 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEagerPy: Writing Code That Works Natively with PyTorch, TensorFlow, JAX, and NumPy
Aug 10, 2020EagerPy is a Python framework that lets you write code that automatically works natively with PyTorch, TensorFlow, JAX, and NumPy. Library developers no longer need to choose between supporting just one of these frameworks or reimplementing the library for each framework and dealing with code duplication. Users of such libraries can more easily switch frameworks without being locked in by a specific 3rd party library. Beyond multi-framework support, EagerPy also brings comprehensive type annotations and consistent support for method chaining to any framework. The latest documentation is available online at https://eagerpy.jonasrauber.de and the code can be found on GitHub at https://github.com/jonasrauber/eagerpy.
Fast Differentiable Clipping-Aware Normalization and Rescaling
Jul 15, 2020Rescaling a vector $\vec{\delta} \in \mathbb{R}^n$ to a desired length is a common operation in many areas such as data science and machine learning. When the rescaled perturbation $\eta \vec{\delta}$ is added to a starting point $\vec{x} \in D$ (where $D$ is the data domain, e.g. $D = [0, 1]^n$), the resulting vector $\vec{v} = \vec{x} + \eta \vec{\delta}$ will in general not be in $D$. To enforce that the perturbed vector $v$ is in $D$, the values of $\vec{v}$ can be clipped to $D$. This subsequent element-wise clipping to the data domain does however reduce the effective perturbation size and thus interferes with the rescaling of $\vec{\delta}$. The optimal rescaling $\eta$ to obtain a perturbation with the desired norm after the clipping can be iteratively approximated using a binary search. However, such an iterative approach is slow and non-differentiable. Here we show that the optimal rescaling can be found analytically using a fast and differentiable algorithm. Our algorithm works for any p-norm and can be used to train neural networks on inputs with normalized perturbations. We provide native implementations for PyTorch, TensorFlow, JAX, and NumPy based on EagerPy.
Modeling patterns of smartphone usage and their relationship to cognitive health
Nov 13, 2019


The ubiquity of smartphone usage in many people's lives make it a rich source of information about a person's mental and cognitive state. In this work we analyze 12 weeks of phone usage data from 113 older adults, 31 with diagnosed cognitive impairment and 82 without. We develop structured models of users' smartphone interactions to reveal differences in phone usage patterns between people with and without cognitive impairment. In particular, we focus on inferring specific types of phone usage sessions that are predictive of cognitive impairment. Our model achieves an AUROC of 0.79 when discriminating between healthy and symptomatic subjects, and its interpretability enables novel insights into which aspects of phone usage strongly relate with cognitive health in our dataset.
Accurate, reliable and fast robustness evaluation
Jul 01, 2019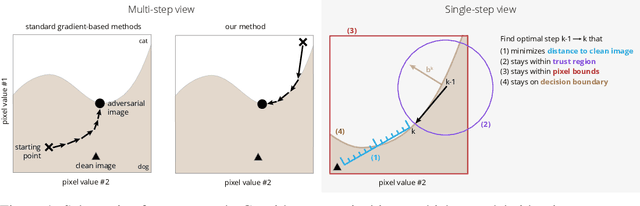
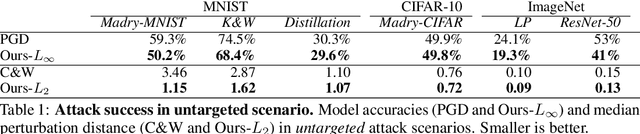


Throughout the past five years, the susceptibility of neural networks to minimal adversarial perturbations has moved from a peculiar phenomenon to a core issue in Deep Learning. Despite much attention, however, progress towards more robust models is significantly impaired by the difficulty of evaluating the robustness of neural network models. Today's methods are either fast but brittle (gradient-based attacks), or they are fairly reliable but slow (score- and decision-based attacks). We here develop a new set of gradient-based adversarial attacks which (a) are more reliable in the face of gradient-masking than other gradient-based attacks, (b) perform better and are more query efficient than current state-of-the-art gradient-based attacks, (c) can be flexibly adapted to a wide range of adversarial criteria and (d) require virtually no hyperparameter tuning. These findings are carefully validated across a diverse set of six different models and hold for L2 and L_infinity in both targeted as well as untargeted scenarios. Implementations will be made available in all major toolboxes (Foolbox, CleverHans and ART). Furthermore, we will soon add additional content and experiments, including L0 and L1 versions of our attack as well as additional comparisons to other L2 and L_infinity attacks. We hope that this class of attacks will make robustness evaluations easier and more reliable, thus contributing to more signal in the search for more robust machine learning models.
Scaling up the randomized gradient-free adversarial attack reveals overestimation of robustness using established attacks
Mar 27, 2019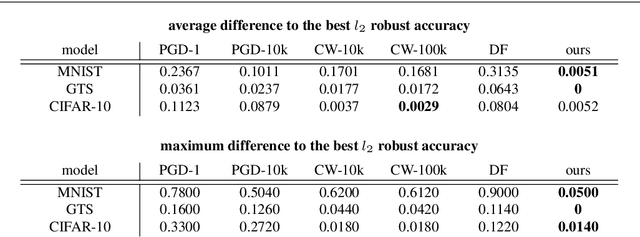
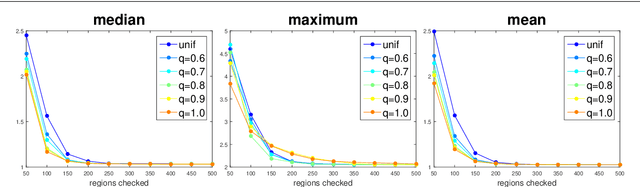
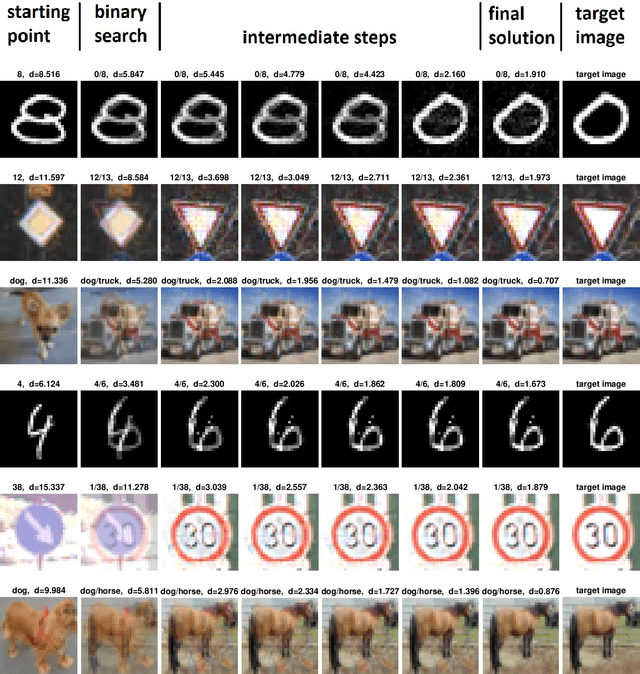
Modern neural networks are highly non-robust against adversarial manipulation. A significant amount of work has been invested in techniques to compute lower bounds on robustness through formal guarantees and to build provably robust model. However it is still difficult to apply them to larger networks or in order to get robustness against larger perturbations. Thus attack strategies are needed to provide tight upper bounds on the actual robustness. We significantly improve the randomized gradient-free attack for ReLU networks [9], in particular by scaling it up to large networks. We show that our attack achieves similar or significantly smaller robust accuracy than state-of-the-art attacks like PGD or the one of Carlini and Wagner, thus revealing an overestimation of the robustness by these state-of-the-art methods. Our attack is not based on a gradient descent scheme and in this sense gradient-free, which makes it less sensitive to the choice of hyperparameters as no careful selection of the stepsize is required.
On Evaluating Adversarial Robustness
Feb 20, 2019Correctly evaluating defenses against adversarial examples has proven to be extremely difficult. Despite the significant amount of recent work attempting to design defenses that withstand adaptive attacks, few have succeeded; most papers that propose defenses are quickly shown to be incorrect. We believe a large contributing factor is the difficulty of performing security evaluations. In this paper, we discuss the methodological foundations, review commonly accepted best practices, and suggest new methods for evaluating defenses to adversarial examples. We hope that both researchers developing defenses as well as readers and reviewers who wish to understand the completeness of an evaluation consider our advice in order to avoid common pitfalls.
Towards the first adversarially robust neural network model on MNIST
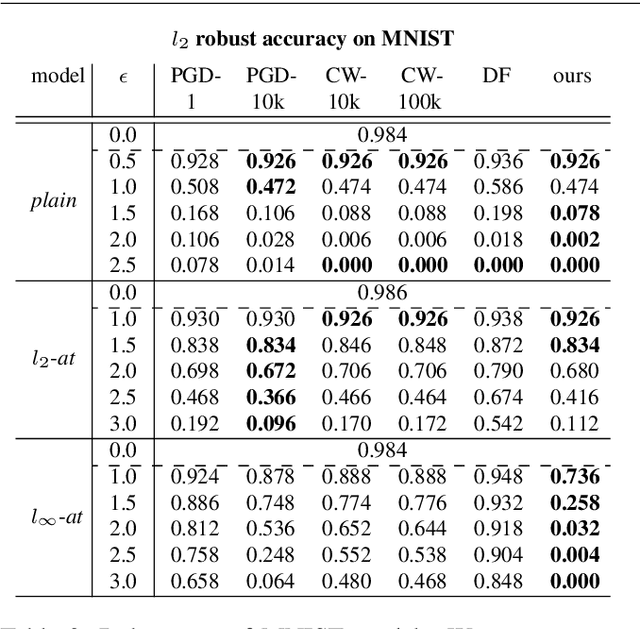
Sep 20, 2018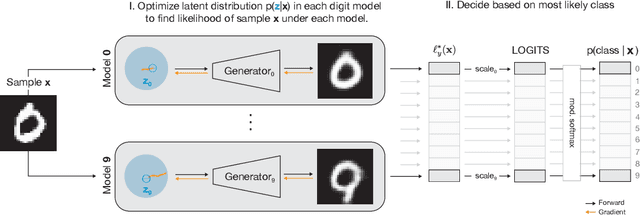
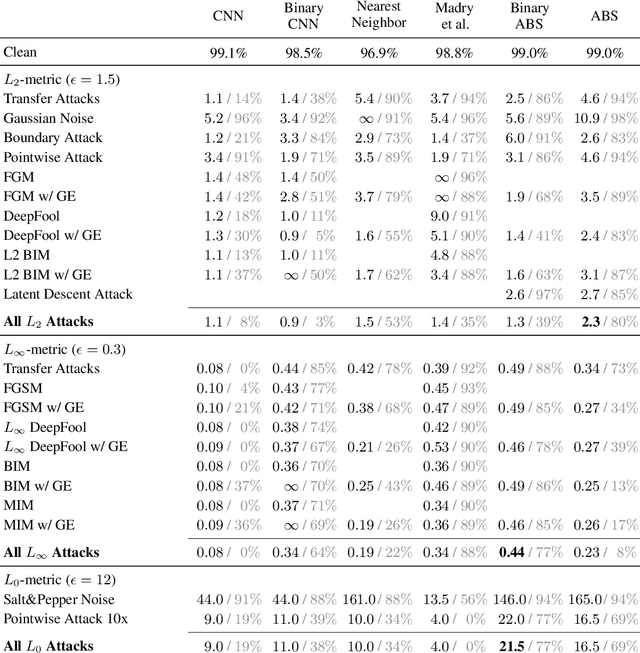
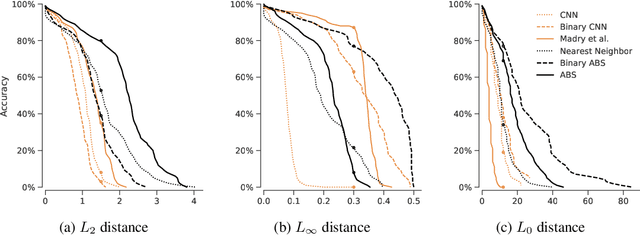

Despite much effort, deep neural networks remain highly susceptible to tiny input perturbations and even for MNIST, one of the most common toy datasets in computer vision, no neural network model exists for which adversarial perturbations are large and make semantic sense to humans. We show that even the widely recognized and by far most successful defense by Madry et al. (1) overfits on the L-infinity metric (it's highly susceptible to L2 and L0 perturbations), (2) classifies unrecognizable images with high certainty, (3) performs not much better than simple input binarization and (4) features adversarial perturbations that make little sense to humans. These results suggest that MNIST is far from being solved in terms of adversarial robustness. We present a novel robust classification model that performs analysis by synthesis using learned class-conditional data distributions. We derive bounds on the robustness and go to great length to empirically evaluate our model using maximally effective adversarial attacks by (a) applying decision-based, score-based, gradient-based and transfer-based attacks for several different Lp norms, (b) by designing a new attack that exploits the structure of our defended model and (c) by devising a novel decision-based attack that seeks to minimize the number of perturbed pixels (L0). The results suggest that our approach yields state-of-the-art robustness on MNIST against L0, L2 and L-infinity perturbations and we demonstrate that most adversarial examples are strongly perturbed towards the perceptual boundary between the original and the adversarial class.
Generalisation in humans and deep neural networks
Aug 27, 2018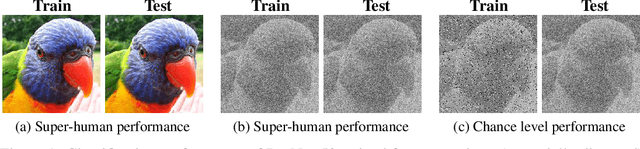
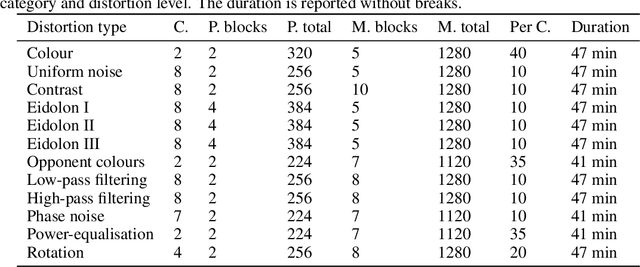
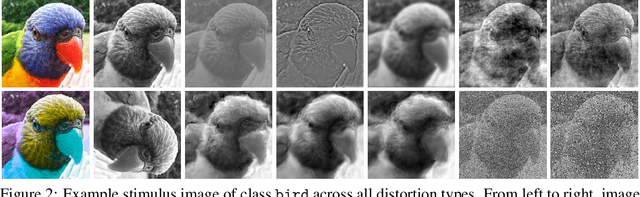
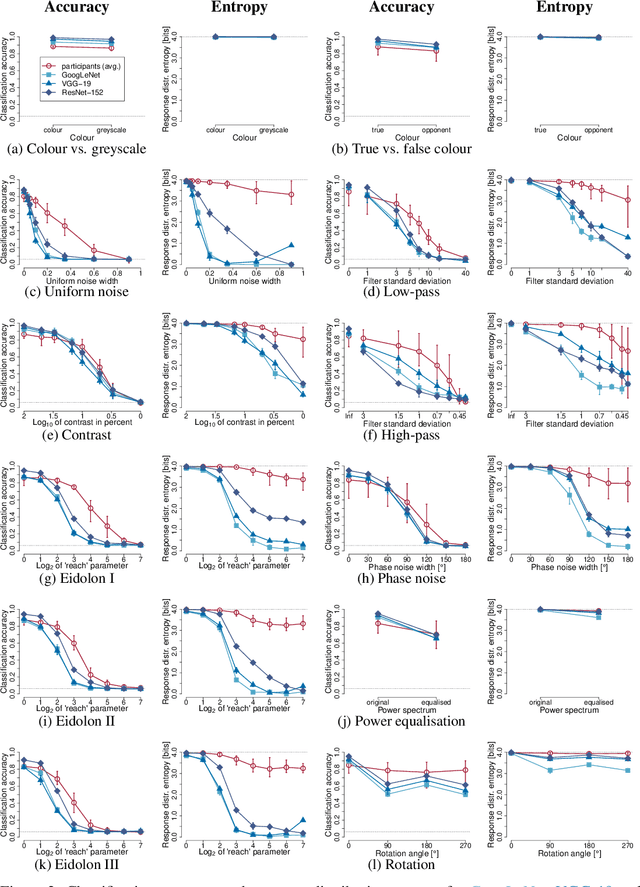
We compare the robustness of humans and current convolutional deep neural networks (DNNs) on object recognition under twelve different types of image degradations. First, using three well known DNNs (ResNet-152, VGG-19, GoogLeNet) we find the human visual system to be more robust to nearly all of the tested image manipulations, and we observe progressively diverging classification error-patterns between humans and DNNs when the signal gets weaker. Secondly, we show that DNNs trained directly on distorted images consistently surpass human performance on the exact distortion types they were trained on, yet they display extremely poor generalisation abilities when tested on other distortion types. For example, training on salt-and-pepper noise does not imply robustness on uniform white noise and vice versa. Thus, changes in the noise distribution between training and testing constitutes a crucial challenge to deep learning vision systems that can be systematically addressed in a lifelong machine learning approach. Our new dataset consisting of 83K carefully measured human psychophysical trials provide a useful reference for lifelong robustness against image degradations set by the human visual system.
Adversarial Vision Challenge
Aug 06, 2018The NIPS 2018 Adversarial Vision Challenge is a competition to facilitate measurable progress towards robust machine vision models and more generally applicable adversarial attacks. This document is an updated version of our competition proposal that was accepted in the competition track of 32nd Conference on Neural Information Processing Systems (NIPS 2018).
Technical Report on the CleverHans v2.1.0 Adversarial Examples Library
Jun 27, 2018CleverHans is a software library that provides standardized reference implementations of adversarial example construction techniques and adversarial training. The library may be used to develop more robust machine learning models and to provide standardized benchmarks of models' performance in the adversarial setting. Benchmarks constructed without a standardized implementation of adversarial example construction are not comparable to each other, because a good result may indicate a robust model or it may merely indicate a weak implementation of the adversarial example construction procedure. This technical report is structured as follows. Section 1 provides an overview of adversarial examples in machine learning and of the CleverHans software. Section 2 presents the core functionalities of the library: namely the attacks based on adversarial examples and defenses to improve the robustness of machine learning models to these attacks. Section 3 describes how to report benchmark results using the library. Section 4 describes the versioning system.