Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Understanding the Robustness of Adversarial Logit Pairing
Paper and Code

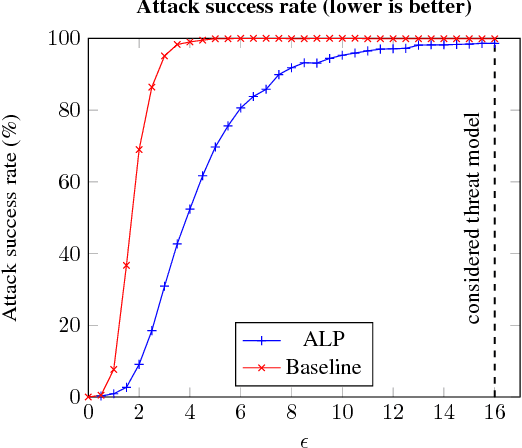

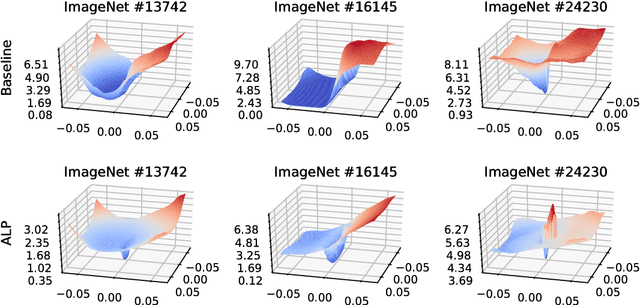
We evaluate the robustness of Adversarial Logit Pairing, a recently proposed defense against adversarial examples. We find that a network trained with Adversarial Logit Pairing achieves 0.6% accuracy in the threat model in which the defense is considered. We provide a brief overview of the defense and the threat models/claims considered, as well as a discussion of the methodology and results of our attack, which may offer insights into the reasons underlying the vulnerability of ALP to adversarial attack.
* Source code at
https://github.com/labsix/adversarial-logit-pairing-analysis
View paper on