 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA margin-based replacement for cross-entropy loss
Jan 21, 2025



Cross-entropy (CE) loss is the de-facto standard for training deep neural networks to perform classification. However, CE-trained deep neural networks struggle with robustness and generalisation issues. To alleviate these issues, we propose high error margin (HEM) loss, a variant of multi-class margin loss that overcomes the training issues of other margin-based losses. We evaluate HEM extensively on a range of architectures and datasets. We find that HEM loss is more effective than cross-entropy loss across a wide range of tasks: unknown class rejection, adversarial robustness, learning with imbalanced data, continual learning, and semantic segmentation (a pixel-level classification task). Despite all training hyper-parameters being chosen for CE loss, HEM is inferior to CE only in terms of clean accuracy and this difference is insignificant. We also compare HEM to specialised losses that have previously been proposed to improve performance on specific tasks. LogitNorm, a loss achieving state-of-the-art performance on unknown class rejection, produces similar performance to HEM for this task, but is much poorer for continual learning and semantic segmentation. Logit-adjusted loss, designed for imbalanced data, has superior results to HEM for that task, but performs more poorly on unknown class rejection and semantic segmentation. DICE, a popular loss for semantic segmentation, is inferior to HEM loss on all tasks, including semantic segmentation. Thus, HEM often out-performs specialised losses, and in contrast to them, is a general-purpose replacement for CE loss.
Comprehensive Assessment of the Performance of Deep Learning Classifiers Reveals a Surprising Lack of Robustness
Aug 08, 2023



Reliable and robust evaluation methods are a necessary first step towards developing machine learning models that are themselves robust and reliable. Unfortunately, current evaluation protocols typically used to assess classifiers fail to comprehensively evaluate performance as they tend to rely on limited types of test data, and ignore others. For example, using the standard test data fails to evaluate the predictions made by the classifier to samples from classes it was not trained on. On the other hand, testing with data containing samples from unknown classes fails to evaluate how well the classifier can predict the labels for known classes. This article advocates bench-marking performance using a wide range of different types of data and using a single metric that can be applied to all such data types to produce a consistent evaluation of performance. Using such a benchmark it is found that current deep neural networks, including those trained with methods that are believed to produce state-of-the-art robustness, are extremely vulnerable to making mistakes on certain types of data. This means that such models will be unreliable in real-world scenarios where they may encounter data from many different domains, and that they are insecure as they can easily be fooled into making the wrong decisions. It is hoped that these results will motivate the wider adoption of more comprehensive testing methods that will, in turn, lead to the development of more robust machine learning methods in the future. Code is available at: \url{https://codeberg.org/mwspratling/RobustnessEvaluation}
A three-dimensional approach to Visual Speech Recognition using Discrete Cosine Transforms
Sep 07, 2016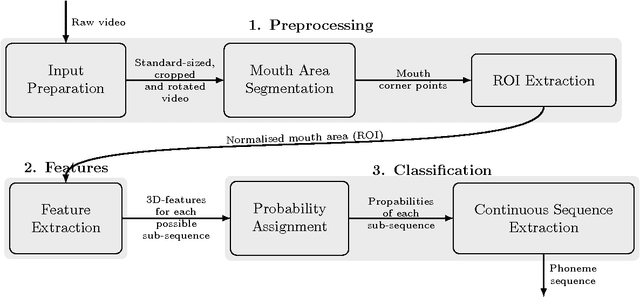


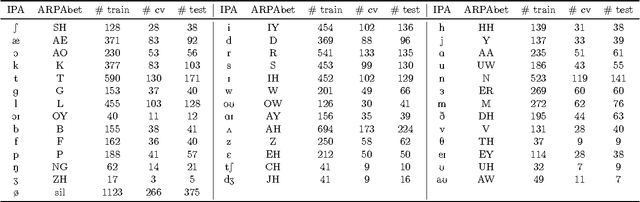
Visual speech recognition aims to identify the sequence of phonemes from continuous speech. Unlike the traditional approach of using 2D image feature extraction methods to derive features of each video frame separately, this paper proposes a new approach using a 3D (spatio-temporal) Discrete Cosine Transform to extract features of each feasible sub-sequence of an input video which are subsequently classified individually using Support Vector Machines and combined to find the most likely phoneme sequence using a tailor-made Hidden Markov Model. The algorithm is trained and tested on the VidTimit database to recognise sequences of phonemes as well as visemes (visual speech units). Furthermore, the system is extended with the training on phoneme or viseme pairs (biphones) to counteract the human speech ambiguity of co-articulation. The test set accuracy for the recognition of phoneme sequences is 20%, and the accuracy of viseme sequences is 39%. Both results improve the best values reported in other papers by approximately 2%. The contribution of the result is three-fold: Firstly, this paper is the first to show that 3D feature extraction methods can be applied to continuous sequence recognition tasks despite the unknown start positions and durations of each phoneme. Secondly, the result confirms that 3D feature extraction methods improve the accuracy compared to 2D features extraction methods. Thirdly, the paper is the first to specifically compare an otherwise identical method with and without using biphones, verifying that the usage of biphones has a positive impact on the result.