 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficiently Coupled Shape and Appearance Prior for Active Contour Segmentation
Mar 31, 2021
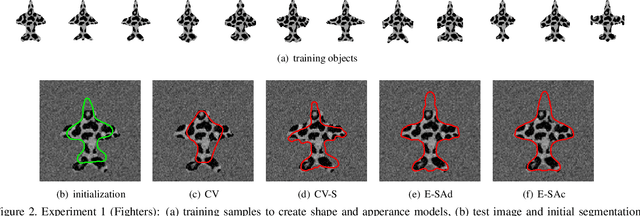
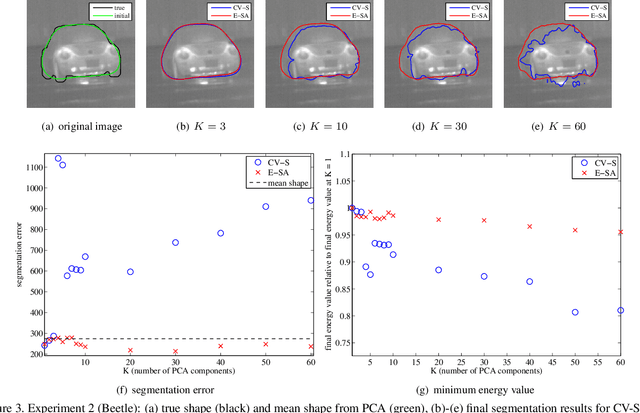
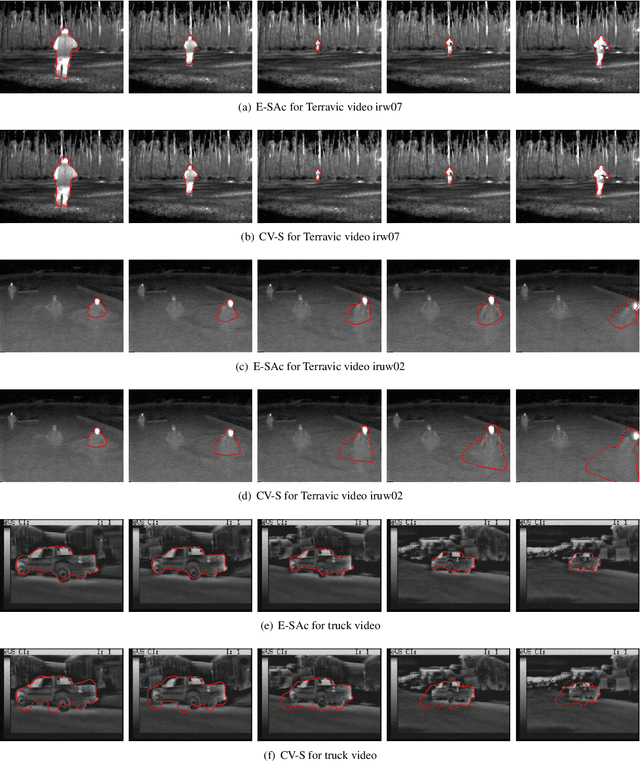
This paper proposes a novel training model based on shape and appearance features for object segmentation in images and videos. Whereas most such models rely on two-dimensional appearance templates or a finite set of descriptors, our appearance-based feature is a one-dimensional function, which is efficiently coupled with the object's shape by integrating intensities along the object's iso-contours. Joint PCA training on these shape and appearance features further exploits shape-appearance correlations and the resulting training model is incorporated in an active-contour-type energy functional for recognition-segmentation tasks. Experiments on synthetic and infrared images demonstrate how this shape and appearance training model improves accuracy compared to methods based on the Chan-Vese energy.
Crowdbreaks: Tracking Health Trends using Public Social Media Data and Crowdsourcing
May 14, 2018
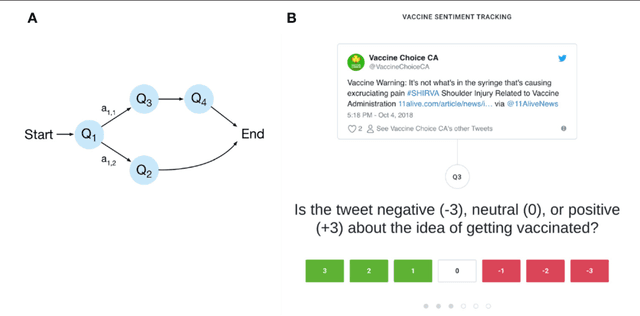

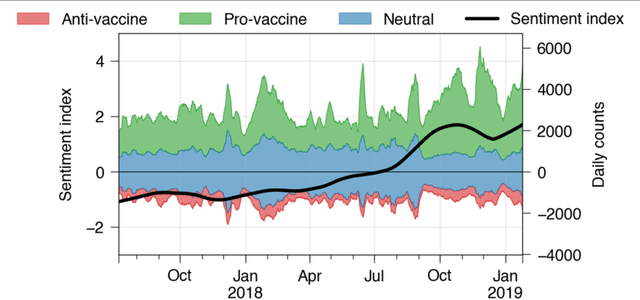
In the past decade, tracking health trends using social media data has shown great promise, due to a powerful combination of massive adoption of social media around the world, and increasingly potent hardware and software that enables us to work with these new big data streams. At the same time, many challenging problems have been identified. First, there is often a mismatch between how rapidly online data can change, and how rapidly algorithms are updated, which means that there is limited reusability for algorithms trained on past data as their performance decreases over time. Second, much of the work is focusing on specific issues during a specific past period in time, even though public health institutions would need flexible tools to assess multiple evolving situations in real time. Third, most tools providing such capabilities are proprietary systems with little algorithmic or data transparency, and thus little buy-in from the global public health and research community. Here, we introduce Crowdbreaks, an open platform which allows tracking of health trends by making use of continuous crowdsourced labelling of public social media content. The system is built in a way which automatizes the typical workflow from data collection, filtering, labelling and training of machine learning classifiers and therefore can greatly accelerate the research process in the public health domain. This work introduces the technical aspects of the platform and explores its future use cases.
Weak subsumption Constraints for Type Diagnosis: An Incremental Algorithm
Nov 20, 1995


We introduce constraints necessary for type checking a higher-order concurrent constraint language, and solve them with an incremental algorithm. Our constraint system extends rational unification by constraints x$\subseteq$ y saying that ``$x$ has at least the structure of $y$'', modelled by a weak instance relation between trees. This notion of instance has been carefully chosen to be weaker than the usual one which renders semi-unification undecidable. Semi-unification has more than once served to link unification problems arising from type inference and those considered in computational linguistics. Just as polymorphic recursion corresponds to subsumption through the semi-unification problem, our type constraint problem corresponds to weak subsumption of feature graphs in linguistics. The decidability problem for \WhatsIt for feature graphs has been settled by D\"orre~\cite{Doerre:WeakSubsumption:94}. \nocite{RuppRosnerJohnson:94} In contrast to D\"orre's, our algorithm is fully incremental and does not refer to finite state automata. Our algorithm also is a lot more flexible. It allows a number of extensions (records, sorts, disjunctive types, type declarations, and others) which make it suitable for type inference of a full-fledged programming language.