 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Food Recognition Benchmark: Using DeepLearning to Recognize Food on Images
Jun 30, 2021

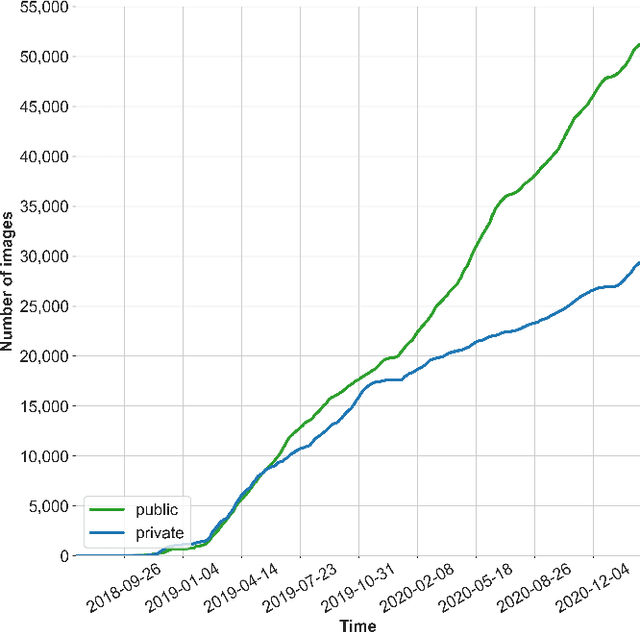
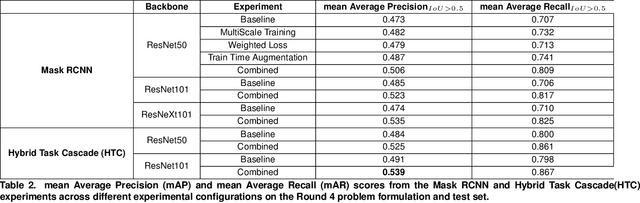
The automatic recognition of food on images has numerous interesting applications, including nutritional tracking in medical cohorts. The problem has received significant research attention, but an ongoing public benchmark to develop open and reproducible algorithms has been missing. Here, we report on the setup of such a benchmark using publicly available food images sourced through the mobile MyFoodRepo app. Through four rounds, the benchmark released the MyFoodRepo-273 dataset constituting 24,119 images and a total of 39,325 segmented polygons categorized in 273 different classes. Models were evaluated on private tests sets from the same platform with 5,000 images and 7,865 annotations in the final round. Top-performing models on the 273 food categories reached a mean average precision of 0.568 (round 4) and a mean average recall of 0.885 (round 3). We present experimental validation of round 4 results, and discuss implications of the benchmark setup designed to increase the size and diversity of the dataset for future rounds.