 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
The Food Recognition Benchmark: Using DeepLearning to Recognize Food on Images
Jun 30, 2021

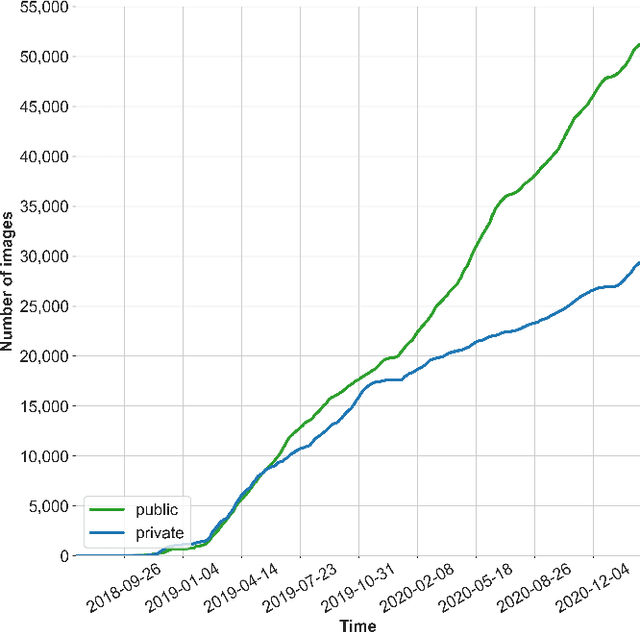
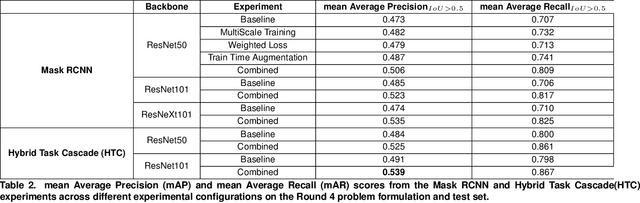
The automatic recognition of food on images has numerous interesting applications, including nutritional tracking in medical cohorts. The problem has received significant research attention, but an ongoing public benchmark to develop open and reproducible algorithms has been missing. Here, we report on the setup of such a benchmark using publicly available food images sourced through the mobile MyFoodRepo app. Through four rounds, the benchmark released the MyFoodRepo-273 dataset constituting 24,119 images and a total of 39,325 segmented polygons categorized in 273 different classes. Models were evaluated on private tests sets from the same platform with 5,000 images and 7,865 annotations in the final round. Top-performing models on the 273 food categories reached a mean average precision of 0.568 (round 4) and a mean average recall of 0.885 (round 3). We present experimental validation of round 4 results, and discuss implications of the benchmark setup designed to increase the size and diversity of the dataset for future rounds.
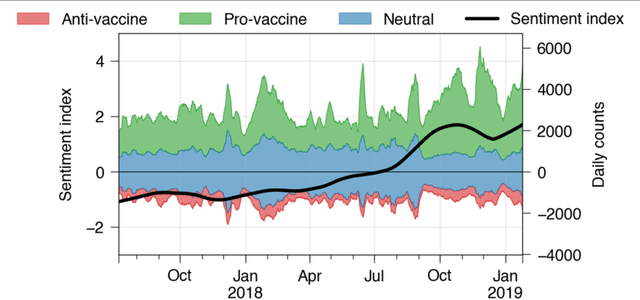
Addressing machine learning concept drift reveals declining vaccine sentiment during the COVID-19 pandemic
Dec 07, 2020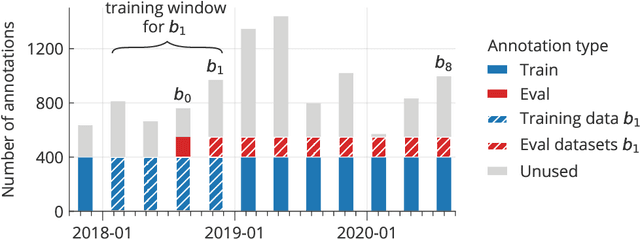
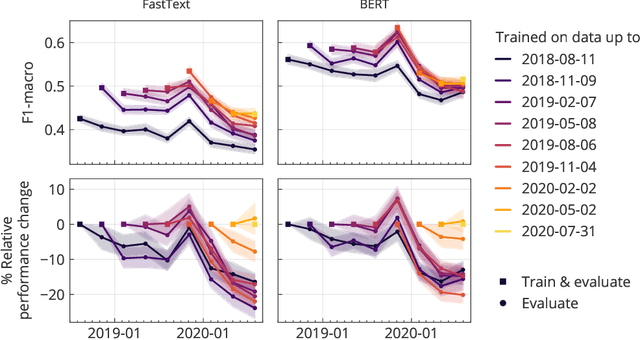
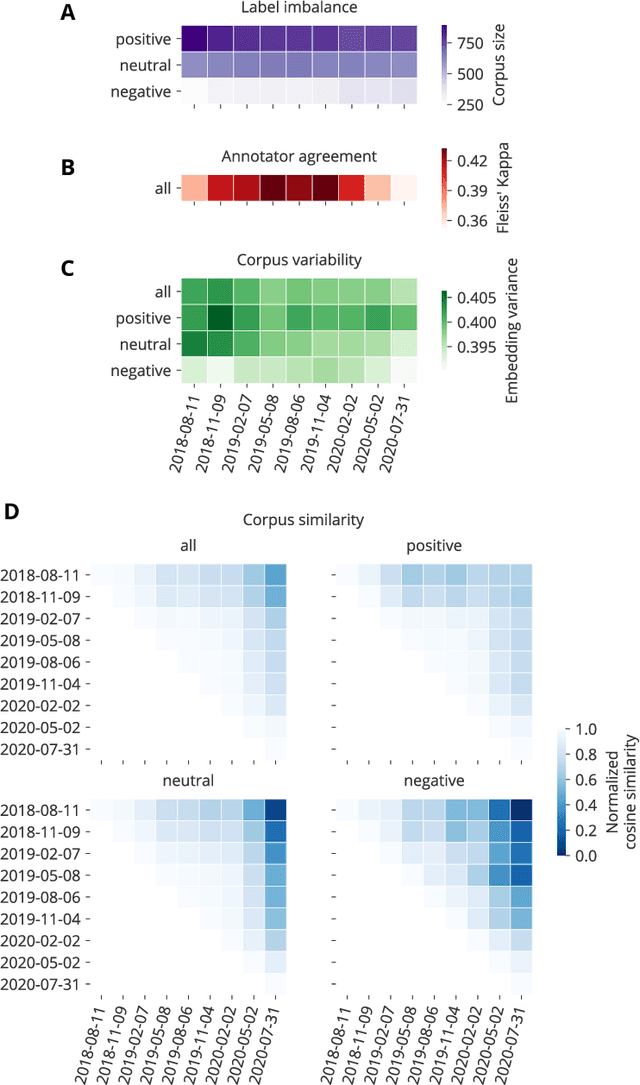
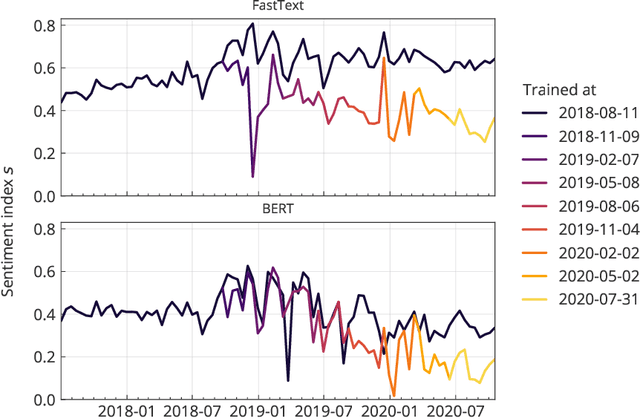
Social media analysis has become a common approach to assess public opinion on various topics, including those about health, in near real-time. The growing volume of social media posts has led to an increased usage of modern machine learning methods in natural language processing. While the rapid dynamics of social media can capture underlying trends quickly, it also poses a technical problem: algorithms trained on annotated data in the past may underperform when applied to contemporary data. This phenomenon, known as concept drift, can be particularly problematic when rapid shifts occur either in the topic of interest itself, or in the way the topic is discussed. Here, we explore the effect of machine learning concept drift by focussing on vaccine sentiments expressed on Twitter, a topic of central importance especially during the COVID-19 pandemic. We show that while vaccine sentiment has declined considerably during the COVID-19 pandemic in 2020, algorithms trained on pre-pandemic data would have largely missed this decline due to concept drift. Our results suggest that social media analysis systems must address concept drift in a continuous fashion in order to avoid the risk of systematic misclassification of data, which is particularly likely during a crisis when the underlying data can change suddenly and rapidly.
COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter
May 15, 2020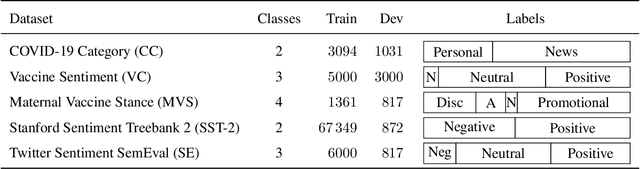
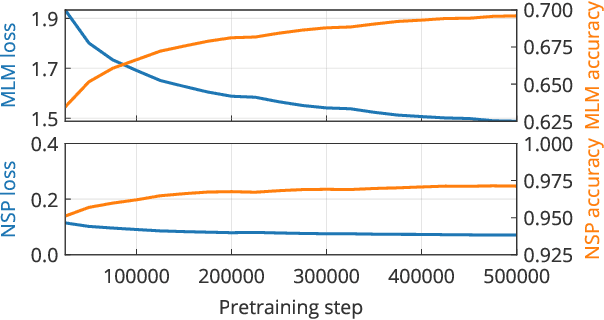

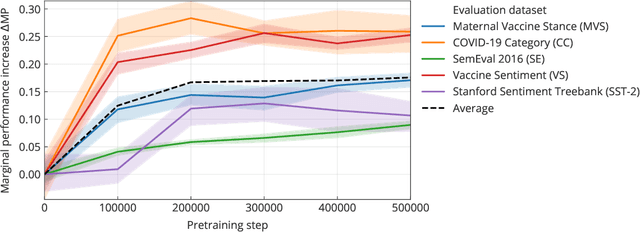
In this work, we release COVID-Twitter-BERT (CT-BERT), a transformer-based model, pretrained on a large corpus of Twitter messages on the topic of COVID-19. Our model shows a 10-30% marginal improvement compared to its base model, BERT-Large, on five different classification datasets. The largest improvements are on the target domain. Pretrained transformer models, such as CT-BERT, are trained on a specific target domain and can be used for a wide variety of natural language processing tasks, including classification, question-answering and chatbots. CT-BERT is optimised to be used on COVID-19 content, in particular social media posts from Twitter.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
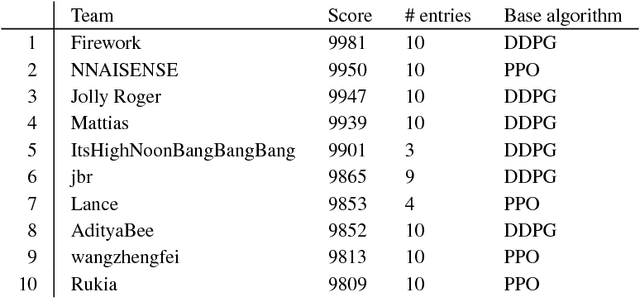

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Focus Group on Artificial Intelligence for Health
Sep 13, 2018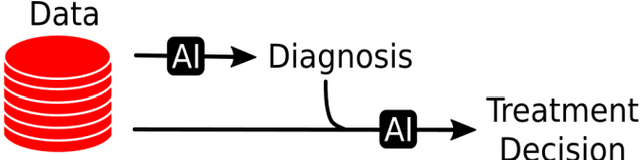
Artificial Intelligence (AI) - the phenomenon of machines being able to solve problems that require human intelligence - has in the past decade seen an enormous rise of interest due to significant advances in effectiveness and use. The health sector, one of the most important sectors for societies and economies worldwide, is particularly interesting for AI applications, given the ongoing digitalisation of all types of health information. The potential for AI assistance in the health domain is immense, because AI can support medical decision making at reduced costs, everywhere. However, due to the complexity of AI algorithms, it is difficult to distinguish good from bad AI-based solutions and to understand their strengths and weaknesses, which is crucial for clarifying responsibilities and for building trust. For this reason, the International Telecommunication Union (ITU) has established a new Focus Group on "Artificial Intelligence for Health" (FG-AI4H) in partnership with the World Health Organization (WHO). Health and care services are usually the responsibility of a government - even when provided through private insurance systems - and thus under the responsibility of WHO/ITU member states. FG-AI4H will identify opportunities for international standardization, which will foster the application of AI to health issues on a global scale. In particular, it will establish a standardized assessment framework with open benchmarks for the evaluation of AI-based methods for health, such as AI-based diagnosis, triage or treatment decisions.
Adversarial Vision Challenge
Aug 06, 2018The NIPS 2018 Adversarial Vision Challenge is a competition to facilitate measurable progress towards robust machine vision models and more generally applicable adversarial attacks. This document is an updated version of our competition proposal that was accepted in the competition track of 32nd Conference on Neural Information Processing Systems (NIPS 2018).
Crowdbreaks: Tracking Health Trends using Public Social Media Data and Crowdsourcing
May 14, 2018
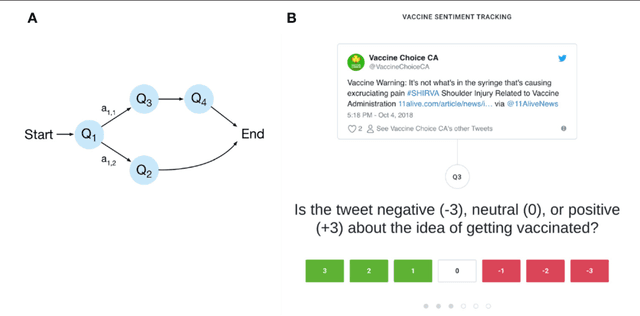

In the past decade, tracking health trends using social media data has shown great promise, due to a powerful combination of massive adoption of social media around the world, and increasingly potent hardware and software that enables us to work with these new big data streams. At the same time, many challenging problems have been identified. First, there is often a mismatch between how rapidly online data can change, and how rapidly algorithms are updated, which means that there is limited reusability for algorithms trained on past data as their performance decreases over time. Second, much of the work is focusing on specific issues during a specific past period in time, even though public health institutions would need flexible tools to assess multiple evolving situations in real time. Third, most tools providing such capabilities are proprietary systems with little algorithmic or data transparency, and thus little buy-in from the global public health and research community. Here, we introduce Crowdbreaks, an open platform which allows tracking of health trends by making use of continuous crowdsourced labelling of public social media content. The system is built in a way which automatizes the typical workflow from data collection, filtering, labelling and training of machine learning classifiers and therefore can greatly accelerate the research process in the public health domain. This work introduces the technical aspects of the platform and explores its future use cases.
Learning to Run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments
Apr 02, 2018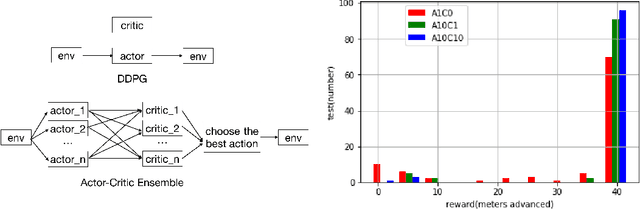

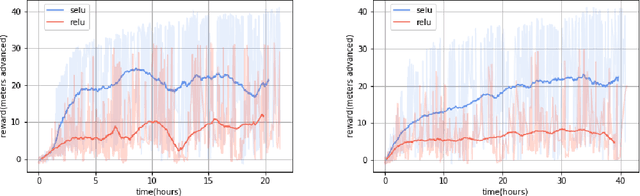
In the NIPS 2017 Learning to Run challenge, participants were tasked with building a controller for a musculoskeletal model to make it run as fast as possible through an obstacle course. Top participants were invited to describe their algorithms. In this work, we present eight solutions that used deep reinforcement learning approaches, based on algorithms such as Deep Deterministic Policy Gradient, Proximal Policy Optimization, and Trust Region Policy Optimization. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each of the eight teams implemented different modifications of the known algorithms.
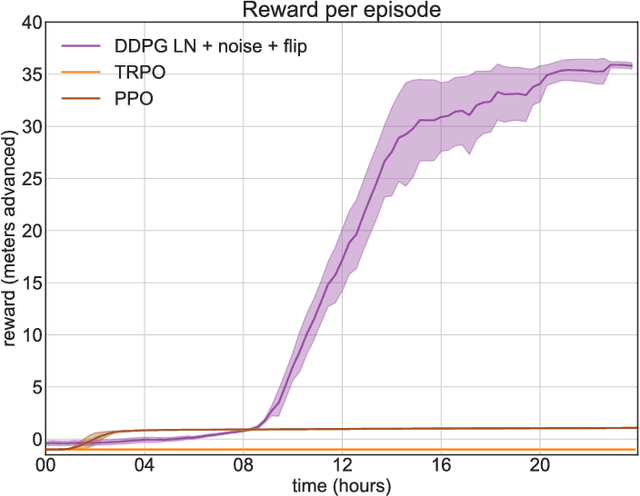
Learning to Run challenge: Synthesizing physiologically accurate motion using deep reinforcement learning
Mar 31, 2018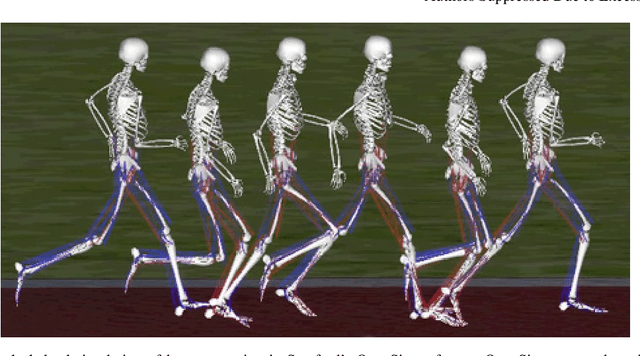
Synthesizing physiologically-accurate human movement in a variety of conditions can help practitioners plan surgeries, design experiments, or prototype assistive devices in simulated environments, reducing time and costs and improving treatment outcomes. Because of the large and complex solution spaces of biomechanical models, current methods are constrained to specific movements and models, requiring careful design of a controller and hindering many possible applications. We sought to discover if modern optimization methods efficiently explore these complex spaces. To do this, we posed the problem as a competition in which participants were tasked with developing a controller to enable a physiologically-based human model to navigate a complex obstacle course as quickly as possible, without using any experimental data. They were provided with a human musculoskeletal model and a physics-based simulation environment. In this paper, we discuss the design of the competition, technical difficulties, results, and analysis of the top controllers. The challenge proved that deep reinforcement learning techniques, despite their high computational cost, can be successfully employed as an optimization method for synthesizing physiologically feasible motion in high-dimensional biomechanical systems.