 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting the limits of natural language models for predicting human language judgments
Apr 07, 2022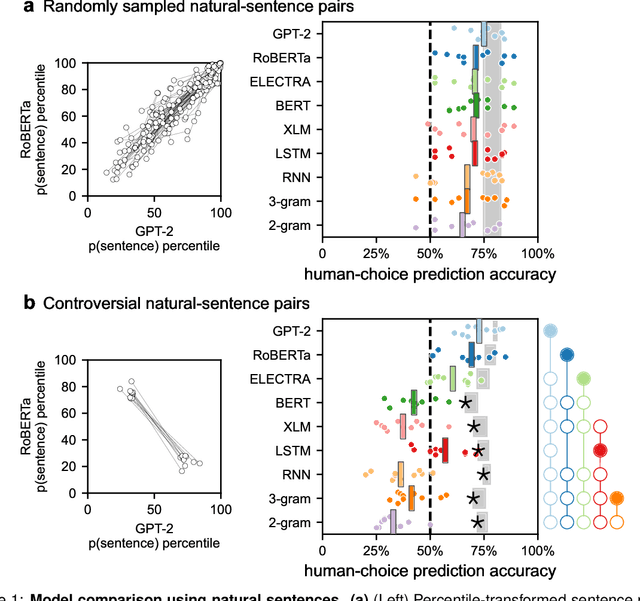
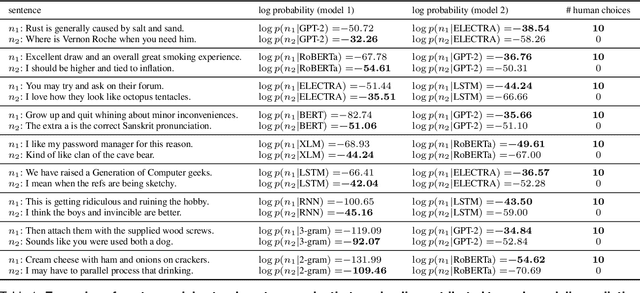
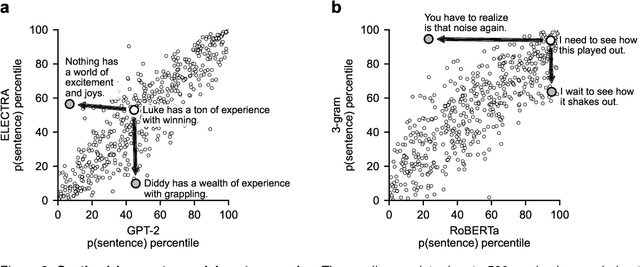
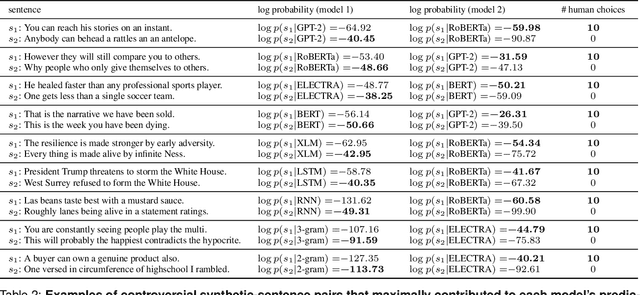
Neural network language models can serve as computational hypotheses about how humans process language. We compared the model-human consistency of diverse language models using a novel experimental approach: controversial sentence pairs. For each controversial sentence pair, two language models disagree about which sentence is more likely to occur in natural text. Considering nine language models (including n-gram, recurrent neural networks, and transformer models), we created hundreds of such controversial sentence pairs by either selecting sentences from a corpus or synthetically optimizing sentence pairs to be highly controversial. Human subjects then provided judgments indicating for each pair which of the two sentences is more likely. Controversial sentence pairs proved highly effective at revealing model failures and identifying models that aligned most closely with human judgments. The most human-consistent model tested was GPT-2, although experiments also revealed significant shortcomings of its alignment with human perception.
Mapping Between fMRI Responses to Movies and their Natural Language Annotations
Apr 10, 2017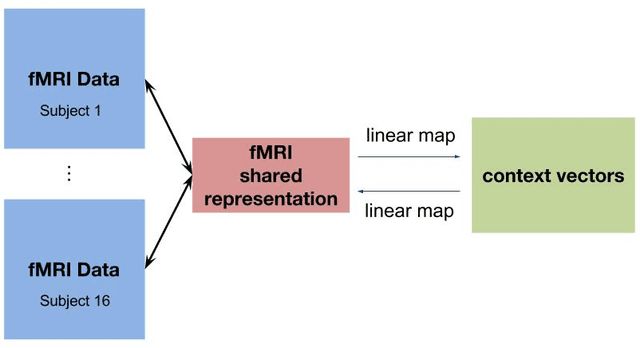
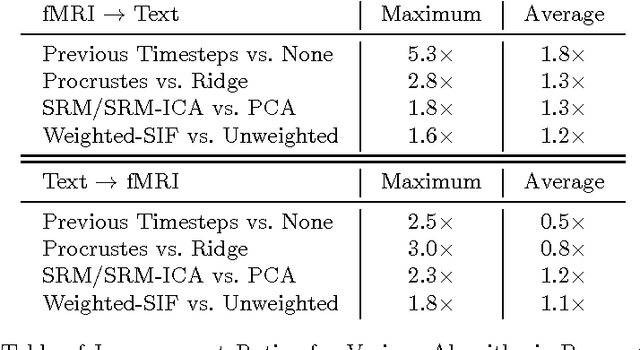
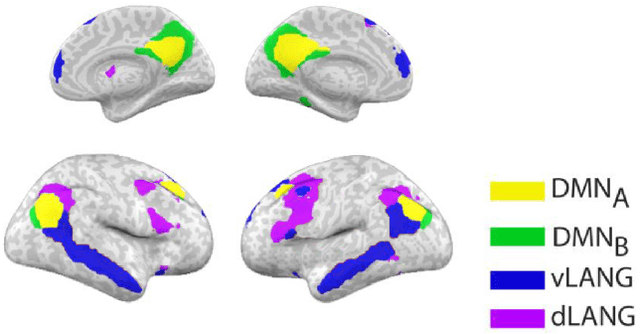
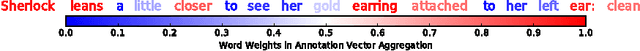
Several research groups have shown how to correlate fMRI responses to the meanings of presented stimuli. This paper presents new methods for doing so when only a natural language annotation is available as the description of the stimulus. We study fMRI data gathered from subjects watching an episode of BBCs Sherlock [1], and learn bidirectional mappings between fMRI responses and natural language representations. We show how to leverage data from multiple subjects watching the same movie to improve the accuracy of the mappings, allowing us to succeed at a scene classification task with 72% accuracy (random guessing would give 4%) and at a scene ranking task with average rank in the top 4% (random guessing would give 50%). The key ingredients are (a) the use of the Shared Response Model (SRM) and its variant SRM-ICA [2, 3] to aggregate fMRI data from multiple subjects, both of which are shown to be superior to standard PCA in producing low-dimensional representations for the tasks in this paper; (b) a sentence embedding technique adapted from the natural language processing (NLP) literature [4] that produces semantic vector representation of the annotations; (c) using previous timestep information in the featurization of the predictor data.
Affordances Provide a Fundamental Categorization Principle for Visual Scenes
Nov 19, 2014How do we know that a kitchen is a kitchen by looking? Relatively little is known about how we conceptualize and categorize different visual environments. Traditional models of visual perception posit that scene categorization is achieved through the recognition of a scene's objects, yet these models cannot account for the mounting evidence that human observers are relatively insensitive to the local details in an image. Psychologists have long theorized that the affordances, or actionable possibilities of a stimulus are pivotal to its perception. To what extent are scene categories created from similar affordances? Using a large-scale experiment using hundreds of scene categories, we show that the activities afforded by a visual scene provide a fundamental categorization principle. Affordance-based similarity explained the majority of the structure in the human scene categorization patterns, outperforming alternative similarities based on objects or visual features. We all models were combined, affordances provided the majority of the predictive power in the combined model, and nearly half of the total explained variance is captured only by affordances. These results challenge many existing models of high-level visual perception, and provide immediately testable hypotheses for the functional organization of the human perceptual system.