 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Accounting and Quality Control in the Sage Differentially Private ML Platform
Sep 06, 2019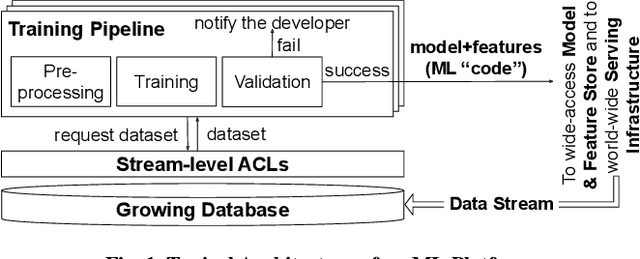
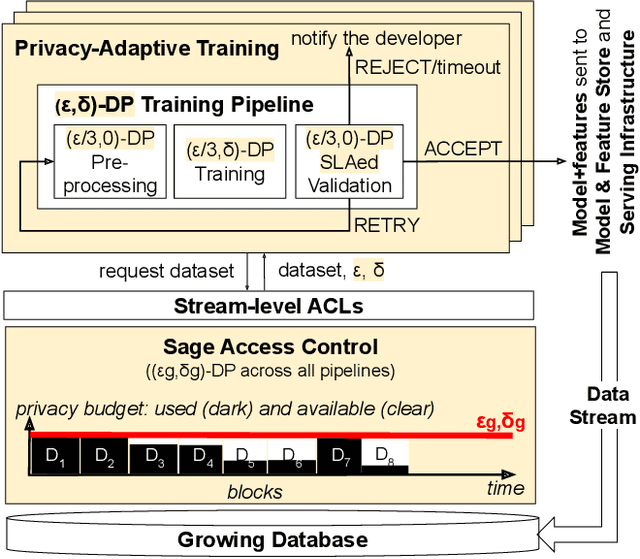
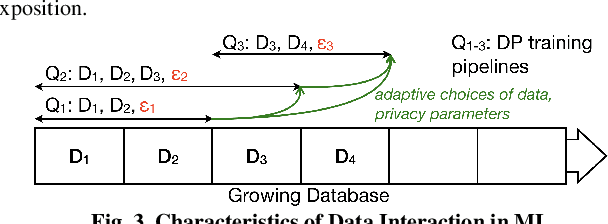

Companies increasingly expose machine learning (ML) models trained over sensitive user data to untrusted domains, such as end-user devices and wide-access model stores. We present Sage, a differentially private (DP) ML platform that bounds the cumulative leakage of training data through models. Sage builds upon the rich literature on DP ML algorithms and contributes pragmatic solutions to two of the most pressing systems challenges of global DP: running out of privacy budget and the privacy-utility tradeoff. To address the former, we develop block composition, a new privacy loss accounting method that leverages the growing database regime of ML workloads to keep training models endlessly on a sensitive data stream while enforcing a global DP guarantee for the stream. To address the latter, we develop privacy-adaptive training, a process that trains a model on growing amounts of data and/or with increasing privacy parameters until, with high probability, the model meets developer-configured quality criteria. They illustrate how a systems focus on characteristics of ML workloads enables pragmatic solutions that are not apparent when one focuses on individual algorithms, as most DP ML literature does.