 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControversial stimuli: pitting neural networks against each other as models of human recognition
Paper and Code
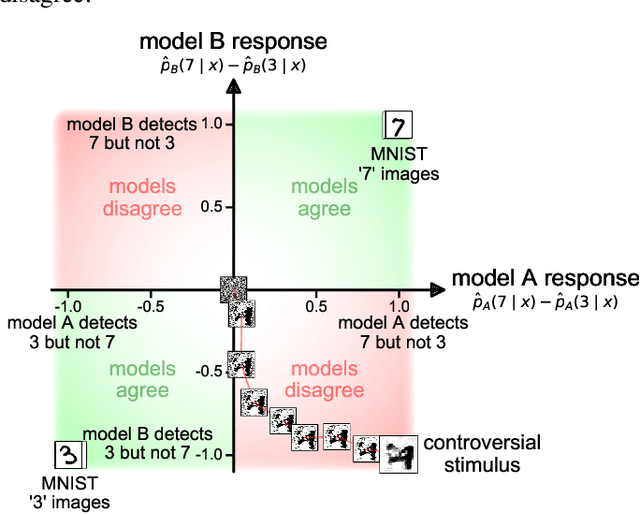
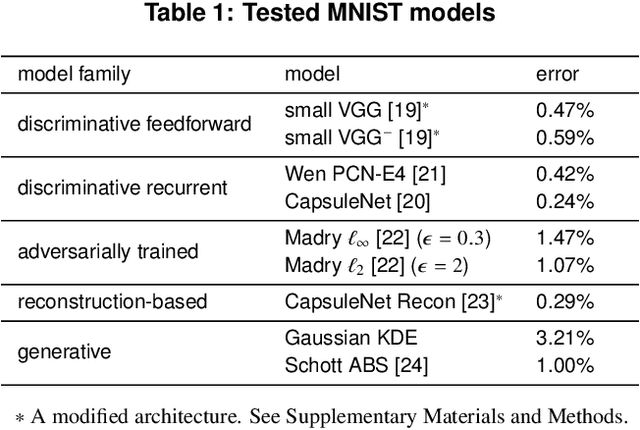
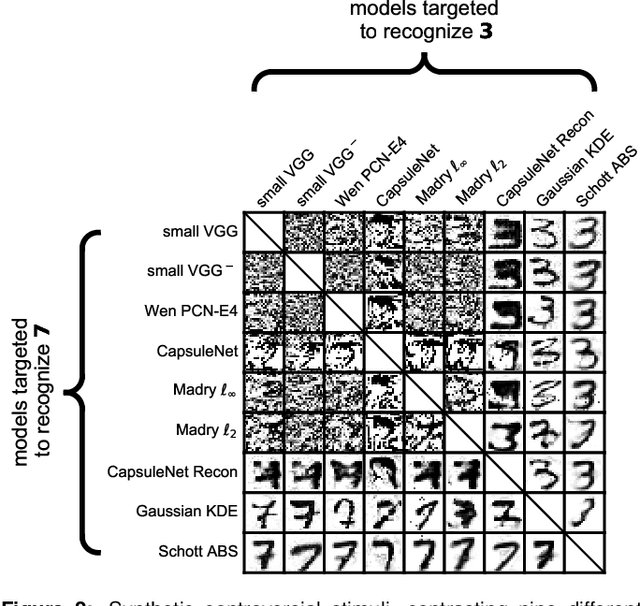
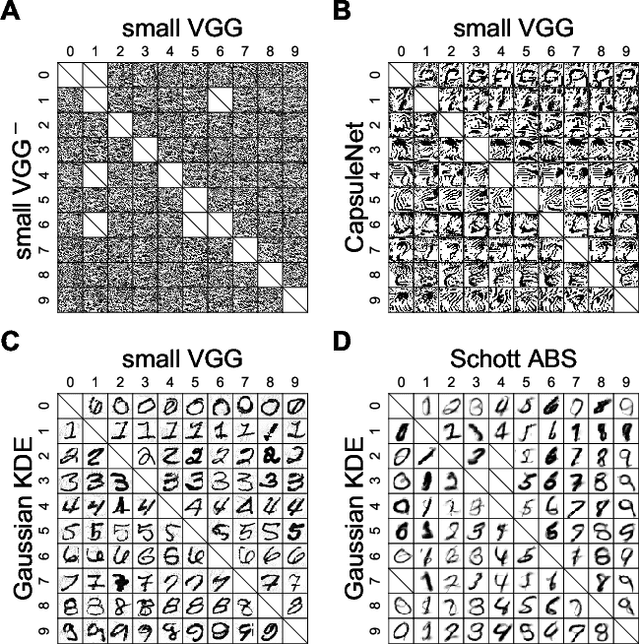
Distinct scientific theories can make similar predictions. To adjudicate between theories, we must design experiments for which the theories make distinct predictions. Here we consider the problem of comparing deep neural networks as models of human visual recognition. To efficiently determine which models better explain human responses, we synthesize controversial stimuli: images for which different models produce distinct responses. We tested nine different models, which employed different architectures and recognition algorithms, including discriminative and generative models, all trained to recognize handwritten digits (from the MNIST set of digit images). We synthesized controversial stimuli to maximize the disagreement among the models. Human subjects viewed hundreds of these stimuli and judged the probability of presence of each digit in each image. We quantified how accurately each model predicted the human judgements. We found that the generative models (which learn the distribution of images for each class) better predicted the human judgments than the discriminative models (which learn to directly map from images to labels). The best performing model was the generative Analysis-by-Synthesis model (based on variational autoencoders). However, a simpler generative model (based on Gaussian-kernel-density estimation) also performed better than each of the discriminative models. None of the candidate models fully explained the human responses. We discuss the advantages and limitations of controversial stimuli as an experimental paradigm and how they generalize and improve on adversarial examples as probes of discrepancies between models and human perception.