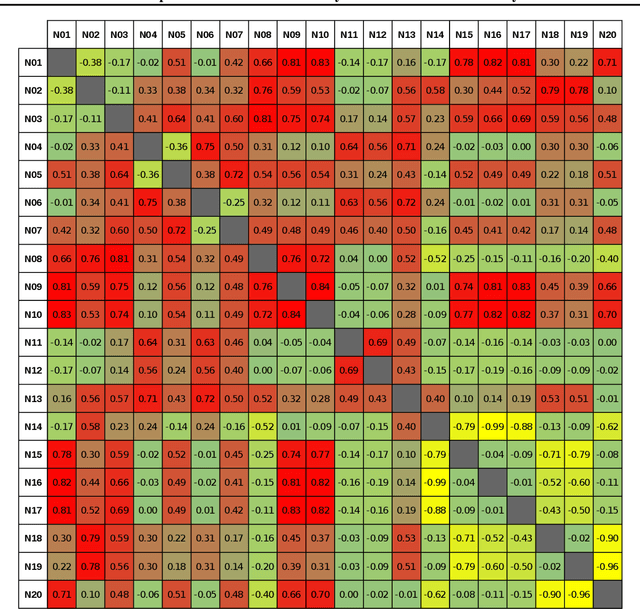
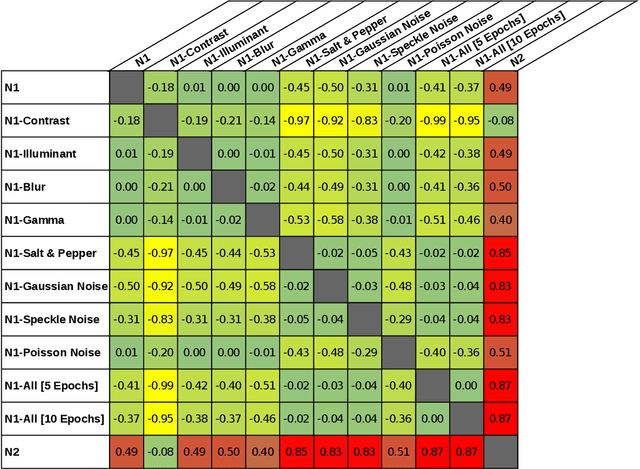
Machine learning is advancing towards a data-science approach, implying a necessity to a line of investigation to divulge the knowledge learnt by deep neuronal networks. Limiting the comparison among networks merely to a predefined intelligent ability, according to ground truth, does not suffice, it should be associated with innate similarity of these artificial entities. Here, we analysed multiple instances of an identical architecture trained to classify objects in static images (CIFAR and ImageNet data sets). We evaluated the performance of the networks under various distortions and compared it to the intrinsic similarity between their constituent kernels. While we expected a close correspondence between these two measures, we observed a puzzling phenomenon. Pairs of networks whose kernels' weights are over 99.9% correlated can exhibit significantly different performances, yet other pairs with no correlation can reach quite compatible levels of performance. We show implications of this for transfer learning, and argue its importance in our general understanding of what intelligence is, whether natural or artificial.
Manifestation of Image Contrast in Deep Networks
Feb 12, 2019
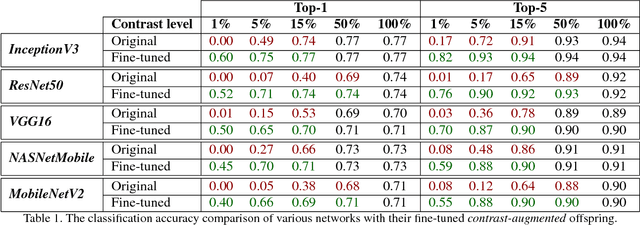

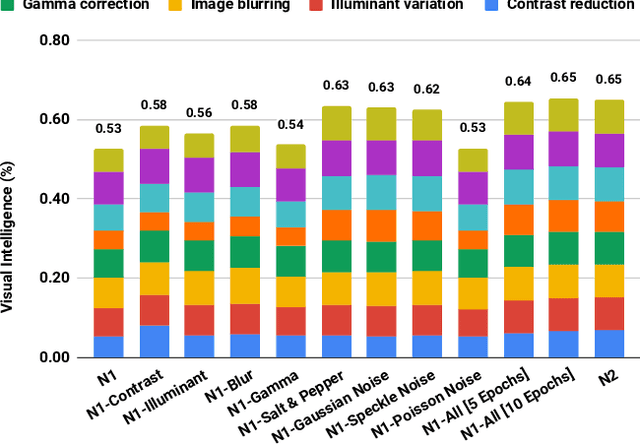
Contrast is subject to dramatic changes across the visual field, depending on the source of light and scene configurations. Hence, the human visual system has evolved to be more sensitive to contrast than absolute luminance. This feature is equally desired for machine vision: the ability to recognise patterns even when aspects of them are transformed due to variation in local and global contrast. In this work, we thoroughly investigate the impact of image contrast on prominent deep convolutional networks, both during the training and testing phase. The results of conducted experiments testify to an evident deterioration in the accuracy of all state-of-the-art networks at low-contrast images. We demonstrate that "contrast-augmentation" is a sufficient condition to endow a network with invariance to contrast. This practice shows no negative side effects, quite the contrary, it might allow a model to refrain from other illuminance related over-fittings. This ability can also be achieved by a short fine-tuning procedure, which opens new lines of investigation on mechanisms involved in two networks whose weights are over 99.9% correlated, yet astonishingly produce utterly different outcomes. Our further analysis suggests that the optimisation algorithm is an influential factor, however with a significantly lower effect; and while the choice of an architecture manifests a negligible impact on this phenomenon, the first layers appear to be more critical.
How is Contrast Encoded in Deep Neural Networks?
Sep 05, 2018



Contrast is a crucial factor in visual information processing. It is desired for a visual system - irrespective of being biological or artificial - to "perceive" the world robustly under large potential changes in illumination. In this work, we studied the responses of deep neural networks (DNN) to identical images at different levels of contrast. We analysed the activation of kernels in the convolutional layers of eight prominent networks with distinct architectures (e.g. VGG and Inception). The results of our experiments indicate that those networks with a higher tolerance to alteration of contrast have more than one convolutional layer prior to the first max-pooling operator. It appears that the last convolutional layer before the first max-pooling acts as a mitigator of contrast variation in input images. In our investigation, interestingly, we observed many similarities between the mechanisms of these DNNs and biological visual systems. These comparisons allow us to understand more profoundly the underlying mechanisms of a visual system that is grounded on the basis of "data-analysis".
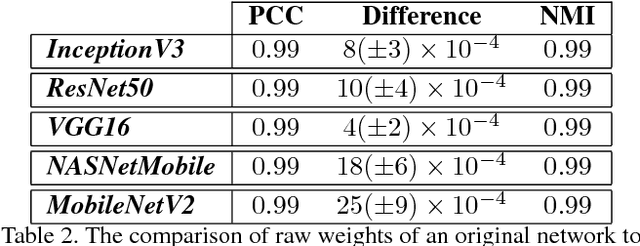
Colour Constancy: Biologically-inspired Contrast Variant Pooling Mechanism
Nov 29, 2017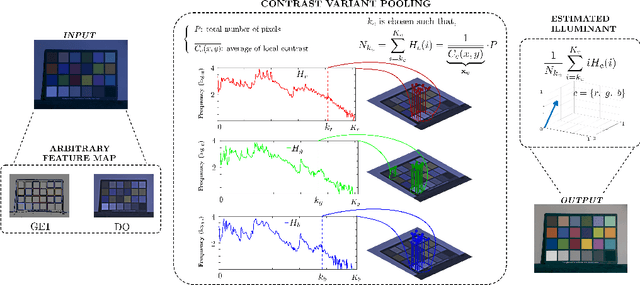
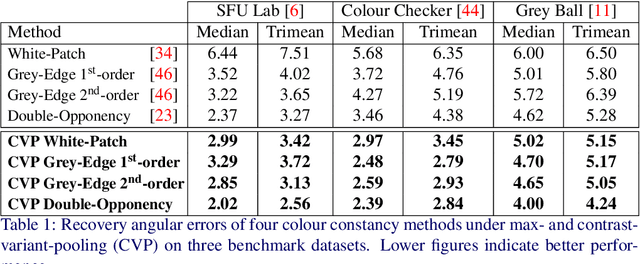

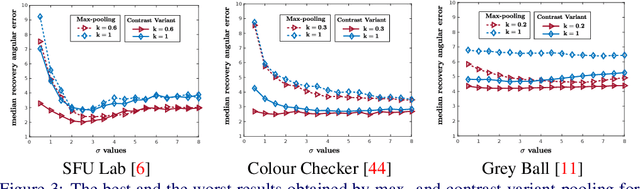
Pooling is a ubiquitous operation in image processing algorithms that allows for higher-level processes to collect relevant low-level features from a region of interest. Currently, max-pooling is one of the most commonly used operators in the computational literature. However, it can lack robustness to outliers due to the fact that it relies merely on the peak of a function. Pooling mechanisms are also present in the primate visual cortex where neurons of higher cortical areas pool signals from lower ones. The receptive fields of these neurons have been shown to vary according to the contrast by aggregating signals over a larger region in the presence of low contrast stimuli. We hypothesise that this contrast-variant-pooling mechanism can address some of the shortcomings of max-pooling. We modelled this contrast variation through a histogram clipping in which the percentage of pooled signal is inversely proportional to the local contrast of an image. We tested our hypothesis by applying it to the phenomenon of colour constancy where a number of popular algorithms utilise a max-pooling step (e.g. White-Patch, Grey-Edge and Double-Opponency). For each of these methods, we investigated the consequences of replacing their original max-pooling by the proposed contrast-variant-pooling. Our experiments on three colour constancy benchmark datasets suggest that previous results can significantly improve by adopting a contrast-variant-pooling mechanism.
Colour Terms: a Categorisation Model Inspired by Visual Cortex Neurons
Sep 19, 2017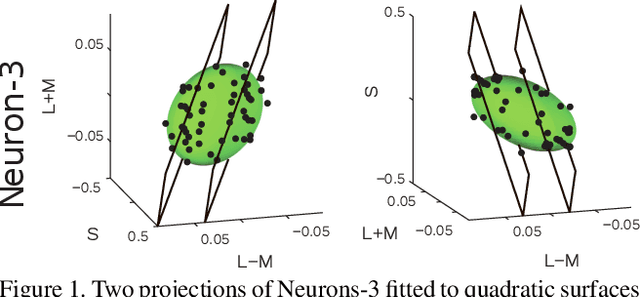
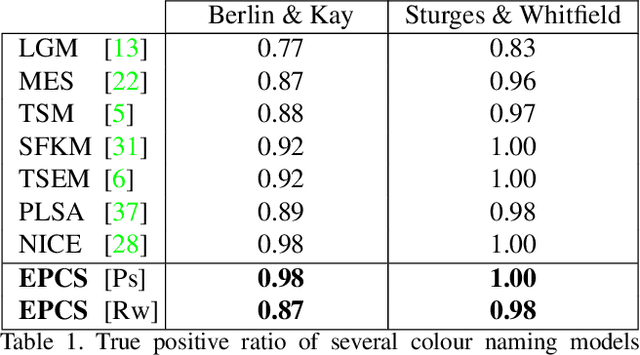
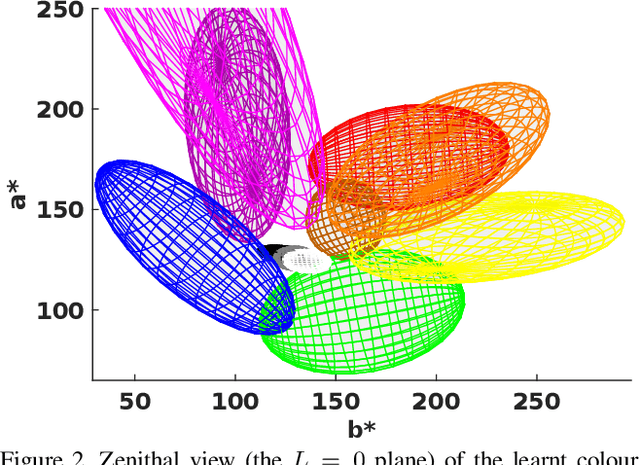
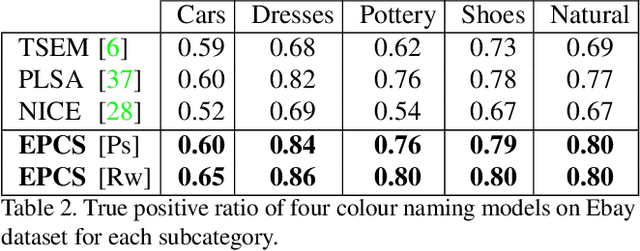
Although it seems counter-intuitive, categorical colours do not exist as external physical entities but are very much the product of our brains. Our cortical machinery segments the world and associate objects to specific colour terms, which is not only convenient for communication but also increases the efficiency of visual processing by reducing the dimensionality of input scenes. Although the neural substrate for this phenomenon is unknown, a recent study of cortical colour processing has discovered a set of neurons that are isoresponsive to stimuli in the shape of 3D-ellipsoidal surfaces in colour-opponent space. We hypothesise that these neurons might help explain the underlying mechanisms of colour naming in the visual cortex. Following this, we propose a biologically-inspired colour naming model where each colour term - e.g. red, green, blue, yellow, etc. - is represented through an ellipsoid in 3D colour-opponent space. This paradigm is also supported by previous psychophysical colour categorisation experiments whose results resemble such shapes. "Belongingness" of each pixel to different colour categories is computed by a non-linear sigmoidal logistic function. The final colour term for a given pixel is calculated by a maximum pooling mechanism. The simplicity of our model allows its parameters to be learnt from a handful of segmented images. It also offers a straightforward extension to include further colour terms. Additionally, ellipsoids of proposed model can adapt to image contents offering a dynamical solution in order to address phenomenon of colour constancy. Our results on the Munsell chart and two datasets of real-world images show an overall improvement comparing to state-of-the-art algorithms.