 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Utility of Decorrelating Colour Spaces in Vector Quantised Variational Autoencoders
Paper and Code

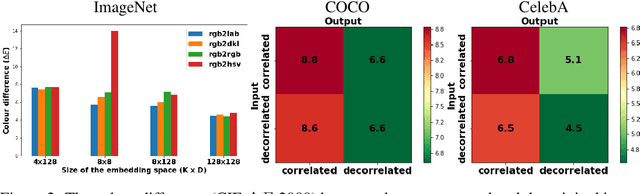
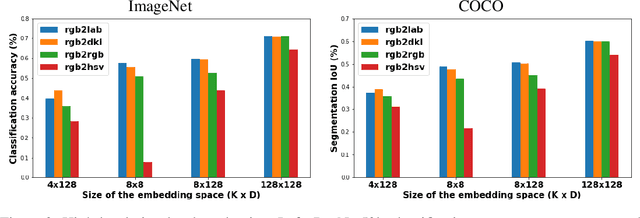
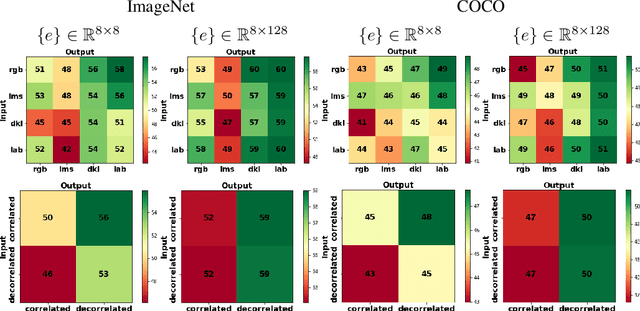
Vector quantised variational autoencoders (VQ-VAE) are characterised by three main components: 1) encoding visual data, 2) assigning $k$ different vectors in the so-called embedding space, and 3) decoding the learnt features. While images are often represented in RGB colour space, the specific organisation of colours in other spaces also offer interesting features, e.g. CIE L*a*b* decorrelates chromaticity into opponent axes. In this article, we propose colour space conversion, a simple quasi-unsupervised task, to enforce a network learning structured representations. To this end, we trained several instances of VQ-VAE whose input is an image in one colour space, and its output in another, e.g. from RGB to CIE L*a*b* (in total five colour spaces were considered). We examined the finite embedding space of trained networks in order to disentangle the colour representation in VQ-VAE models. Our analysis suggests that certain vectors encode hue and others luminance information. We further evaluated the quality of reconstructed images at low-level using pixel-wise colour metrics, and at high-level by inputting them to image classification and scene segmentation networks. We conducted experiments in three benchmark datasets: ImageNet, COCO and CelebA. Our results show, with respect to the baseline network (whose input and output are RGB), colour conversion to decorrelated spaces obtains 1-2 Delta-E lower colour difference and 5-10% higher classification accuracy. We also observed that the learnt embedding space is easier to interpret in colour opponent models.