 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman face perception reflects inverse-generative and naturalistic discriminative objectives
May 12, 2026The perceptual representations supporting our ability to recognize faces remain a computational mystery. Deep neural networks offer mechanistic hypotheses for human face perception, but theoretically distinct models often make indistinguishable representational predictions for randomly sampled faces. To expose diagnostic differences among these hypotheses, we compared six neural network models sharing an architecture but trained on distinct tasks, using face pairs optimized to elicit contrasting model predictions ("controversial" pairs) alongside randomly sampled pairs. We tested model predictions against face-dissimilarity judgments from 864 human participants across stimulus sets differing in realism and pose variation. Models prioritizing high-level, invariant structures (trained via inverse rendering, face identification, or object classification) most robustly matched human judgments. Furthermore, models trained on natural images typically outperformed synthetic-trained counterparts. Together, these findings suggest that human face perception is shaped by mechanisms that infer latent causes of facial appearance, discount nuisance variation, and are tuned by natural image statistics.
Distinguishing representational geometries with controversial stimuli: Bayesian experimental design and its application to face dissimilarity judgments
Nov 28, 2022


Comparing representations of complex stimuli in neural network layers to human brain representations or behavioral judgments can guide model development. However, even qualitatively distinct neural network models often predict similar representational geometries of typical stimulus sets. We propose a Bayesian experimental design approach to synthesizing stimulus sets for adjudicating among representational models efficiently. We apply our method to discriminate among candidate neural network models of behavioral face dissimilarity judgments. Our results indicate that a neural network trained to invert a 3D-face-model graphics renderer is more human-aligned than the same architecture trained on identification, classification, or autoencoding. Our proposed stimulus synthesis objective is generally applicable to designing experiments to be analyzed by representational similarity analysis for model comparison.
Testing the limits of natural language models for predicting human language judgments
Apr 07, 2022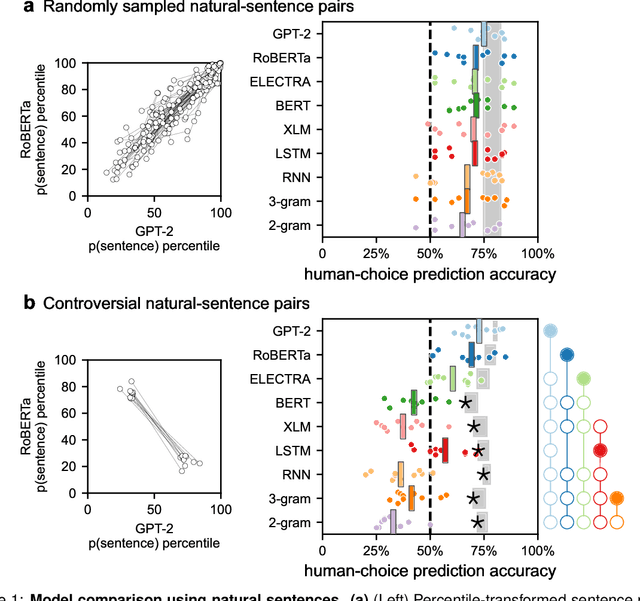
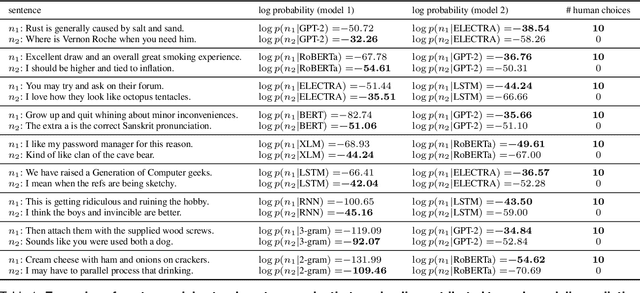
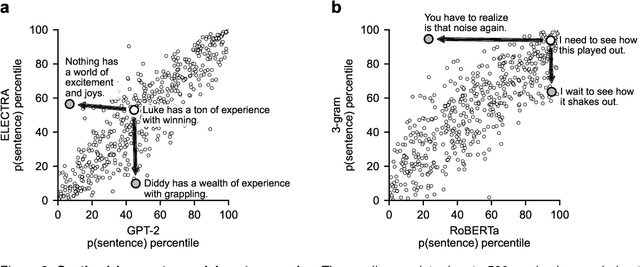
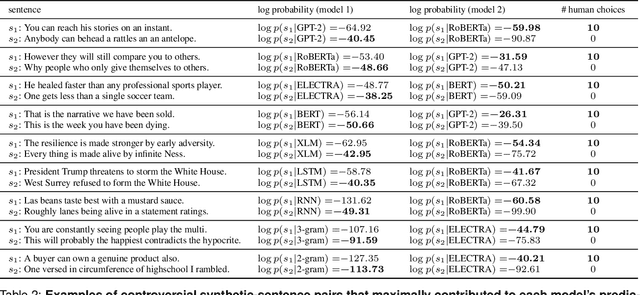
Neural network language models can serve as computational hypotheses about how humans process language. We compared the model-human consistency of diverse language models using a novel experimental approach: controversial sentence pairs. For each controversial sentence pair, two language models disagree about which sentence is more likely to occur in natural text. Considering nine language models (including n-gram, recurrent neural networks, and transformer models), we created hundreds of such controversial sentence pairs by either selecting sentences from a corpus or synthetically optimizing sentence pairs to be highly controversial. Human subjects then provided judgments indicating for each pair which of the two sentences is more likely. Controversial sentence pairs proved highly effective at revealing model failures and identifying models that aligned most closely with human judgments. The most human-consistent model tested was GPT-2, although experiments also revealed significant shortcomings of its alignment with human perception.
Controversial stimuli: pitting neural networks against each other as models of human recognition
Nov 21, 2019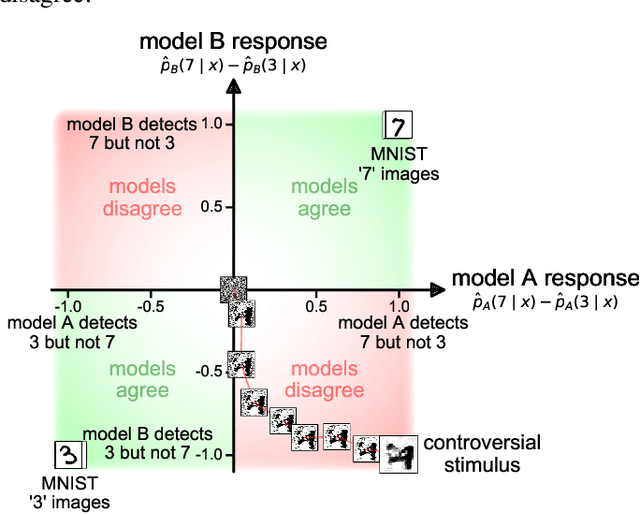
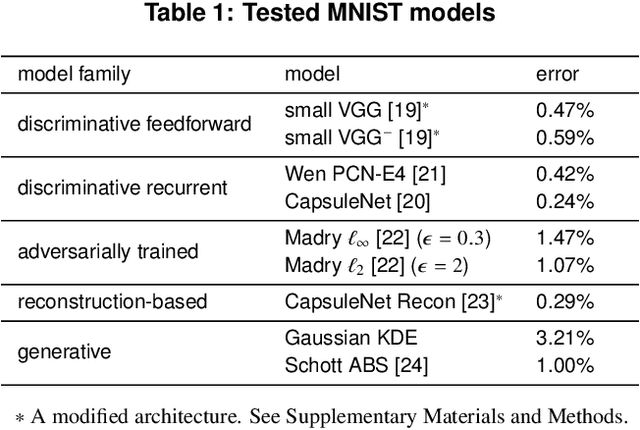
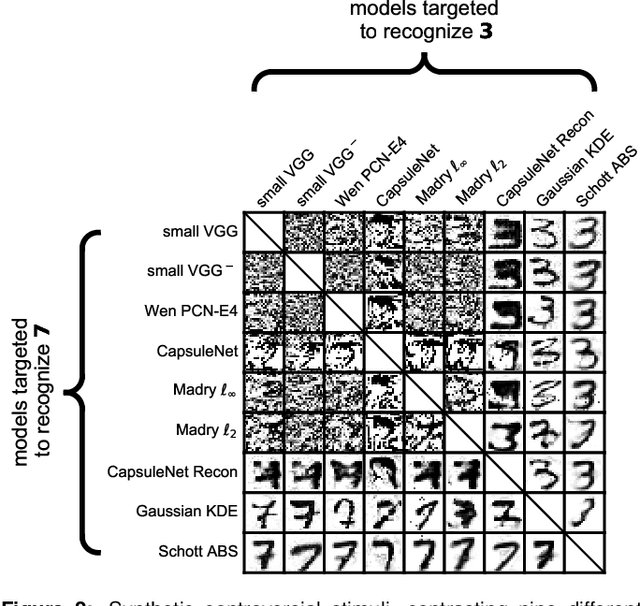
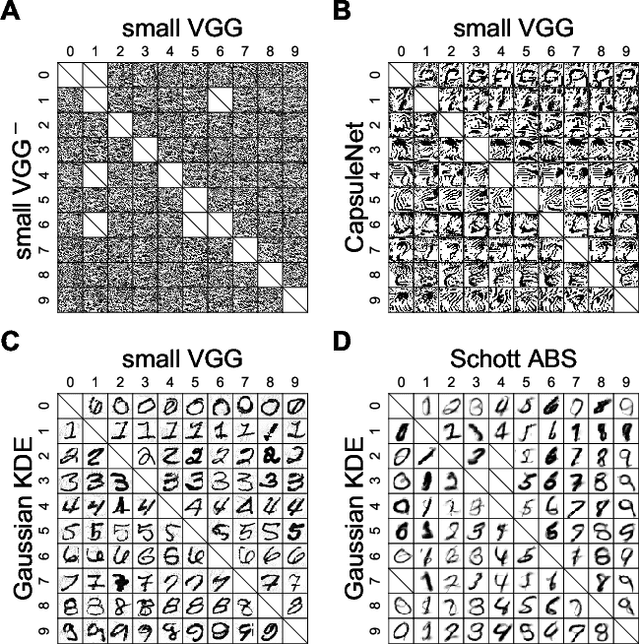
Distinct scientific theories can make similar predictions. To adjudicate between theories, we must design experiments for which the theories make distinct predictions. Here we consider the problem of comparing deep neural networks as models of human visual recognition. To efficiently determine which models better explain human responses, we synthesize controversial stimuli: images for which different models produce distinct responses. We tested nine different models, which employed different architectures and recognition algorithms, including discriminative and generative models, all trained to recognize handwritten digits (from the MNIST set of digit images). We synthesized controversial stimuli to maximize the disagreement among the models. Human subjects viewed hundreds of these stimuli and judged the probability of presence of each digit in each image. We quantified how accurately each model predicted the human judgements. We found that the generative models (which learn the distribution of images for each class) better predicted the human judgments than the discriminative models (which learn to directly map from images to labels). The best performing model was the generative Analysis-by-Synthesis model (based on variational autoencoders). However, a simpler generative model (based on Gaussian-kernel-density estimation) also performed better than each of the discriminative models. None of the candidate models fully explained the human responses. We discuss the advantages and limitations of controversial stimuli as an experimental paradigm and how they generalize and improve on adversarial examples as probes of discrepancies between models and human perception.
From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI
Jul 03, 2019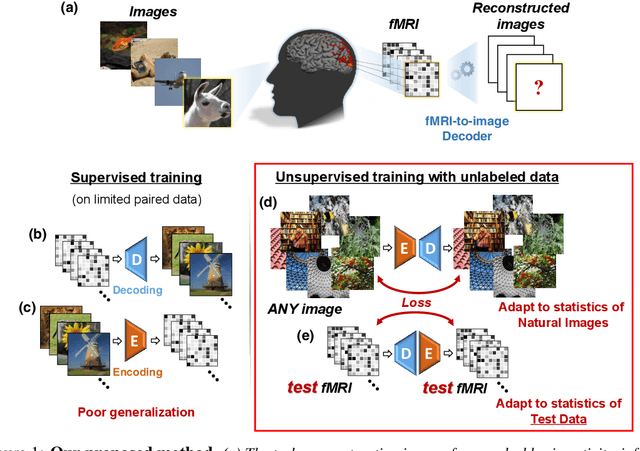
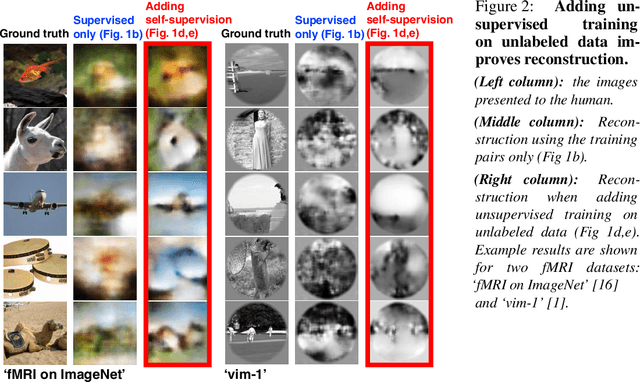
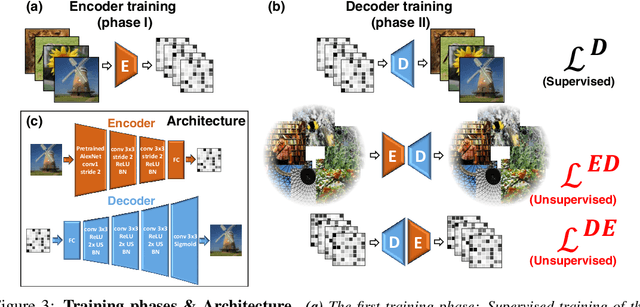
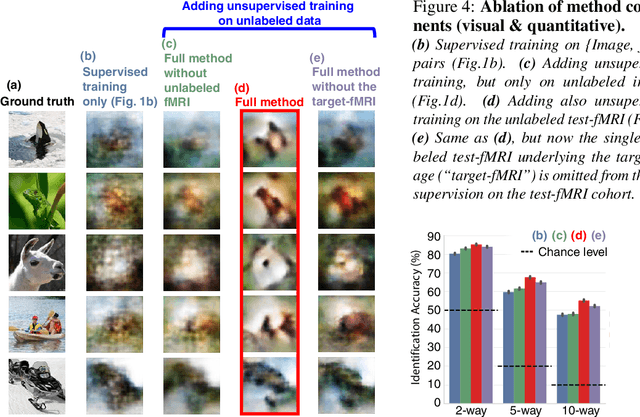
Reconstructing observed images from fMRI brain recordings is challenging. Unfortunately, acquiring sufficient "labeled" pairs of {Image, fMRI} (i.e., images with their corresponding fMRI responses) to span the huge space of natural images is prohibitive for many reasons. We present a novel approach which, in addition to the scarce labeled data (training pairs), allows to train fMRI-to-image reconstruction networks also on "unlabeled" data (i.e., images without fMRI recording, and fMRI recording without images). The proposed model utilizes both an Encoder network (image-to-fMRI) and a Decoder network (fMRI-to-image). Concatenating these two networks back-to-back (Encoder-Decoder & Decoder-Encoder) allows augmenting the training with both types of unlabeled data. Importantly, it allows training on the unlabeled test-fMRI data. This self-supervision adapts the reconstruction network to the new input test-data, despite its deviation from the statistics of the scarce training data.
Neural network models and deep learning - a primer for biologists
Mar 01, 2019


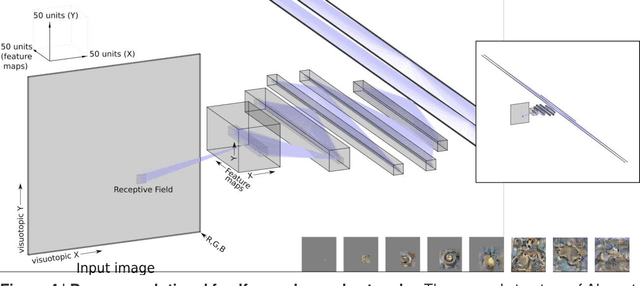
Originally inspired by neurobiology, deep neural network models have become a powerful tool of machine learning and artificial intelligence, where they are used to approximate functions and dynamics by learning from examples. Here we give a brief introduction to neural network models and deep learning for biologists. We introduce feedforward and recurrent networks and explain the expressive power of this modeling framework and the backpropagation algorithm for setting the parameters. Finally, we consider how deep neural networks might help us understand the brain's computations.
* 14 pages, 4 figures; added references, minor corrections