 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Models for color discrimination and color constancy
Dec 28, 2020



Color constancy is our ability to perceive constant colors across varying illuminations. Here, we trained deep neural networks to be color constant and evaluated their performance with varying cues. Inputs to the networks consisted of the cone excitations in 3D-rendered images of 2115 different 3D-shapes, with spectral reflectances of 1600 different Munsell chips, illuminated under 278 different natural illuminations. The models were trained to classify the reflectance of the objects. One network, Deep65, was trained under a fixed daylight D65 illumination, while DeepCC was trained under varying illuminations. Testing was done with 4 new illuminations with equally spaced CIEL*a*b* chromaticities, 2 along the daylight locus and 2 orthogonal to it. We found a high degree of color constancy for DeepCC, and constancy was higher along the daylight locus. When gradually removing cues from the scene, constancy decreased. High levels of color constancy were achieved with different DNN architectures. Both ResNets and classical ConvNets of varying degrees of complexity performed well. However, DeepCC, a convolutional network, represented colors along the 3 color dimensions of human color vision, while ResNets showed a more complex representation.
The Utility of Decorrelating Colour Spaces in Vector Quantised Variational Autoencoders
Sep 30, 2020
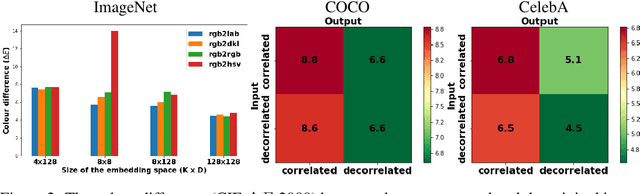
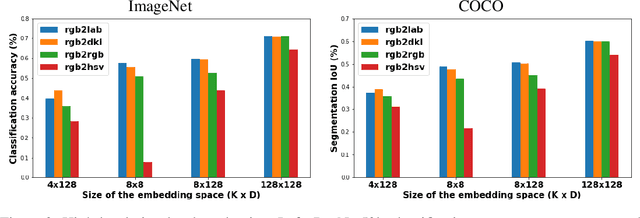
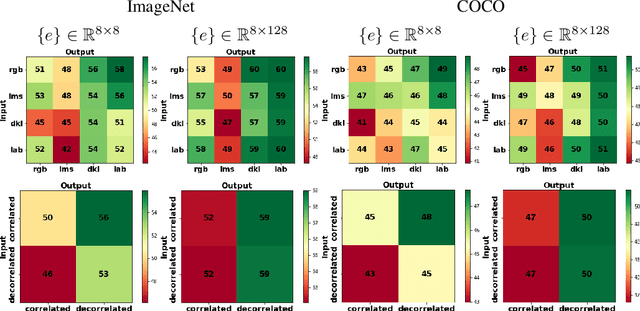
Vector quantised variational autoencoders (VQ-VAE) are characterised by three main components: 1) encoding visual data, 2) assigning $k$ different vectors in the so-called embedding space, and 3) decoding the learnt features. While images are often represented in RGB colour space, the specific organisation of colours in other spaces also offer interesting features, e.g. CIE L*a*b* decorrelates chromaticity into opponent axes. In this article, we propose colour space conversion, a simple quasi-unsupervised task, to enforce a network learning structured representations. To this end, we trained several instances of VQ-VAE whose input is an image in one colour space, and its output in another, e.g. from RGB to CIE L*a*b* (in total five colour spaces were considered). We examined the finite embedding space of trained networks in order to disentangle the colour representation in VQ-VAE models. Our analysis suggests that certain vectors encode hue and others luminance information. We further evaluated the quality of reconstructed images at low-level using pixel-wise colour metrics, and at high-level by inputting them to image classification and scene segmentation networks. We conducted experiments in three benchmark datasets: ImageNet, COCO and CelebA. Our results show, with respect to the baseline network (whose input and output are RGB), colour conversion to decorrelated spaces obtains 1-2 Delta-E lower colour difference and 5-10% higher classification accuracy. We also observed that the learnt embedding space is easier to interpret in colour opponent models.