 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Between fMRI Responses to Movies and their Natural Language Annotations
Paper and Code
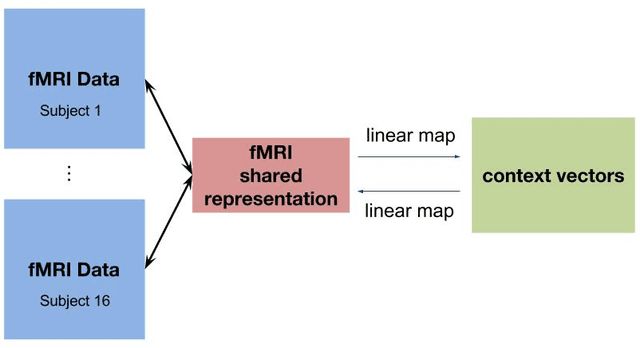
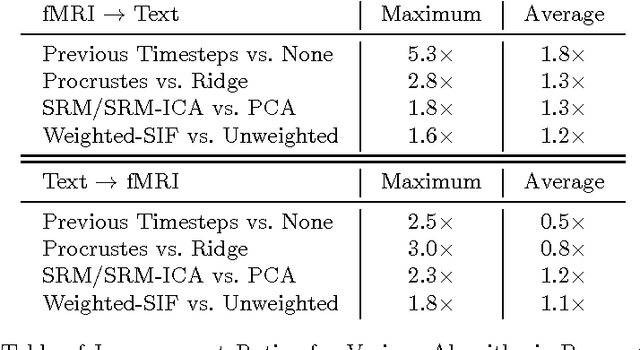
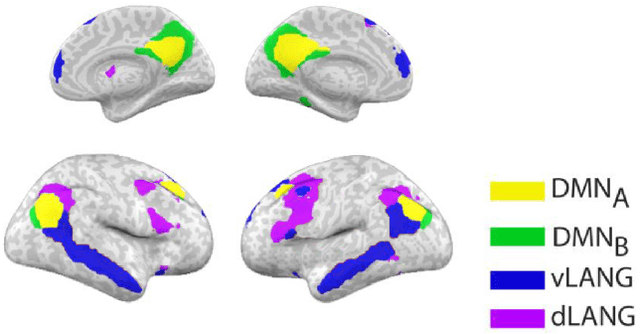
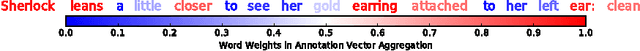
Several research groups have shown how to correlate fMRI responses to the meanings of presented stimuli. This paper presents new methods for doing so when only a natural language annotation is available as the description of the stimulus. We study fMRI data gathered from subjects watching an episode of BBCs Sherlock [1], and learn bidirectional mappings between fMRI responses and natural language representations. We show how to leverage data from multiple subjects watching the same movie to improve the accuracy of the mappings, allowing us to succeed at a scene classification task with 72% accuracy (random guessing would give 4%) and at a scene ranking task with average rank in the top 4% (random guessing would give 50%). The key ingredients are (a) the use of the Shared Response Model (SRM) and its variant SRM-ICA [2, 3] to aggregate fMRI data from multiple subjects, both of which are shown to be superior to standard PCA in producing low-dimensional representations for the tasks in this paper; (b) a sentence embedding technique adapted from the natural language processing (NLP) literature [4] that produces semantic vector representation of the annotations; (c) using previous timestep information in the featurization of the predictor data.