 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter-Level Translation with Self-attention
Apr 30, 2020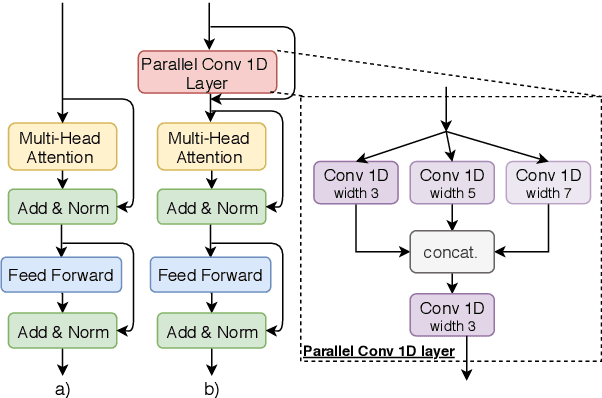
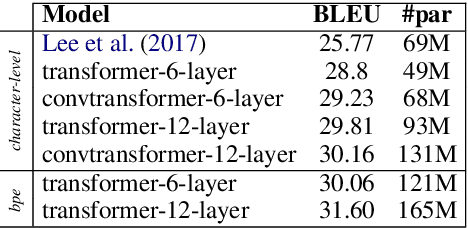
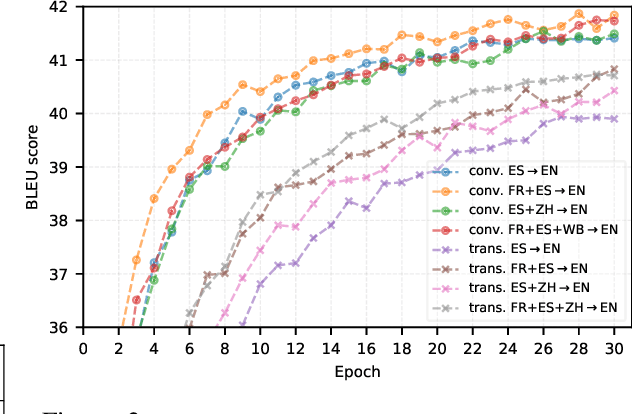
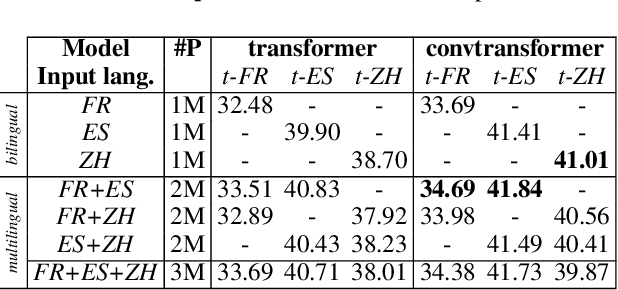
We explore the suitability of self-attention models for character-level neural machine translation. We test the standard transformer model, as well as a novel variant in which the encoder block combines information from nearby characters using convolutions. We perform extensive experiments on WMT and UN datasets, testing both bilingual and multilingual translation to English using up to three input languages (French, Spanish, and Chinese). Our transformer variant consistently outperforms the standard transformer at the character-level and converges faster while learning more robust character-level alignments.
Conditional Rap Lyrics Generation with Denoising Autoencoders
Apr 08, 2020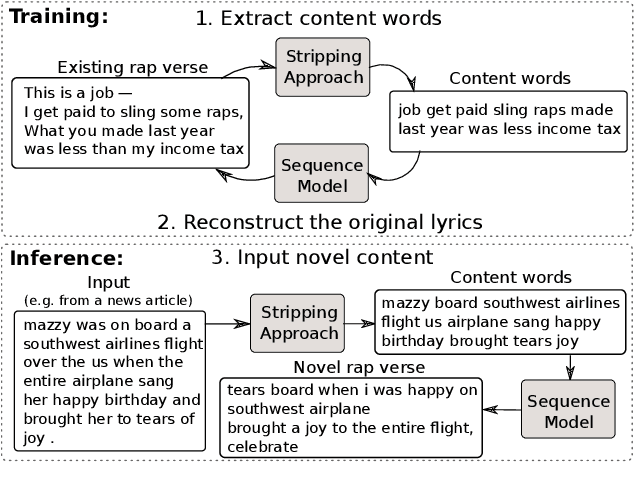
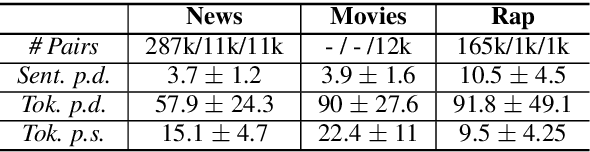
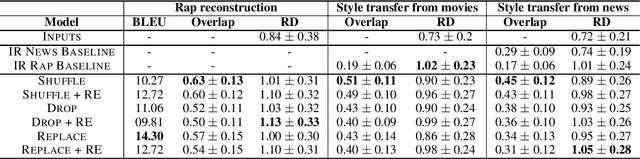
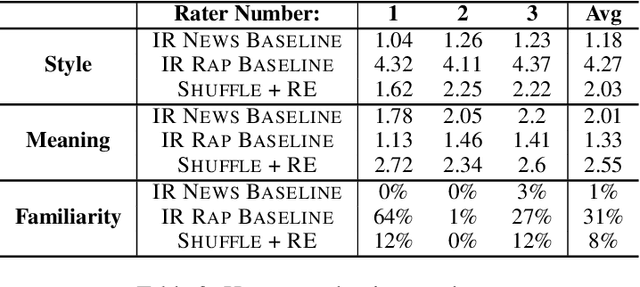
We develop a method for automatically synthesizing a rap verse given an input text written in another form, such as a summary of a news article. Our approach is to train a Transformer-based denoising autoencoder to reconstruct rap lyrics from content words. We study three different approaches for automatically stripping content words that convey the essential meaning of the lyrics. Moreover, we propose a BERT-based paraphrasing scheme for rhyme enhancement and show that it increases the average rhyme density of the lyrics by 10%. Experimental results on three diverse input domains -- existing rap lyrics, news, and movie plot summaries -- show that our method is capable of generating coherent and technically fluent rap verses that preserve the input content words. Human evaluation demonstrates that our approach gives a good trade-off between content preservation and style transfer compared to a strong information retrieval baseline.
Abstractive Document Summarization without Parallel Data
Jul 30, 2019
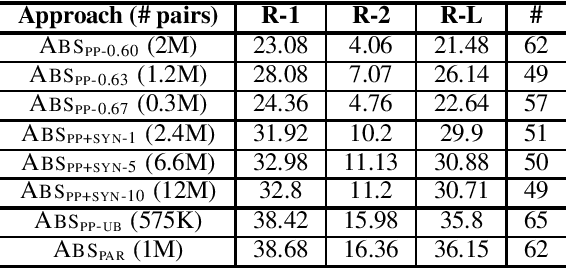
Abstractive summarization typically relies on large collections of paired articles and summaries, however parallel data is scarce and costly to obtain. We develop an abstractive summarization system that only relies on having access to large collections of example summaries and non-matching articles. Our approach consists of an unsupervised sentence extractor, which selects salient sentences to include in the final summary; as well as a sentence abstractor, trained using pseudo-parallel and synthetic data, which paraphrases each of the extracted sentences. We achieve promising results on the CNN/DailyMail benchmark without relying on any article-summary pairs.
Summary Refinement through Denoising
Jul 25, 2019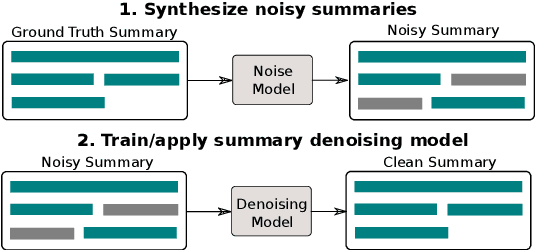
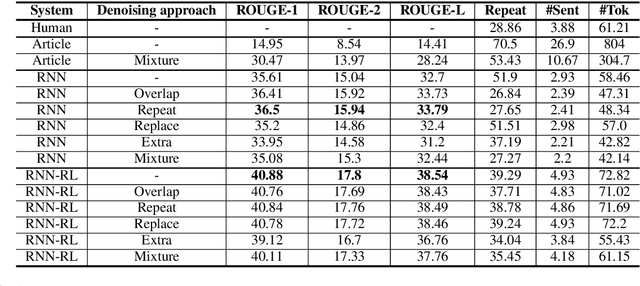
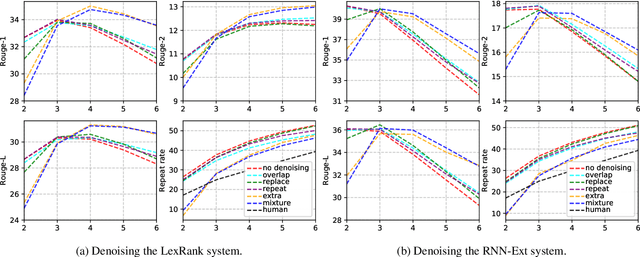

We propose a simple method for post-processing the outputs of a text summarization system in order to refine its overall quality. Our approach is to train text-to-text rewriting models to correct information redundancy errors that may arise during summarization. We train on synthetically generated noisy summaries, testing three different types of noise that introduce out-of-context information within each summary. When applied on top of extractive and abstractive summarization baselines, our summary denoising models yield metric improvements while reducing redundancy.
Large-scale Hierarchical Alignment for Author Style Transfer
Oct 18, 2018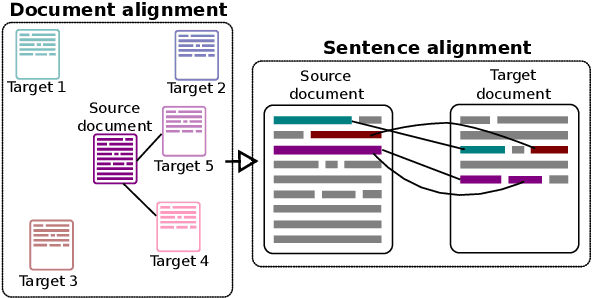



We propose a simple method for extracting pseudo-parallel monolingual sentence pairs from comparable corpora representative of two different author styles, such as scientific papers and Wikipedia articles. Our approach is to first hierarchically search for nearest document neighbours and then for sentences therein. We demonstrate the effectiveness of our method through automatic and extrinsic evaluation on two tasks: text simplification from Wikipedia to Simple Wikipedia and style transfer from scientific journal articles to press releases. We show that pseudo-parallel sentences extracted with our method not only improve existing parallel data, but can even lead to competitive performance on their own.
Character-level Chinese-English Translation through ASCII Encoding
Aug 27, 2018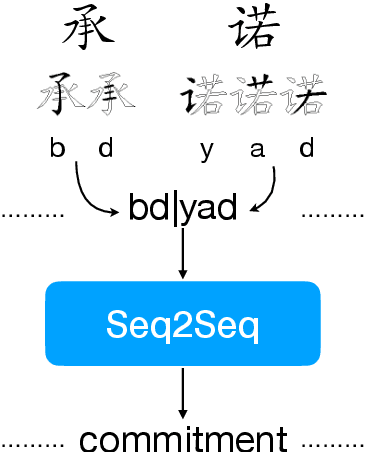
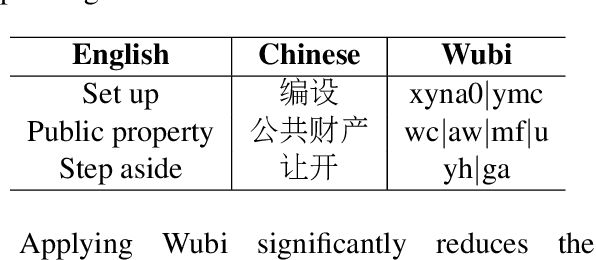
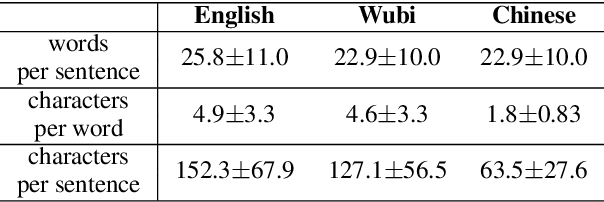
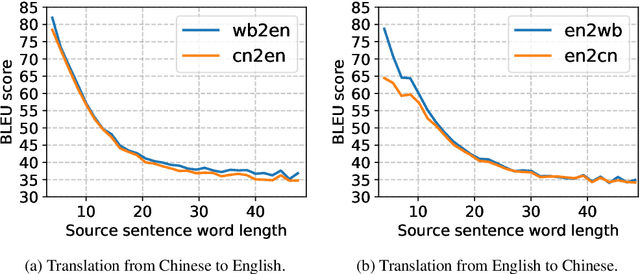
Character-level Neural Machine Translation (NMT) models have recently achieved impressive results on many language pairs. They mainly do well for Indo-European language pairs, where the languages share the same writing system. However, for translating between Chinese and English, the gap between the two different writing systems poses a major challenge because of a lack of systematic correspondence between the individual linguistic units. In this paper, we enable character-level NMT for Chinese, by breaking down Chinese characters into linguistic units similar to that of Indo-European languages. We use the Wubi encoding scheme, which preserves the original shape and semantic information of the characters, while also being reversible. We show promising results from training Wubi-based models on the character- and subword-level with recurrent as well as convolutional models.
Data-driven Summarization of Scientific Articles
Apr 24, 2018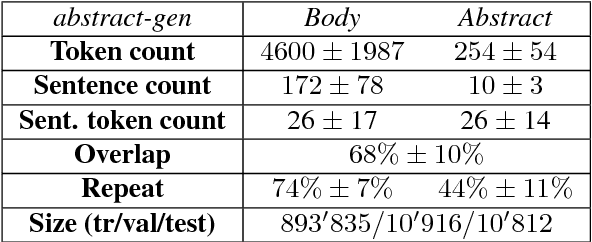
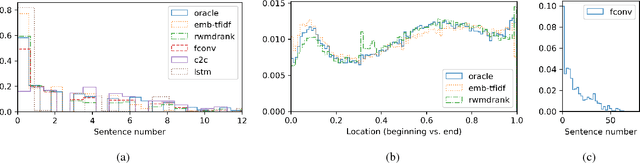
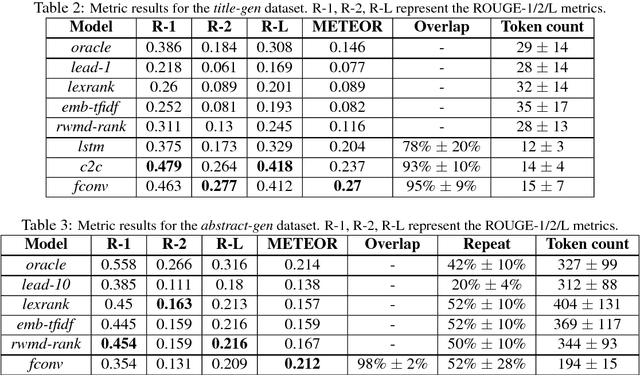
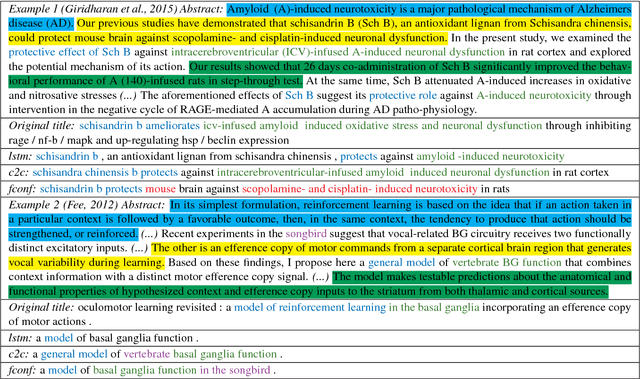
Data-driven approaches to sequence-to-sequence modelling have been successfully applied to short text summarization of news articles. Such models are typically trained on input-summary pairs consisting of only a single or a few sentences, partially due to limited availability of multi-sentence training data. Here, we propose to use scientific articles as a new milestone for text summarization: large-scale training data come almost for free with two types of high-quality summaries at different levels - the title and the abstract. We generate two novel multi-sentence summarization datasets from scientific articles and test the suitability of a wide range of existing extractive and abstractive neural network-based summarization approaches. Our analysis demonstrates that scientific papers are suitable for data-driven text summarization. Our results could serve as valuable benchmarks for scaling sequence-to-sequence models to very long sequences.