 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissociating spatial frequency reliance from adversarial robustness advantages in neurally guided deep convolutional neural networks
May 06, 2026Deep convolutional neural networks (DCNNs) have rivaled humans on many visual tasks, yet they remain vulnerable to near-imperceptible perturbations generated by adversarial attacks. Recent work shows that aligning DCNN representations with human visual cortex activity improves adversarial robustness, but the mechanisms driving this advantage are unclear. One hypothesis suggests that neural alignment confers robustness by biasing models away from brittle high-frequency details and towards the low spatial frequencies (LSF). However, recent work shows that human object recognition critically depends on a narrow, mid-frequency "human channel". Interestingly, this band was partially preserved in prior LSF-focused studies. Here, we investigate whether a spectral bias towards the LSF or the human channel is the primary driver of the adversarial robustness observed in neurally aligned DCNNs. We first show that DCNNs aligned to higher-order regions of the human ventral visual stream systematically increase reliance on both LSF and the human channel. However, directly steering DCNNs towards these bands revealed a clear dissociation. Biasing models towards the human channel, either alone or together with LSF, does not improve robustness and even impairs it. LSF bias produced some robustness gains, but such improvements are modest despite inducing much larger shifts in spatial-frequency reliance than neurally aligned models. Spatial-frequency-biased models overall show little, if any, increase in similarity to human neural representational geometry. Together, our results suggest that altered spatial-frequency reliance is likely an emergent property of learning more human-like representations rather than the primary mechanism by which neural alignment confers adversarial robustness, and motivate the need for future research examining representational properties beyond spatial-frequency profiles.
Leveraging the Human Ventral Visual Stream to Improve Neural Network Robustness
May 04, 2024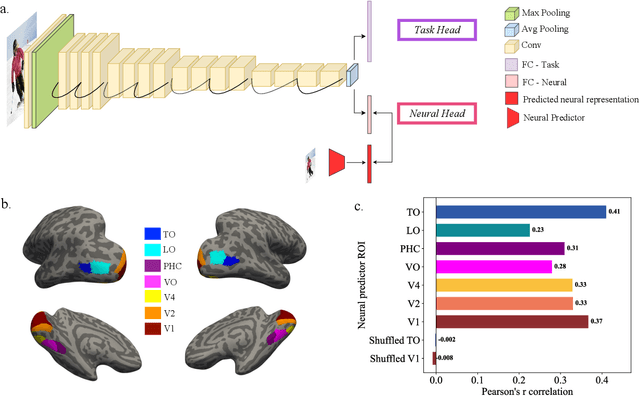
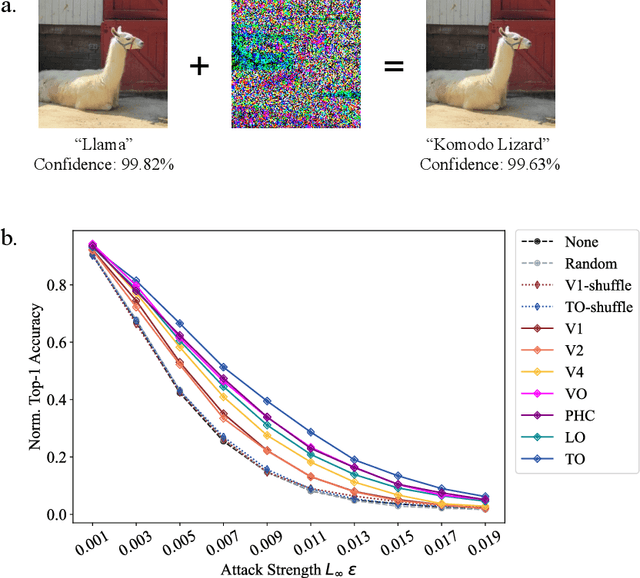
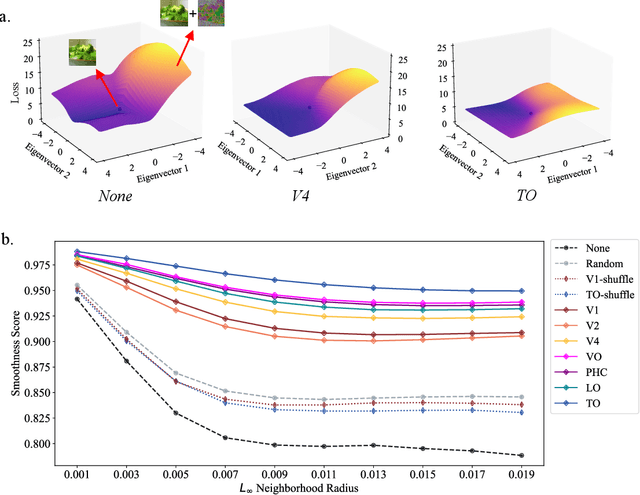
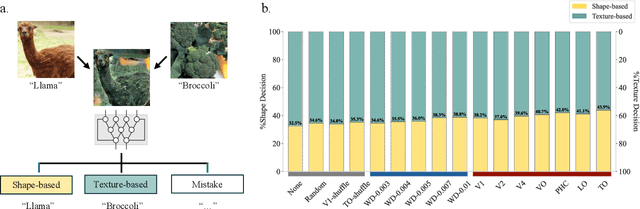
Human object recognition exhibits remarkable resilience in cluttered and dynamic visual environments. In contrast, despite their unparalleled performance across numerous visual tasks, Deep Neural Networks (DNNs) remain far less robust than humans, showing, for example, a surprising susceptibility to adversarial attacks involving image perturbations that are (almost) imperceptible to humans. Human object recognition likely owes its robustness, in part, to the increasingly resilient representations that emerge along the hierarchy of the ventral visual cortex. Here we show that DNNs, when guided by neural representations from a hierarchical sequence of regions in the human ventral visual stream, display increasing robustness to adversarial attacks. These neural-guided models also exhibit a gradual shift towards more human-like decision-making patterns and develop hierarchically smoother decision surfaces. Importantly, the resulting representational spaces differ in important ways from those produced by conventional smoothing methods, suggesting that such neural-guidance may provide previously unexplored robustness solutions. Our findings support the gradual emergence of human robustness along the ventral visual hierarchy and suggest that the key to DNN robustness may lie in increasing emulation of the human brain.
Locally-Optimized Inter-Subject Alignment of Functional Cortical Regions
Jun 07, 2016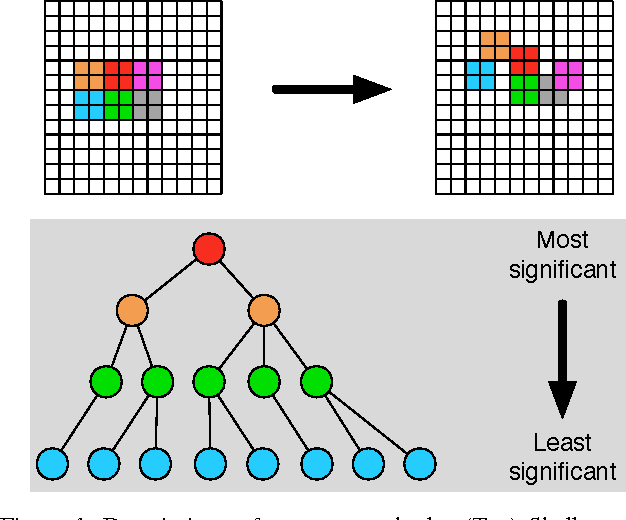
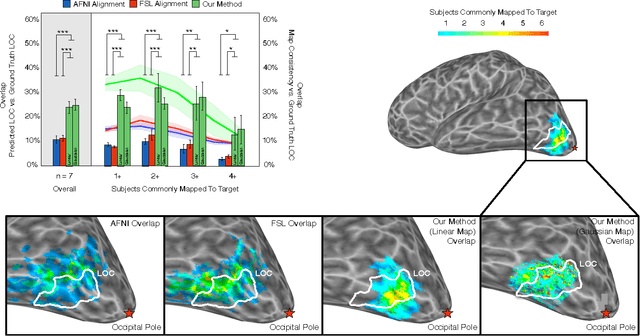
Inter-subject registration of cortical areas is necessary in functional imaging (fMRI) studies for making inferences about equivalent brain function across a population. However, many high-level visual brain areas are defined as peaks of functional contrasts whose cortical position is highly variable. As such, most alignment methods fail to accurately map functional regions of interest (ROIs) across participants. To address this problem, we propose a locally optimized registration method that directly predicts the location of a seed ROI on a separate target cortical sheet by maximizing the functional correlation between their time courses, while simultaneously allowing for non-smooth local deformations in region topology. Our method outperforms the two most commonly used alternatives (anatomical landmark-based AFNI alignment and cortical convexity-based FreeSurfer alignment) in overlap between predicted region and functionally-defined LOC. Furthermore, the maps obtained using our method are more consistent across subjects than both baseline measures. Critically, our method represents an important step forward towards predicting brain regions without explicit localizer scans and deciphering the poorly understood relationship between the location of functional regions, their anatomical extent, and the consistency of computations those regions perform across people.
Affordances Provide a Fundamental Categorization Principle for Visual Scenes
Nov 19, 2014How do we know that a kitchen is a kitchen by looking? Relatively little is known about how we conceptualize and categorize different visual environments. Traditional models of visual perception posit that scene categorization is achieved through the recognition of a scene's objects, yet these models cannot account for the mounting evidence that human observers are relatively insensitive to the local details in an image. Psychologists have long theorized that the affordances, or actionable possibilities of a stimulus are pivotal to its perception. To what extent are scene categories created from similar affordances? Using a large-scale experiment using hundreds of scene categories, we show that the activities afforded by a visual scene provide a fundamental categorization principle. Affordance-based similarity explained the majority of the structure in the human scene categorization patterns, outperforming alternative similarities based on objects or visual features. We all models were combined, affordances provided the majority of the predictive power in the combined model, and nearly half of the total explained variance is captured only by affordances. These results challenge many existing models of high-level visual perception, and provide immediately testable hypotheses for the functional organization of the human perceptual system.
Visual Noise from Natural Scene Statistics Reveals Human Scene Category Representations
Nov 19, 2014Our perceptions are guided both by the bottom-up information entering our eyes, as well as our top-down expectations of what we will see. Although bottom-up visual processing has been extensively studied, comparatively little is known about top-down signals. Here, we describe REVEAL (Representations Envisioned Via Evolutionary ALgorithm), a method for visualizing an observer's internal representation of a complex, real-world scene, allowing us to, for the first time, visualize the top-down information in an observer's mind. REVEAL rests on two innovations for solving this high dimensional problem: visual noise that samples from natural image statistics, and a computer algorithm that collaborates with human observers to efficiently obtain a solution. In this work, we visualize observers' internal representations of a visual scene category (street) using an experiment in which the observer views the naturalistic visual noise and collaborates with the algorithm to externalize his internal representation. As no scene information was presented, observers had to use their internal knowledge of the target, matching it with the visual features in the noise. We matched reconstructed images with images of real-world street scenes to enhance visualization. Critically, we show that the visualized mental images can be used to predict rapid scene detection performance, as each observer had faster and more accurate responses to detecting real-world images that were the most similar to his reconstructed street templates. These results show that it is possible to visualize previously unobservable mental representations of real world stimuli. More broadly, REVEAL provides a general method for objectively examining the content of previously private, subjective mental experiences.