 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Token Prediction and Regret Minimization
Mar 30, 2026We consider the question of how to employ next-token prediction algorithms in adversarial online decision-making environments. Specifically, if we train a next-token prediction model on a distribution $\mathcal{D}$ over sequences of opponent actions, when is it the case that the induced online decision-making algorithm (by approximately best responding to the model's predictions) has low adversarial regret (i.e., when is $\mathcal{D}$ a \emph{low-regret distribution})? For unbounded context windows (where the prediction made by the model can depend on all the actions taken by the adversary thus far), we show that although not every distribution $\mathcal{D}$ is a low-regret distribution, every distribution $\mathcal{D}$ is exponentially close (in TV distance) to one low-regret distribution, and hence sublinear regret can always be achieved at negligible cost to the accuracy of the original next-token prediction model. In contrast to this, for bounded context windows (where the prediction made by the model can depend only on the past $w$ actions taken by the adversary, as may be the case in modern transformer architectures), we show that there are some distributions $\mathcal{D}$ of opponent play that are $Θ(1)$-far from any low-regret distribution $\mathcal{D'}$ (even when $w = Ω(T)$ and such distributions exist). Finally, we complement these results by showing that the unbounded context robustification procedure can be implemented by layers of a standard transformer architecture, and provide empirical evidence that transformer models can be efficiently trained to represent these new low-regret distributions.
The PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Is Learning in Games Good for the Learners?
May 31, 2023
We consider a number of questions related to tradeoffs between reward and regret in repeated gameplay between two agents. To facilitate this, we introduce a notion of {\it generalized equilibrium} which allows for asymmetric regret constraints, and yields polytopes of feasible values for each agent and pair of regret constraints, where we show that any such equilibrium is reachable by a pair of algorithms which maintain their regret guarantees against arbitrary opponents. As a central example, we highlight the case one agent is no-swap and the other's regret is unconstrained. We show that this captures an extension of {\it Stackelberg} equilibria with a matching optimal value, and that there exists a wide class of games where a player can significantly increase their utility by deviating from a no-swap-regret algorithm against a no-swap learner (in fact, almost any game without pure Nash equilibria is of this form). Additionally, we make use of generalized equilibria to consider tradeoffs in terms of the opponent's algorithm choice. We give a tight characterization for the maximal reward obtainable against {\it some} no-regret learner, yet we also show a class of games in which this is bounded away from the value obtainable against the class of common ``mean-based'' no-regret algorithms. Finally, we consider the question of learning reward-optimal strategies via repeated play with a no-regret agent when the game is initially unknown. Again we show tradeoffs depending on the opponent's learning algorithm: the Stackelberg strategy is learnable in exponential time with any no-regret agent (and in polynomial time with any no-{\it adaptive}-regret agent) for any game where it is learnable via queries, and there are games where it is learnable in polynomial time against any no-swap-regret agent but requires exponential time against a mean-based no-regret agent.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
History-Restricted Online Learning
May 28, 2022
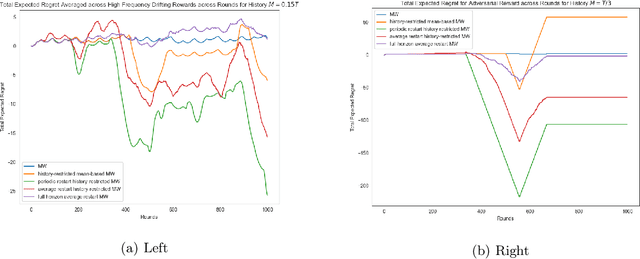
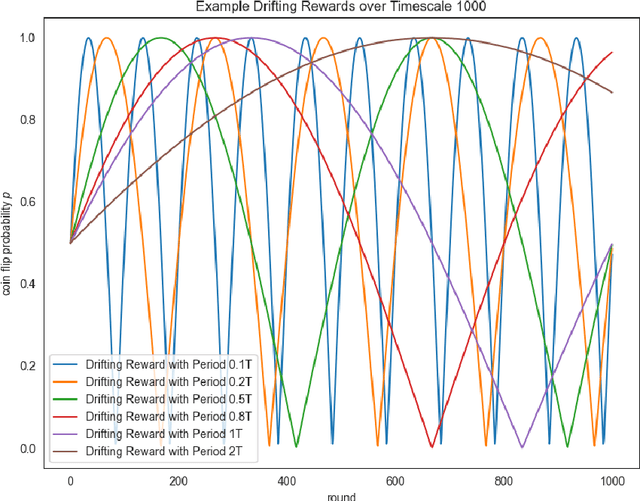
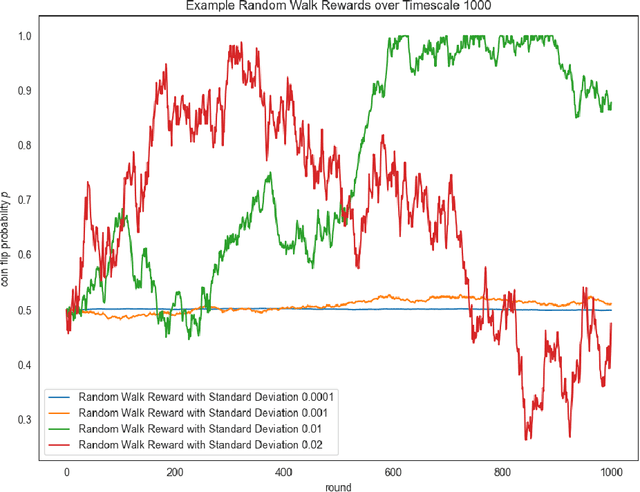
We introduce the concept of history-restricted no-regret online learning algorithms. An online learning algorithm $\mathcal{A}$ is $M$-history-restricted if its output at time $t$ can be written as a function of the $M$ previous rewards. This class of online learning algorithms is quite natural to consider from many perspectives: they may be better models of human agents and they do not store long-term information (thereby ensuring ``the right to be forgotten''). We first demonstrate that a natural approach to constructing history-restricted algorithms from mean-based no-regret learning algorithms (e.g. running Hedge over the last $M$ rounds) fails, and that such algorithms incur linear regret. We then construct a history-restricted algorithm that achieves a per-round regret of $\Theta(1/\sqrt{M})$, which we complement with a tight lower bound. Finally, we empirically explore distributions where history-restricted online learners have favorable performance compared to other no-regret algorithms.
Algorithms for Efficiently Learning Low-Rank Neural Networks
Feb 03, 2022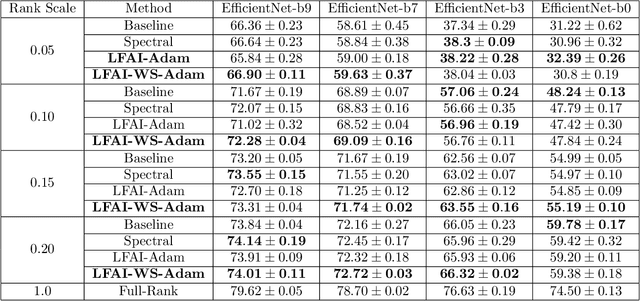
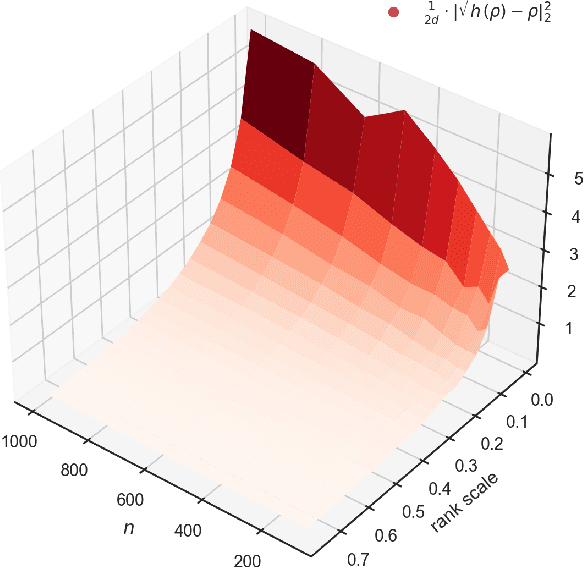
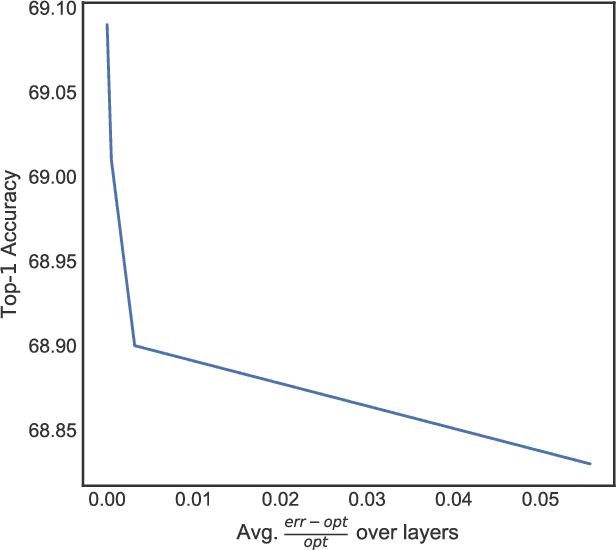

We study algorithms for learning low-rank neural networks -- networks where the weight parameters are re-parameterized by products of two low-rank matrices. First, we present a provably efficient algorithm which learns an optimal low-rank approximation to a single-hidden-layer ReLU network up to additive error $\epsilon$ with probability $\ge 1 - \delta$, given access to noiseless samples with Gaussian marginals in polynomial time and samples. Thus, we provide the first example of an algorithm which can efficiently learn a neural network up to additive error without assuming the ground truth is realizable. To solve this problem, we introduce an efficient SVD-based $\textit{Nonlinear Kernel Projection}$ algorithm for solving a nonlinear low-rank approximation problem over Gaussian space. Inspired by the efficiency of our algorithm, we propose a novel low-rank initialization framework for training low-rank $\textit{deep}$ networks, and prove that for ReLU networks, the gap between our method and existing schemes widens as the desired rank of the approximating weights decreases, or as the dimension of the inputs increases (the latter point holds when network width is superlinear in dimension). Finally, we validate our theory by training ResNet and EfficientNet models on ImageNet.
The Logical Options Framework
Feb 24, 2021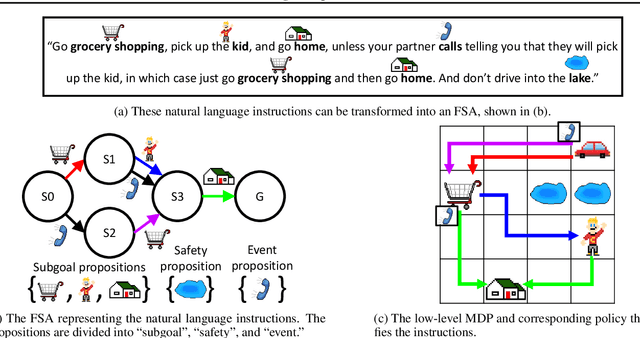
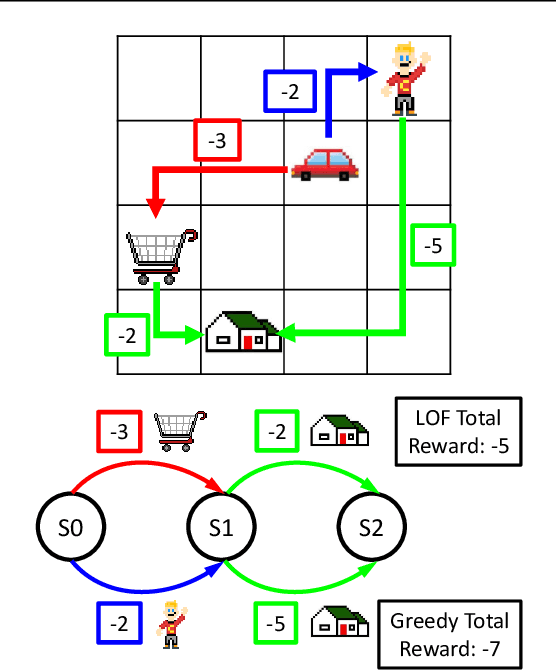
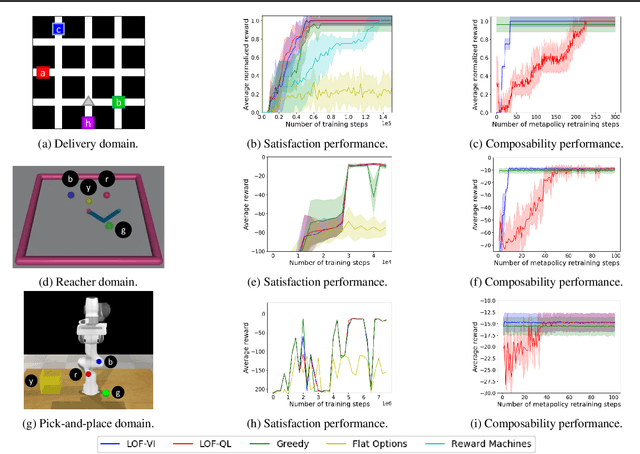
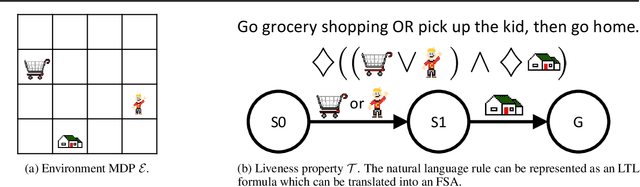
Learning composable policies for environments with complex rules and tasks is a challenging problem. We introduce a hierarchical reinforcement learning framework called the Logical Options Framework (LOF) that learns policies that are satisfying, optimal, and composable. LOF efficiently learns policies that satisfy tasks by representing the task as an automaton and integrating it into learning and planning. We provide and prove conditions under which LOF will learn satisfying, optimal policies. And lastly, we show how LOF's learned policies can be composed to satisfy unseen tasks with only 10-50 retraining steps. We evaluate LOF on four tasks in discrete and continuous domains, including a 3D pick-and-place environment.