 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Stability: The Missing Axis of Representations
Jan 14, 2026Analysis of learned representations has a blind spot: it focuses on $similarity$, measuring how closely embeddings align with external references, but similarity reveals only what is represented, not whether that structure is robust. We introduce $geometric$ $stability$, a distinct dimension that quantifies how reliably representational geometry holds under perturbation, and present $Shesha$, a framework for measuring it. Across 2,463 configurations in seven domains, we show that stability and similarity are empirically uncorrelated ($ρ\approx 0.01$) and mechanistically distinct: similarity metrics collapse after removing the top principal components, while stability retains sensitivity to fine-grained manifold structure. This distinction yields actionable insights: for safety monitoring, stability acts as a functional geometric canary, detecting structural drift nearly 2$\times$ more sensitively than CKA while filtering out the non-functional noise that triggers false alarms in rigid distance metrics; for controllability, supervised stability predicts linear steerability ($ρ= 0.89$-$0.96$); for model selection, stability dissociates from transferability, revealing a geometric tax that transfer optimization incurs. Beyond machine learning, stability predicts CRISPR perturbation coherence and neural-behavioral coupling. By quantifying $how$ $reliably$ systems maintain structure, geometric stability provides a necessary complement to similarity for auditing representations across biological and computational systems.
Controversial stimuli: pitting neural networks against each other as models of human recognition
Nov 21, 2019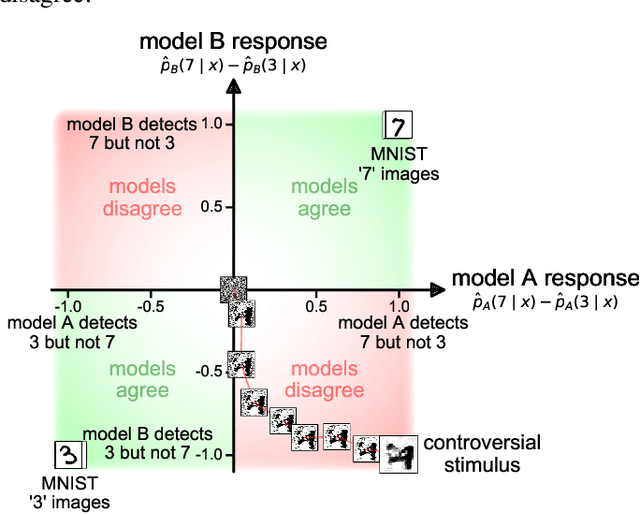
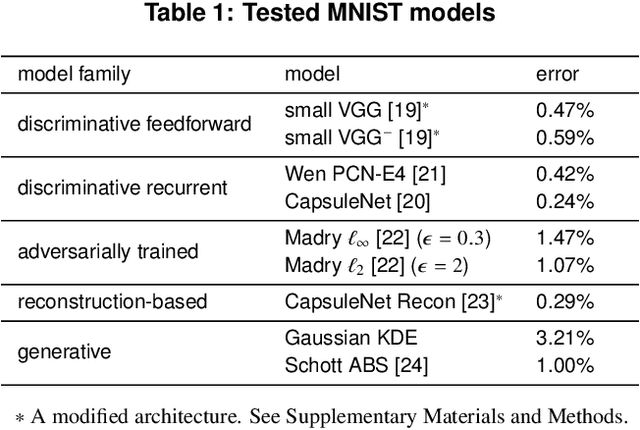
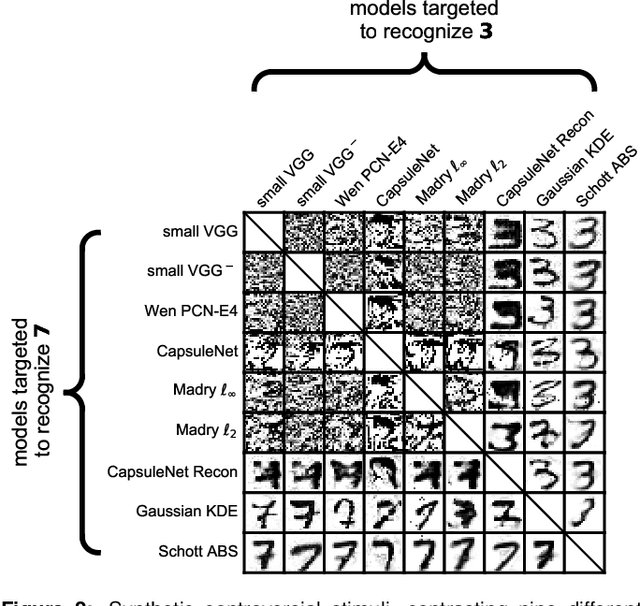
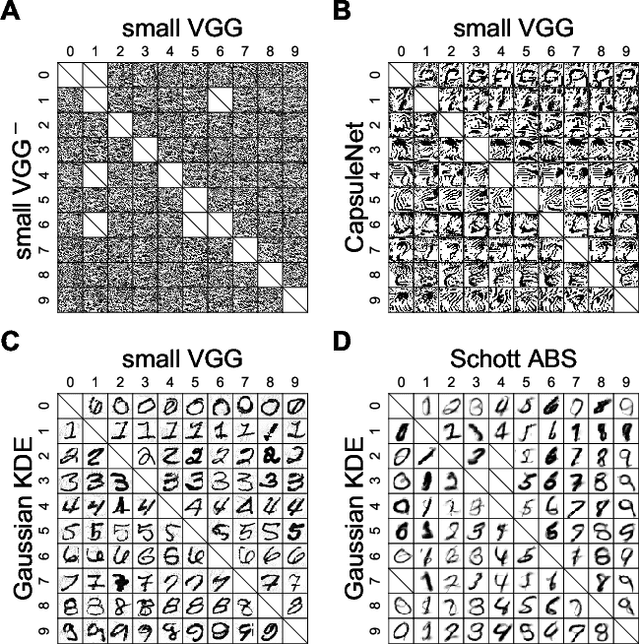
Distinct scientific theories can make similar predictions. To adjudicate between theories, we must design experiments for which the theories make distinct predictions. Here we consider the problem of comparing deep neural networks as models of human visual recognition. To efficiently determine which models better explain human responses, we synthesize controversial stimuli: images for which different models produce distinct responses. We tested nine different models, which employed different architectures and recognition algorithms, including discriminative and generative models, all trained to recognize handwritten digits (from the MNIST set of digit images). We synthesized controversial stimuli to maximize the disagreement among the models. Human subjects viewed hundreds of these stimuli and judged the probability of presence of each digit in each image. We quantified how accurately each model predicted the human judgements. We found that the generative models (which learn the distribution of images for each class) better predicted the human judgments than the discriminative models (which learn to directly map from images to labels). The best performing model was the generative Analysis-by-Synthesis model (based on variational autoencoders). However, a simpler generative model (based on Gaussian-kernel-density estimation) also performed better than each of the discriminative models. None of the candidate models fully explained the human responses. We discuss the advantages and limitations of controversial stimuli as an experimental paradigm and how they generalize and improve on adversarial examples as probes of discrepancies between models and human perception.