 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
Apr 08, 2021

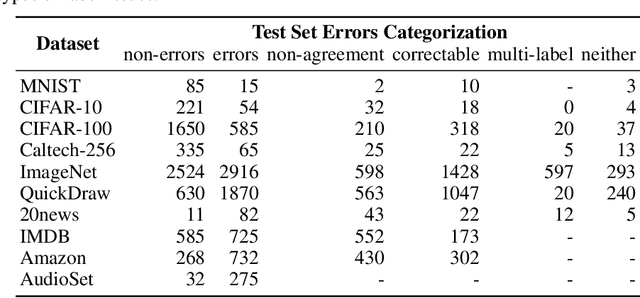
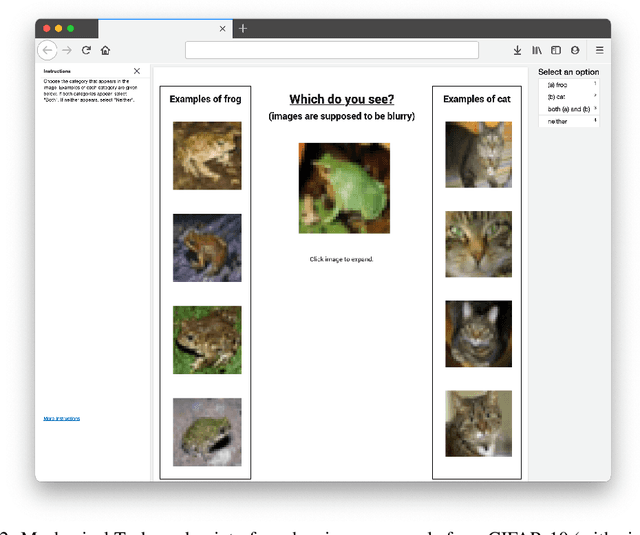
We algorithmically identify label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets, and subsequently study the potential for these label errors to affect benchmark results. Errors in test sets are numerous and widespread: we estimate an average of 3.4% errors across the 10 datasets, where for example 2916 label errors comprise 6% of the ImageNet validation set. Putative label errors are found using confident learning and then human-validated via crowdsourcing (54% of the algorithmically-flagged candidates are indeed erroneously labeled). Surprisingly, we find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data. For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. On CIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by 5%. Traditionally, ML practitioners choose which model to deploy based on test accuracy -- our findings advise caution here, proposing that judging models over correctly labeled test sets may be more useful, especially for noisy real-world datasets.
Conditional Rap Lyrics Generation with Denoising Autoencoders
Apr 08, 2020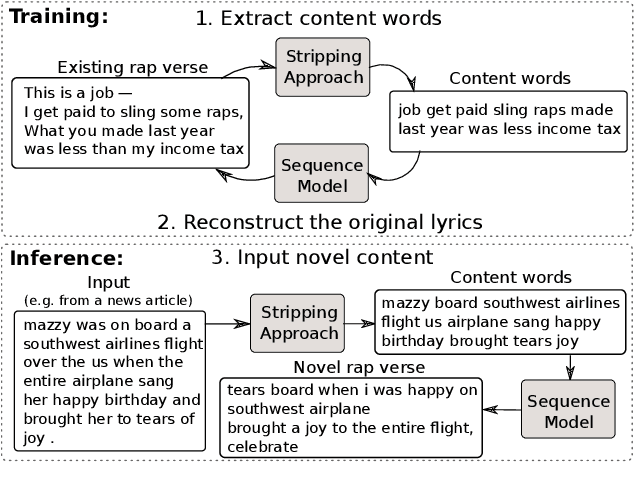
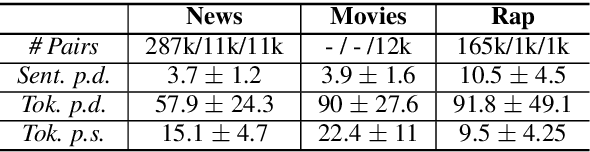
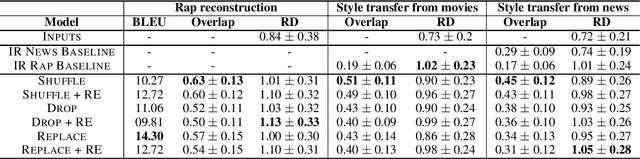
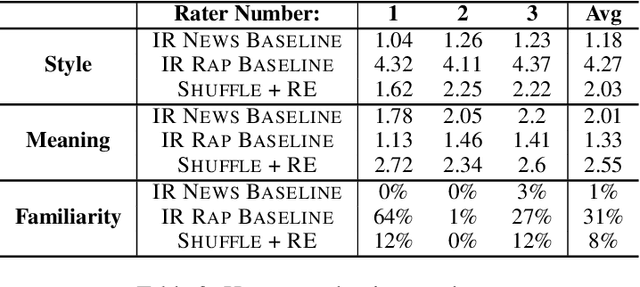
We develop a method for automatically synthesizing a rap verse given an input text written in another form, such as a summary of a news article. Our approach is to train a Transformer-based denoising autoencoder to reconstruct rap lyrics from content words. We study three different approaches for automatically stripping content words that convey the essential meaning of the lyrics. Moreover, we propose a BERT-based paraphrasing scheme for rhyme enhancement and show that it increases the average rhyme density of the lyrics by 10%. Experimental results on three diverse input domains -- existing rap lyrics, news, and movie plot summaries -- show that our method is capable of generating coherent and technically fluent rap verses that preserve the input content words. Human evaluation demonstrates that our approach gives a good trade-off between content preservation and style transfer compared to a strong information retrieval baseline.
Comment Ranking Diversification in Forum Discussions
Feb 27, 2020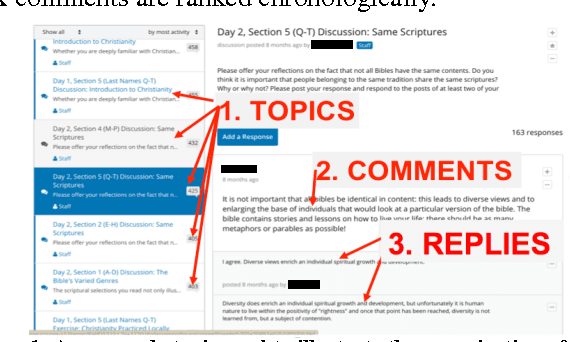
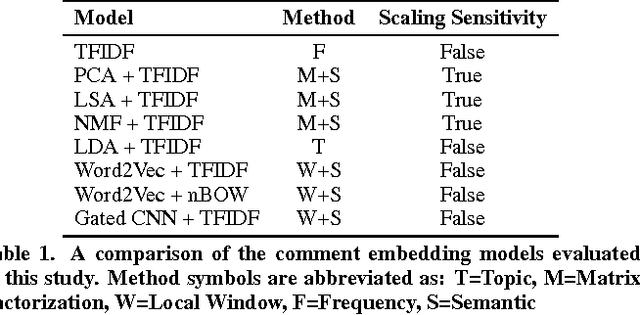

Viewing consumption of discussion forums with hundreds or more comments depends on ranking because most users only view top-ranked comments. When comments are ranked by an ordered score (e.g. number of replies or up-votes) without adjusting for semantic similarity of near-ranked comments, top-ranked comments are more likely to emphasize the majority opinion and incur redundancy. In this paper, we propose a top K comment diversification re-ranking model using Maximal Marginal Relevance (MMR) and evaluate its impact in three categories: (1) semantic diversity, (2) inclusion of the semantics of lower-ranked comments, and (3) redundancy, within the context of a HarvardX course discussion forum. We conducted a double-blind, small-scale evaluation experiment requiring subjects to select between the top 5 comments of a diversified ranking and a baseline ranking ordered by score. For three subjects, across 100 trials, subjects selected the diversified (75% score, 25% diversification) ranking as significantly (1) more diverse, (2) more inclusive, and (3) less redundant. Within each category, inter-rater reliability showed moderate consistency, with typical Cohen-Kappa scores near 0.2. Our findings suggest that our model improves (1) diversification, (2) inclusion, and (3) redundancy, among top K ranked comments in online discussion forums.
* 5 pages, 7 figures, published in Learning @ Scale, 2017
Confident Learning: Estimating Uncertainty in Dataset Labels
Oct 31, 2019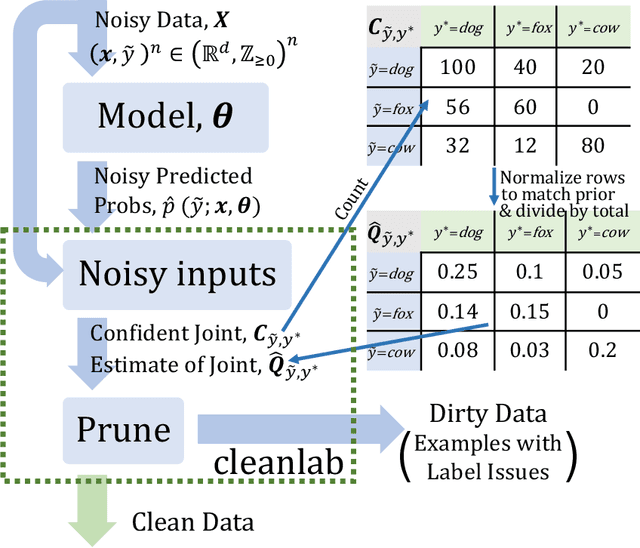



Learning exists in the context of data, yet notions of $\textit{confidence}$ typically focus on model predictions, not label quality. Confident learning (CL) has emerged as an approach for characterizing, identifying, and learning with noisy labels in datasets, based on the principles of pruning noisy data, counting to estimate noise, and ranking examples to train with confidence. Here, we generalize CL, building on the assumption of a classification noise process, to directly estimate the joint distribution between noisy (given) labels and uncorrupted (unknown) labels. This generalized CL, open-sourced as $\texttt{cleanlab}$, is provably consistent under reasonable conditions, and experimentally performant on ImageNet and CIFAR, outperforming recent approaches, e.g. MentorNet, by $30\%$ or more, when label noise is non-uniform. $\texttt{cleanlab}$ also quantifies ontological class overlap, and can increase model accuracy (e.g. ResNet) by providing clean data for training.
Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels
Aug 09, 2017



Noisy PN learning is the problem of binary classification when training examples may be mislabeled (flipped) uniformly with noise rate rho1 for positive examples and rho0 for negative examples. We propose Rank Pruning (RP) to solve noisy PN learning and the open problem of estimating the noise rates, i.e. the fraction of wrong positive and negative labels. Unlike prior solutions, RP is time-efficient and general, requiring O(T) for any unrestricted choice of probabilistic classifier with T fitting time. We prove RP has consistent noise estimation and equivalent expected risk as learning with uncorrupted labels in ideal conditions, and derive closed-form solutions when conditions are non-ideal. RP achieves state-of-the-art noise estimation and F1, error, and AUC-PR for both MNIST and CIFAR datasets, regardless of the amount of noise and performs similarly impressively when a large portion of training examples are noise drawn from a third distribution. To highlight, RP with a CNN classifier can predict if an MNIST digit is a "one"or "not" with only 0.25% error, and 0.46 error across all digits, even when 50% of positive examples are mislabeled and 50% of observed positive labels are mislabeled negative examples.