 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImmediate generalisation in humans but a generalisation lag in deep neural networks -- evidence for representational divergence?
Feb 19, 2024



Recent research has seen many behavioral comparisons between humans and deep neural networks (DNNs) in the domain of image classification. Often, comparison studies focus on the end-result of the learning process by measuring and comparing the similarities in the representations of object categories once they have been formed. However, the process of how these representations emerge -- that is, the behavioral changes and intermediate stages observed during the acquisition -- is less often directly and empirically compared. Here we report a detailed investigation of how transferable representations are acquired in human observers and various classic and state-of-the-art DNNs. We develop a constrained supervised learning environment in which we align learning-relevant parameters such as starting point, input modality, available input data and the feedback provided. Across the whole learning process we evaluate and compare how well learned representations can be generalized to previously unseen test data. Our findings indicate that in terms of absolute classification performance DNNs demonstrate a level of data efficiency comparable to -- and sometimes even exceeding that -- of human learners, challenging some prevailing assumptions in the field. However, comparisons across the entire learning process reveal significant representational differences: while DNNs' learning is characterized by a pronounced generalisation lag, humans appear to immediately acquire generalizable representations without a preliminary phase of learning training set-specific information that is only later transferred to novel data.
The developmental trajectory of object recognition robustness: children are like small adults but unlike big deep neural networks
May 20, 2022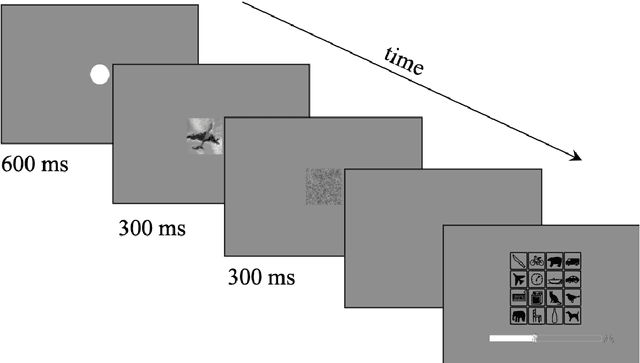
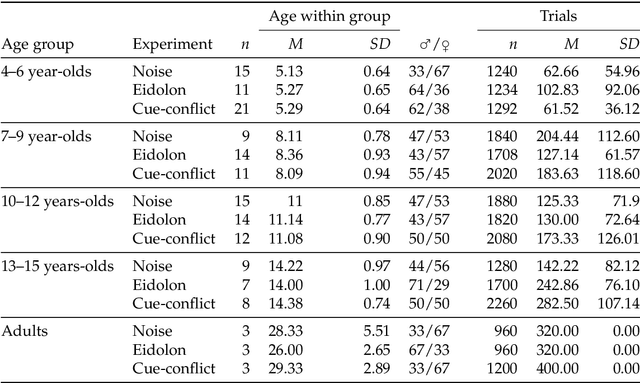


In laboratory object recognition tasks based on undistorted photographs, both adult humans and Deep Neural Networks (DNNs) perform close to ceiling. Unlike adults', whose object recognition performance is robust against a wide range of image distortions, DNNs trained on standard ImageNet (1.3M images) perform poorly on distorted images. However, the last two years have seen impressive gains in DNN distortion robustness, predominantly achieved through ever-increasing large-scale datasets$\unicode{x2014}$orders of magnitude larger than ImageNet. While this simple brute-force approach is very effective in achieving human-level robustness in DNNs, it raises the question of whether human robustness, too, is simply due to extensive experience with (distorted) visual input during childhood and beyond. Here we investigate this question by comparing the core object recognition performance of 146 children (aged 4$\unicode{x2013}$15) against adults and against DNNs. We find, first, that already 4$\unicode{x2013}$6 year-olds showed remarkable robustness to image distortions and outperform DNNs trained on ImageNet. Second, we estimated the number of $\unicode{x201C}$images$\unicode{x201D}$ children have been exposed to during their lifetime. Compared to various DNNs, children's high robustness requires relatively little data. Third, when recognizing objects children$\unicode{x2014}$like adults but unlike DNNs$\unicode{x2014}$rely heavily on shape but not on texture cues. Together our results suggest that the remarkable robustness to distortions emerges early in the developmental trajectory of human object recognition and is unlikely the result of a mere accumulation of experience with distorted visual input. Even though current DNNs match human performance regarding robustness they seem to rely on different and more data-hungry strategies to do so.