 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
Paper and Code


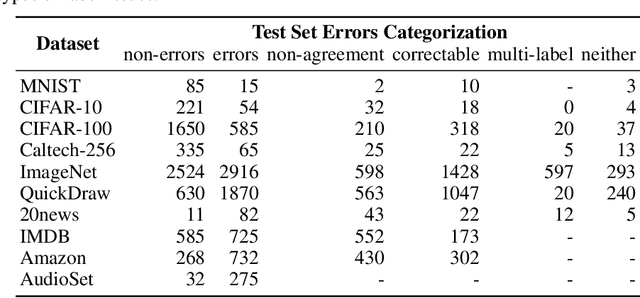
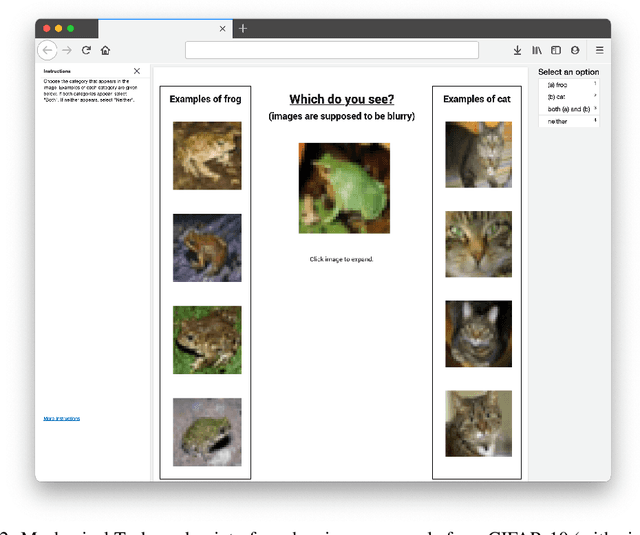
We algorithmically identify label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets, and subsequently study the potential for these label errors to affect benchmark results. Errors in test sets are numerous and widespread: we estimate an average of 3.4% errors across the 10 datasets, where for example 2916 label errors comprise 6% of the ImageNet validation set. Putative label errors are found using confident learning and then human-validated via crowdsourcing (54% of the algorithmically-flagged candidates are indeed erroneously labeled). Surprisingly, we find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data. For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. On CIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by 5%. Traditionally, ML practitioners choose which model to deploy based on test accuracy -- our findings advise caution here, proposing that judging models over correctly labeled test sets may be more useful, especially for noisy real-world datasets.