 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident Learning: Estimating Uncertainty in Dataset Labels
Paper and Code
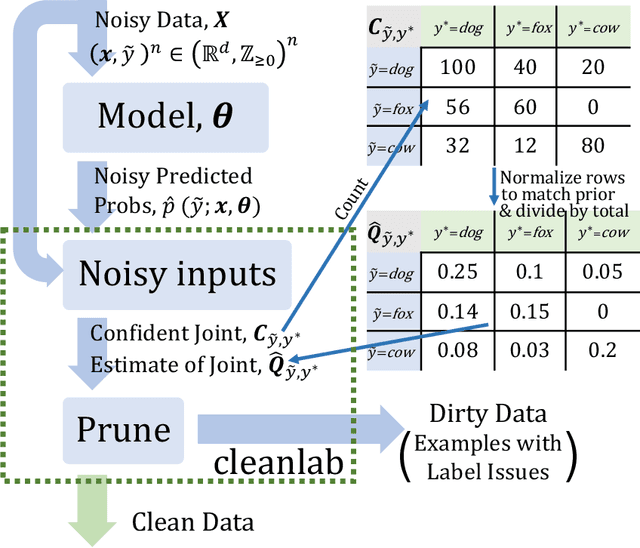



Learning exists in the context of data, yet notions of $\textit{confidence}$ typically focus on model predictions, not label quality. Confident learning (CL) has emerged as an approach for characterizing, identifying, and learning with noisy labels in datasets, based on the principles of pruning noisy data, counting to estimate noise, and ranking examples to train with confidence. Here, we generalize CL, building on the assumption of a classification noise process, to directly estimate the joint distribution between noisy (given) labels and uncorrupted (unknown) labels. This generalized CL, open-sourced as $\texttt{cleanlab}$, is provably consistent under reasonable conditions, and experimentally performant on ImageNet and CIFAR, outperforming recent approaches, e.g. MentorNet, by $30\%$ or more, when label noise is non-uniform. $\texttt{cleanlab}$ also quantifies ontological class overlap, and can increase model accuracy (e.g. ResNet) by providing clean data for training.