 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-IT: Image Reconstruction from fMRI via Brain-Interaction Transformer
Oct 29, 2025
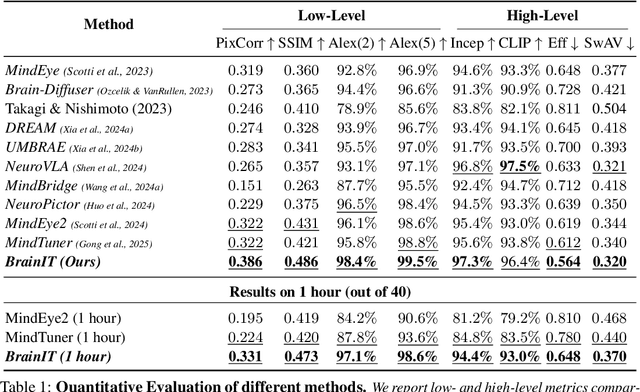
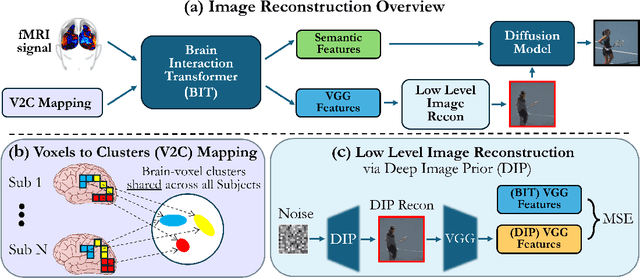

Reconstructing images seen by people from their fMRI brain recordings provides a non-invasive window into the human brain. Despite recent progress enabled by diffusion models, current methods often lack faithfulness to the actual seen images. We present "Brain-IT", a brain-inspired approach that addresses this challenge through a Brain Interaction Transformer (BIT), allowing effective interactions between clusters of functionally-similar brain-voxels. These functional-clusters are shared by all subjects, serving as building blocks for integrating information both within and across brains. All model components are shared by all clusters & subjects, allowing efficient training with a limited amount of data. To guide the image reconstruction, BIT predicts two complementary localized patch-level image features: (i)high-level semantic features which steer the diffusion model toward the correct semantic content of the image; and (ii)low-level structural features which help to initialize the diffusion process with the correct coarse layout of the image. BIT's design enables direct flow of information from brain-voxel clusters to localized image features. Through these principles, our method achieves image reconstructions from fMRI that faithfully reconstruct the seen images, and surpass current SotA approaches both visually and by standard objective metrics. Moreover, with only 1-hour of fMRI data from a new subject, we achieve results comparable to current methods trained on full 40-hour recordings.
Don't Judge Before You CLIP: A Unified Approach for Perceptual Tasks
Mar 17, 2025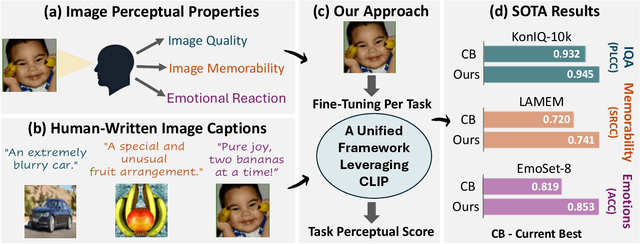
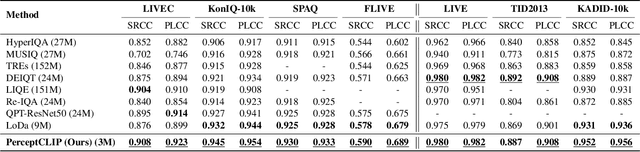
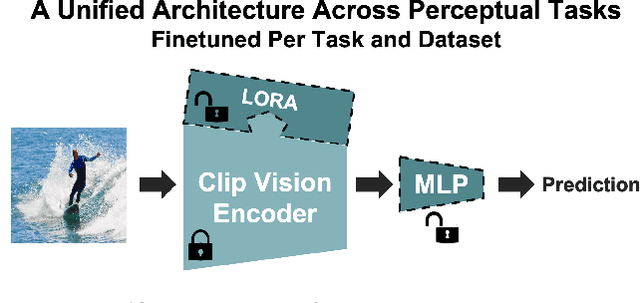
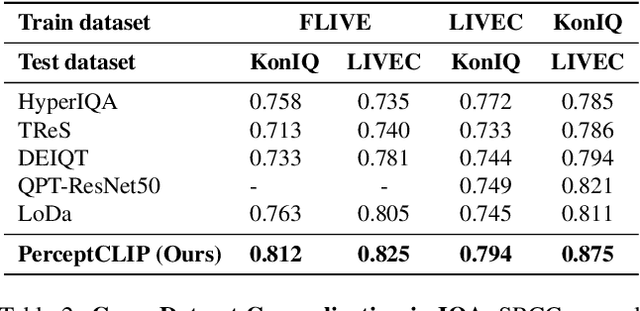
Visual perceptual tasks aim to predict human judgment of images (e.g., emotions invoked by images, image quality assessment). Unlike objective tasks such as object/scene recognition, perceptual tasks rely on subjective human assessments, making its data-labeling difficult. The scarcity of such human-annotated data results in small datasets leading to poor generalization. Typically, specialized models were designed for each perceptual task, tailored to its unique characteristics and its own training dataset. We propose a unified architectural framework for solving multiple different perceptual tasks leveraging CLIP as a prior. Our approach is based on recent cognitive findings which indicate that CLIP correlates well with human judgment. While CLIP was explicitly trained to align images and text, it implicitly also learned human inclinations. We attribute this to the inclusion of human-written image captions in CLIP's training data, which contain not only factual image descriptions, but inevitably also human sentiments and emotions. This makes CLIP a particularly strong prior for perceptual tasks. Accordingly, we suggest that minimal adaptation of CLIP suffices for solving a variety of perceptual tasks. Our simple unified framework employs a lightweight adaptation to fine-tune CLIP to each task, without requiring any task-specific architectural changes. We evaluate our approach on three tasks: (i) Image Memorability Prediction, (ii) No-reference Image Quality Assessment, and (iii) Visual Emotion Analysis. Our model achieves state-of-the-art results on all three tasks, while demonstrating improved generalization across different datasets.
The Wisdom of a Crowd of Brains: A Universal Brain Encoder
Jun 18, 2024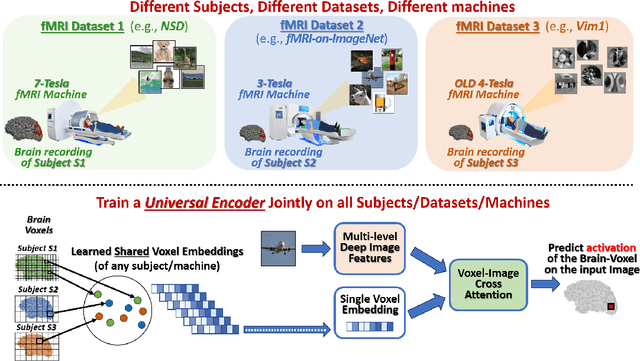
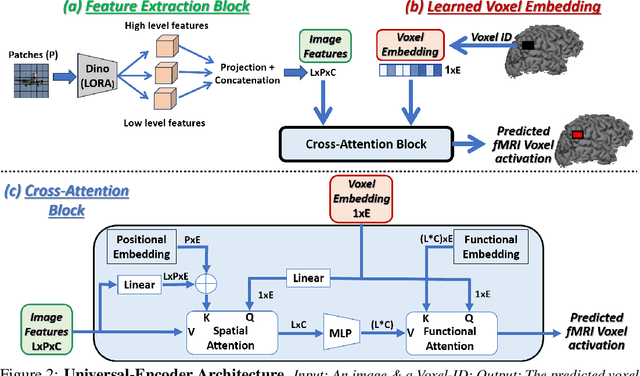

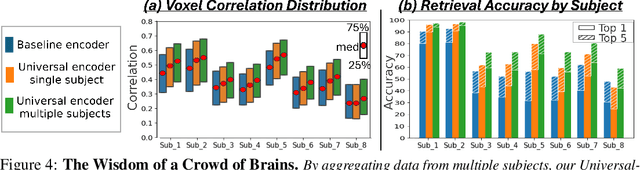
Image-to-fMRI encoding is important for both neuroscience research and practical applications. However, such "Brain-Encoders" have been typically trained per-subject and per fMRI-dataset, thus restricted to very limited training data. In this paper we propose a Universal Brain-Encoder, which can be trained jointly on data from many different subjects/datasets/machines. What makes this possible is our new voxel-centric Encoder architecture, which learns a unique "voxel-embedding" per brain-voxel. Our Encoder trains to predict the response of each brain-voxel on every image, by directly computing the cross-attention between the brain-voxel embedding and multi-level deep image features. This voxel-centric architecture allows the functional role of each brain-voxel to naturally emerge from the voxel-image cross-attention. We show the power of this approach to (i) combine data from multiple different subjects (a "Crowd of Brains") to improve each individual brain-encoding, (ii) quick & effective Transfer-Learning across subjects, datasets, and machines (e.g., 3-Tesla, 7-Tesla), with few training examples, and (iii) use the learned voxel-embeddings as a powerful tool to explore brain functionality (e.g., what is encoded where in the brain).
A Penny for Your Thoughts: Self-Supervised Reconstruction of Natural Movies from Brain Activity
Jun 10, 2022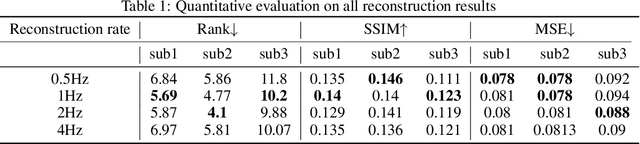
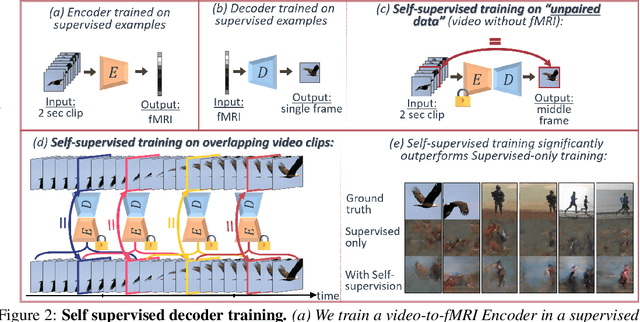


Reconstructing natural videos from fMRI brain recordings is very challenging, for two main reasons: (i) As fMRI data acquisition is difficult, we only have a limited amount of supervised samples, which is not enough to cover the huge space of natural videos; and (ii) The temporal resolution of fMRI recordings is much lower than the frame rate of natural videos. In this paper, we propose a self-supervised approach for natural-movie reconstruction. By employing cycle-consistency over Encoding-Decoding natural videos, we can: (i) exploit the full framerate of the training videos, and not be limited only to clips that correspond to fMRI recordings; (ii) exploit massive amounts of external natural videos which the subjects never saw inside the fMRI machine. These enable increasing the applicable training data by several orders of magnitude, introducing natural video priors to the decoding network, as well as temporal coherence. Our approach significantly outperforms competing methods, since those train only on the limited supervised data. We further introduce a new and simple temporal prior of natural videos, which - when folded into our fMRI decoder further - allows us to reconstruct videos at a higher frame-rate (HFR) of up to x8 of the original fMRI sample rate.
From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI
Jul 03, 2019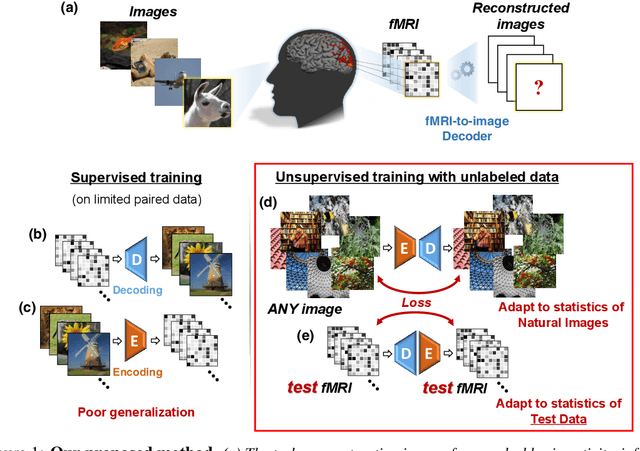
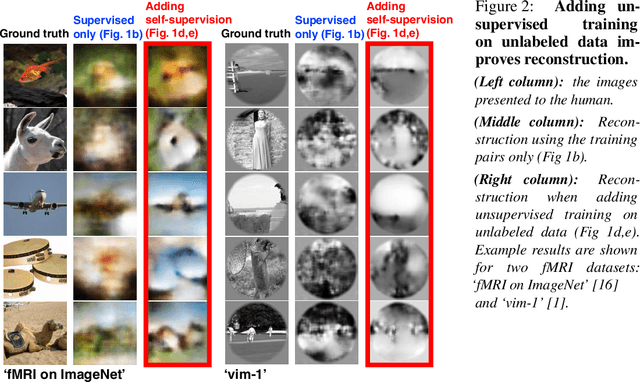
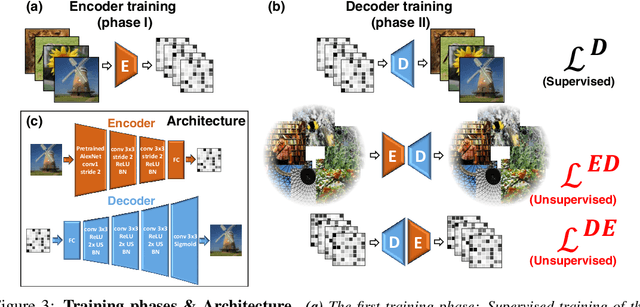
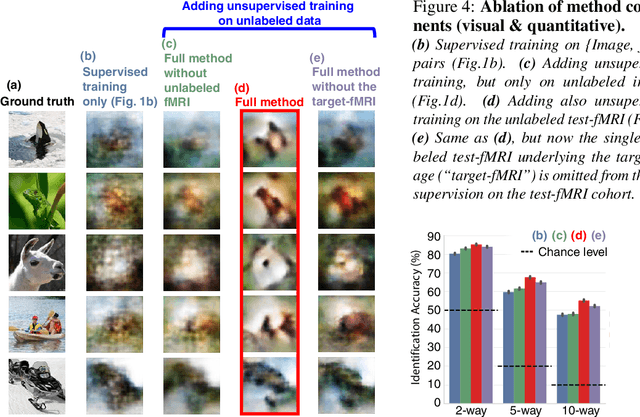
Reconstructing observed images from fMRI brain recordings is challenging. Unfortunately, acquiring sufficient "labeled" pairs of {Image, fMRI} (i.e., images with their corresponding fMRI responses) to span the huge space of natural images is prohibitive for many reasons. We present a novel approach which, in addition to the scarce labeled data (training pairs), allows to train fMRI-to-image reconstruction networks also on "unlabeled" data (i.e., images without fMRI recording, and fMRI recording without images). The proposed model utilizes both an Encoder network (image-to-fMRI) and a Decoder network (fMRI-to-image). Concatenating these two networks back-to-back (Encoder-Decoder & Decoder-Encoder) allows augmenting the training with both types of unlabeled data. Importantly, it allows training on the unlabeled test-fMRI data. This self-supervision adapts the reconstruction network to the new input test-data, despite its deviation from the statistics of the scarce training data.