 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBankerToolBench: Evaluating AI Agents in End-to-End Investment Banking Workflows
Apr 13, 2026Existing AI benchmarks lack the fidelity to assess economically meaningful progress on professional workflows. To evaluate frontier AI agents in a high-value, labor-intensive profession, we introduce BankerToolBench (BTB): an open-source benchmark of end-to-end analytical workflows routinely performed by junior investment bankers. To develop an ecologically valid benchmark grounded in representative work environments, we collaborated with 502 investment bankers from leading firms. BTB requires agents to execute senior banker requests by navigating data rooms, using industry tools (market data platform, SEC filings database), and generating multi-file deliverables--including Excel financial models, PowerPoint pitch decks, and PDF/Word reports. Completing a BTB task takes bankers up to 21 hours, underscoring the economic stakes of successfully delegating this work to AI. BTB enables automated evaluation of any LLM or agent, scoring deliverables against 100+ rubric criteria defined by veteran investment bankers to capture stakeholder utility. Testing 9 frontier models, we find that even the best-performing model (GPT-5.4) fails nearly half of the rubric criteria and bankers rate 0% of its outputs as client-ready. Our failure analysis reveals key obstacles (such as breakdowns in cross-artifact consistency) and improvement directions for agentic AI in high-stakes professional workflows.
An Imperfect Verifier is Good Enough: Learning with Noisy Rewards
Apr 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a prominent method for post-training Large Language Models (LLMs). However, verifiers are rarely error-free; even deterministic checks can be inaccurate, and the growing dependence on model-based judges exacerbates the issue. The extent to which RLVR is robust to such noise and the verifier accuracy required for effective training remain unresolved questions. We investigate these questions in the domains of code generation and scientific reasoning by introducing noise into RL training. Noise rates up to 15% yield peak validation accuracy within 2 percentage points of the clean baseline. These findings are consistent across controlled and model-based noise types, three model families (Qwen3, GLM4, Llama 3.1), and model sizes from 4B to 9B. Overall, the results indicate that imperfect verification does not constitute a fundamental barrier to RLVR. Furthermore, our findings suggest that practitioners should prioritize moderate accuracy with high precision over perfect verification.
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
Apr 08, 2021

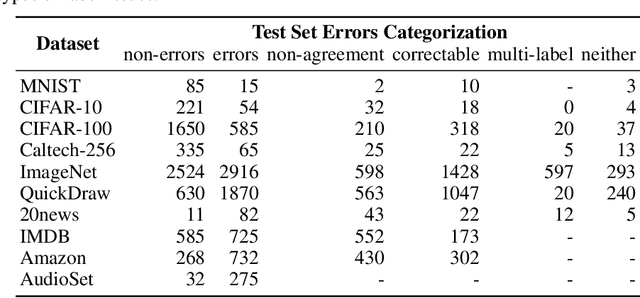
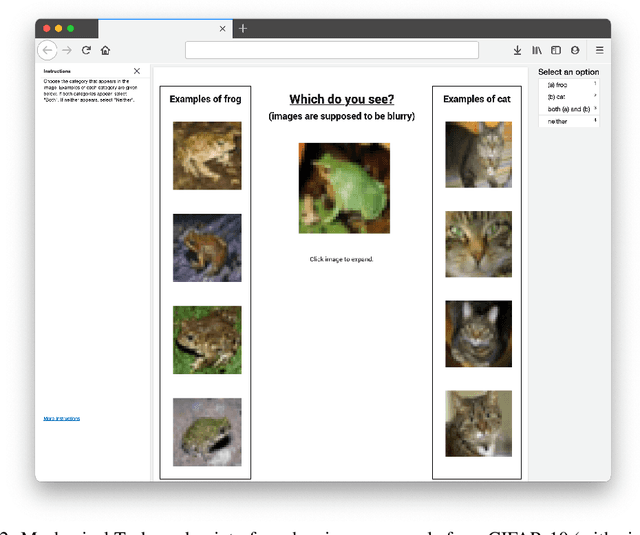
We algorithmically identify label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets, and subsequently study the potential for these label errors to affect benchmark results. Errors in test sets are numerous and widespread: we estimate an average of 3.4% errors across the 10 datasets, where for example 2916 label errors comprise 6% of the ImageNet validation set. Putative label errors are found using confident learning and then human-validated via crowdsourcing (54% of the algorithmically-flagged candidates are indeed erroneously labeled). Surprisingly, we find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data. For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. On CIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by 5%. Traditionally, ML practitioners choose which model to deploy based on test accuracy -- our findings advise caution here, proposing that judging models over correctly labeled test sets may be more useful, especially for noisy real-world datasets.
On Evaluating Adversarial Robustness
Feb 20, 2019Correctly evaluating defenses against adversarial examples has proven to be extremely difficult. Despite the significant amount of recent work attempting to design defenses that withstand adaptive attacks, few have succeeded; most papers that propose defenses are quickly shown to be incorrect. We believe a large contributing factor is the difficulty of performing security evaluations. In this paper, we discuss the methodological foundations, review commonly accepted best practices, and suggest new methods for evaluating defenses to adversarial examples. We hope that both researchers developing defenses as well as readers and reviewers who wish to understand the completeness of an evaluation consider our advice in order to avoid common pitfalls.
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Jul 31, 2018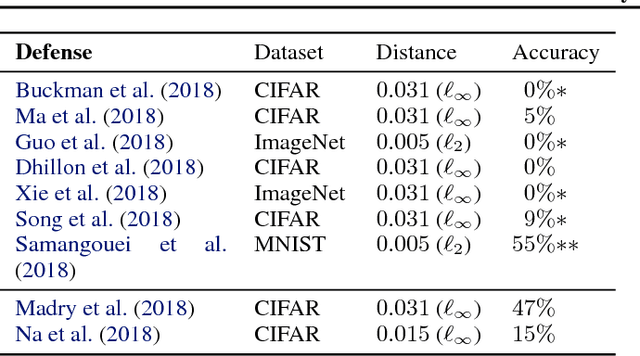
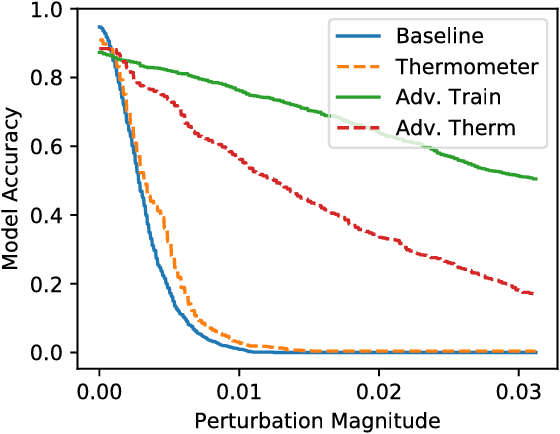

We identify obfuscated gradients, a kind of gradient masking, as a phenomenon that leads to a false sense of security in defenses against adversarial examples. While defenses that cause obfuscated gradients appear to defeat iterative optimization-based attacks, we find defenses relying on this effect can be circumvented. We describe characteristic behaviors of defenses exhibiting the effect, and for each of the three types of obfuscated gradients we discover, we develop attack techniques to overcome it. In a case study, examining non-certified white-box-secure defenses at ICLR 2018, we find obfuscated gradients are a common occurrence, with 7 of 9 defenses relying on obfuscated gradients. Our new attacks successfully circumvent 6 completely, and 1 partially, in the original threat model each paper considers.
Evaluating and Understanding the Robustness of Adversarial Logit Pairing
Jul 26, 2018
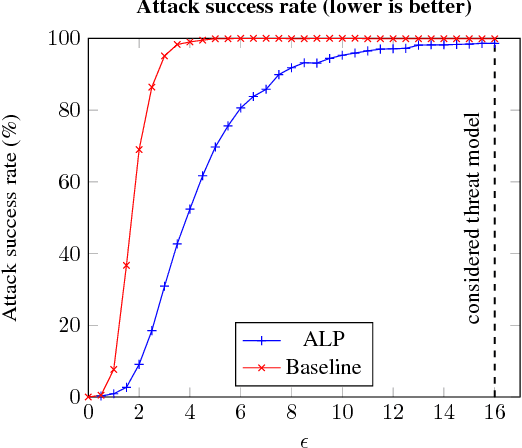

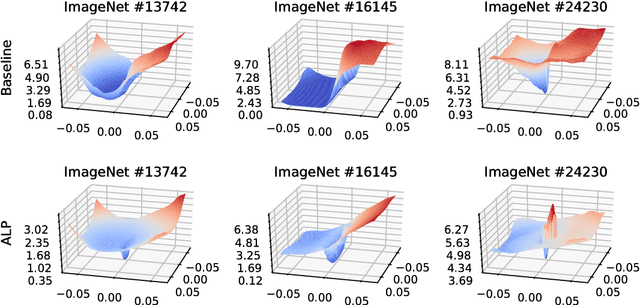
We evaluate the robustness of Adversarial Logit Pairing, a recently proposed defense against adversarial examples. We find that a network trained with Adversarial Logit Pairing achieves 0.6% accuracy in the threat model in which the defense is considered. We provide a brief overview of the defense and the threat models/claims considered, as well as a discussion of the methodology and results of our attack, which may offer insights into the reasons underlying the vulnerability of ALP to adversarial attack.
Black-box Adversarial Attacks with Limited Queries and Information
Jul 11, 2018
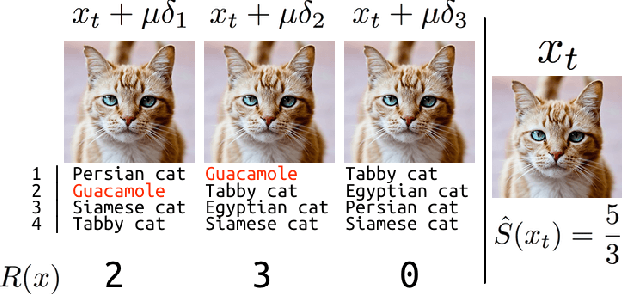

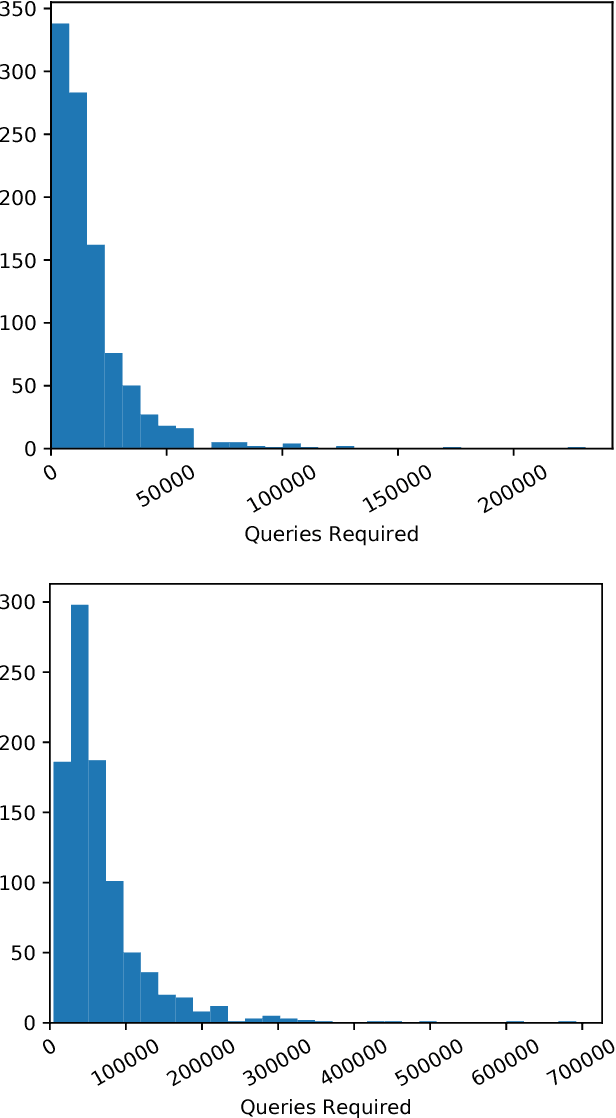
Current neural network-based classifiers are susceptible to adversarial examples even in the black-box setting, where the attacker only has query access to the model. In practice, the threat model for real-world systems is often more restrictive than the typical black-box model where the adversary can observe the full output of the network on arbitrarily many chosen inputs. We define three realistic threat models that more accurately characterize many real-world classifiers: the query-limited setting, the partial-information setting, and the label-only setting. We develop new attacks that fool classifiers under these more restrictive threat models, where previous methods would be impractical or ineffective. We demonstrate that our methods are effective against an ImageNet classifier under our proposed threat models. We also demonstrate a targeted black-box attack against a commercial classifier, overcoming the challenges of limited query access, partial information, and other practical issues to break the Google Cloud Vision API.
Synthesizing Robust Adversarial Examples
Jun 07, 2018
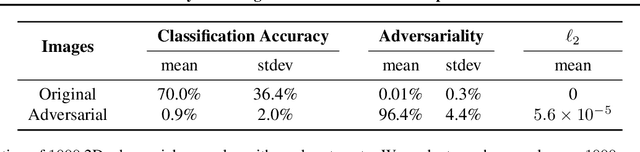

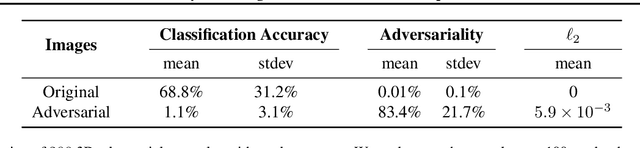
Standard methods for generating adversarial examples for neural networks do not consistently fool neural network classifiers in the physical world due to a combination of viewpoint shifts, camera noise, and other natural transformations, limiting their relevance to real-world systems. We demonstrate the existence of robust 3D adversarial objects, and we present the first algorithm for synthesizing examples that are adversarial over a chosen distribution of transformations. We synthesize two-dimensional adversarial images that are robust to noise, distortion, and affine transformation. We apply our algorithm to complex three-dimensional objects, using 3D-printing to manufacture the first physical adversarial objects. Our results demonstrate the existence of 3D adversarial objects in the physical world.
On the Robustness of the CVPR 2018 White-Box Adversarial Example Defenses
Apr 10, 2018
Neural networks are known to be vulnerable to adversarial examples. In this note, we evaluate the two white-box defenses that appeared at CVPR 2018 and find they are ineffective: when applying existing techniques, we can reduce the accuracy of the defended models to 0%.
Query-Efficient Black-box Adversarial Examples (superceded)
Apr 06, 2018


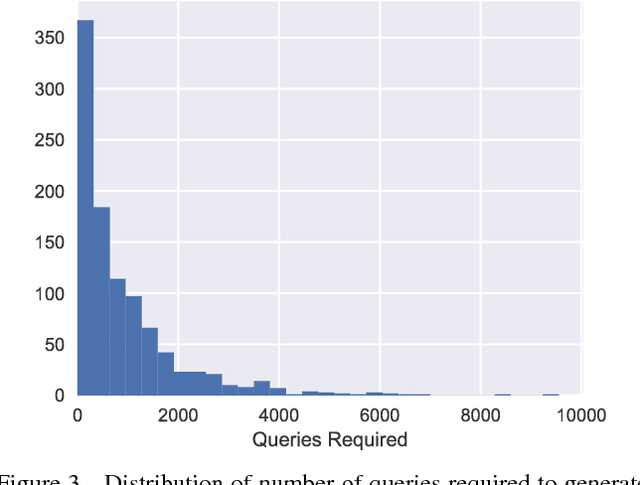
Note that this paper is superceded by "Black-Box Adversarial Attacks with Limited Queries and Information." Current neural network-based image classifiers are susceptible to adversarial examples, even in the black-box setting, where the attacker is limited to query access without access to gradients. Previous methods --- substitute networks and coordinate-based finite-difference methods --- are either unreliable or query-inefficient, making these methods impractical for certain problems. We introduce a new method for reliably generating adversarial examples under more restricted, practical black-box threat models. First, we apply natural evolution strategies to perform black-box attacks using two to three orders of magnitude fewer queries than previous methods. Second, we introduce a new algorithm to perform targeted adversarial attacks in the partial-information setting, where the attacker only has access to a limited number of target classes. Using these techniques, we successfully perform the first targeted adversarial attack against a commercially deployed machine learning system, the Google Cloud Vision API, in the partial information setting.