 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Rap Lyrics Generation with Denoising Autoencoders
Apr 08, 2020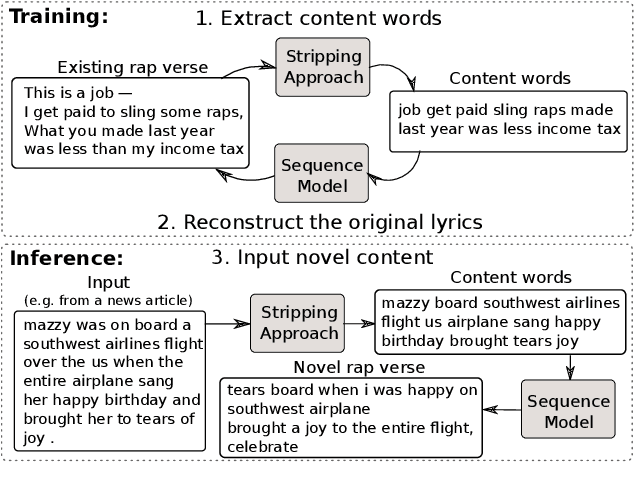
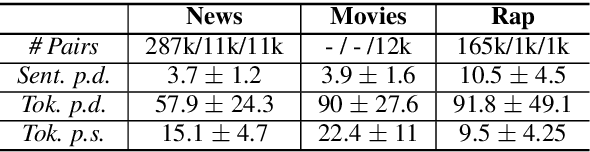
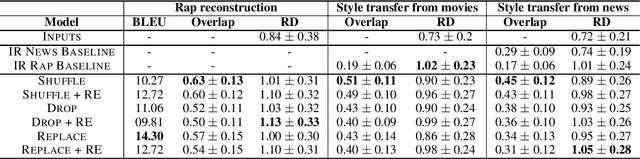
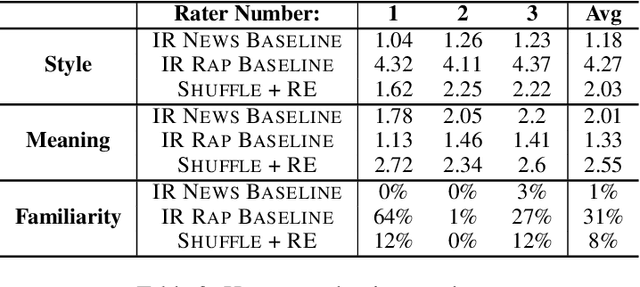
We develop a method for automatically synthesizing a rap verse given an input text written in another form, such as a summary of a news article. Our approach is to train a Transformer-based denoising autoencoder to reconstruct rap lyrics from content words. We study three different approaches for automatically stripping content words that convey the essential meaning of the lyrics. Moreover, we propose a BERT-based paraphrasing scheme for rhyme enhancement and show that it increases the average rhyme density of the lyrics by 10%. Experimental results on three diverse input domains -- existing rap lyrics, news, and movie plot summaries -- show that our method is capable of generating coherent and technically fluent rap verses that preserve the input content words. Human evaluation demonstrates that our approach gives a good trade-off between content preservation and style transfer compared to a strong information retrieval baseline.
Exploiting Synchronized Lyrics And Vocal Features For Music Emotion Detection
Jan 15, 2019

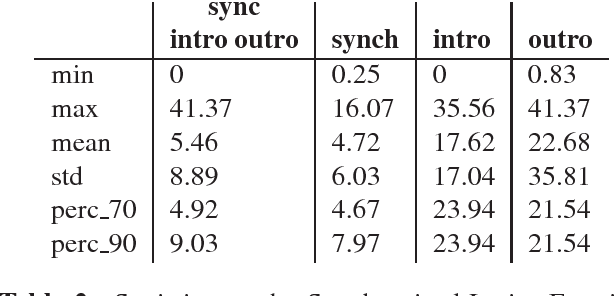
One of the key points in music recommendation is authoring engaging playlists according to sentiment and emotions. While previous works were mostly based on audio for music discovery and playlists generation, we take advantage of our synchronized lyrics dataset to combine text representations and music features in a novel way; we therefore introduce the Synchronized Lyrics Emotion Dataset. Unlike other approaches that randomly exploited the audio samples and the whole text, our data is split according to the temporal information provided by the synchronization between lyrics and audio. This work shows a comparison between text-based and audio-based deep learning classification models using different techniques from Natural Language Processing and Music Information Retrieval domains. From the experiments on audio we conclude that using vocals only, instead of the whole audio data improves the overall performances of the audio classifier. In the lyrics experiments we exploit the state-of-the-art word representations applied to the main Deep Learning architectures available in literature. In our benchmarks the results show how the Bilinear LSTM classifier with Attention based on fastText word embedding performs better than the CNN applied on audio.