 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the surprising similarities between supervised and self-supervised models
Paper and Code
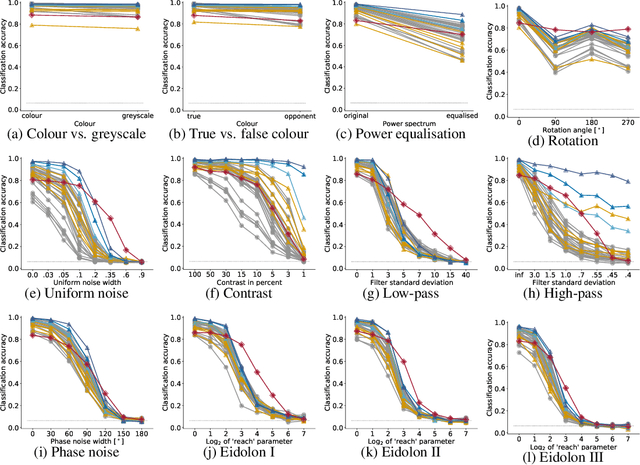
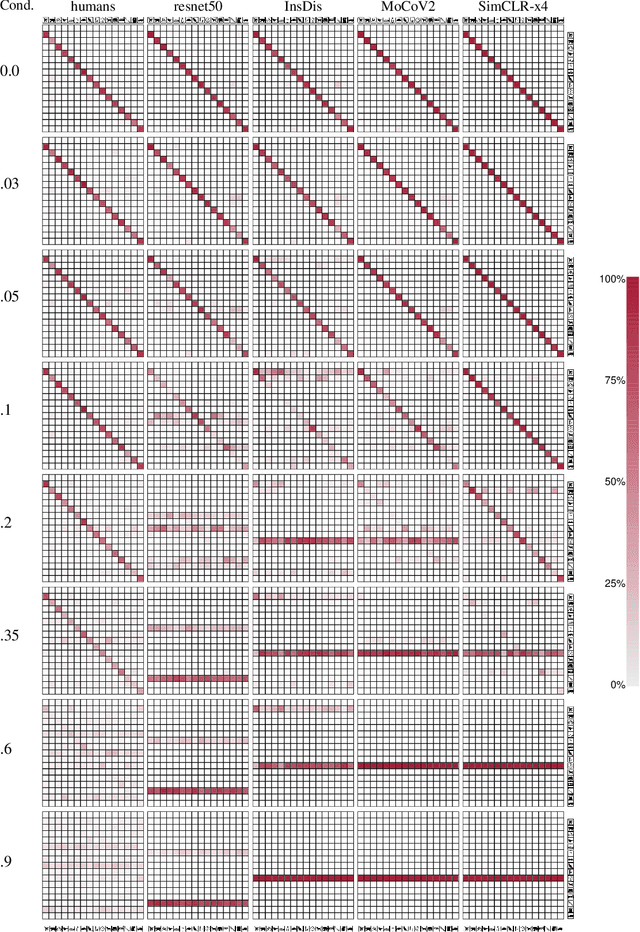
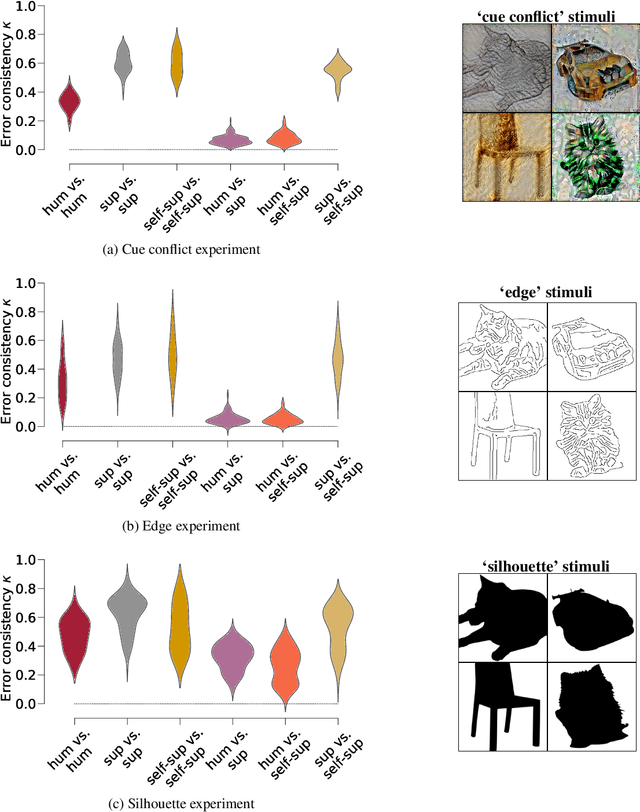
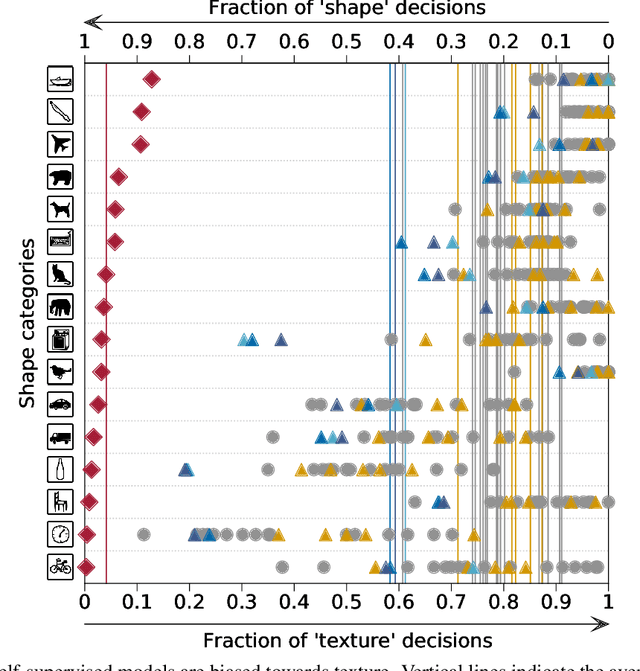
How do humans learn to acquire a powerful, flexible and robust representation of objects? While much of this process remains unknown, it is clear that humans do not require millions of object labels. Excitingly, recent algorithmic advancements in self-supervised learning now enable convolutional neural networks (CNNs) to learn useful visual object representations without supervised labels, too. In the light of this recent breakthrough, we here compare self-supervised networks to supervised models and human behaviour. We tested models on 15 generalisation datasets for which large-scale human behavioural data is available (130K highly controlled psychophysical trials). Surprisingly, current self-supervised CNNs share four key characteristics of their supervised counterparts: (1.) relatively poor noise robustness (with the notable exception of SimCLR), (2.) non-human category-level error patterns, (3.) non-human image-level error patterns (yet high similarity to supervised model errors) and (4.) a bias towards texture. Taken together, these results suggest that the strategies learned through today's supervised and self-supervised training objectives end up being surprisingly similar, but distant from human-like behaviour. That being said, we are clearly just at the beginning of what could be called a self-supervised revolution of machine vision, and we are hopeful that future self-supervised models behave differently from supervised ones, and---perhaps---more similar to robust human object recognition.