 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Generalization Gap in One-Shot Object Detection
Nov 09, 2020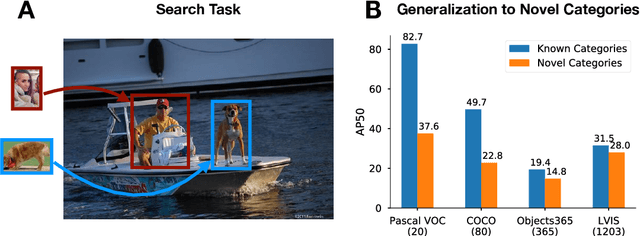


Despite substantial progress in object detection and few-shot learning, detecting objects based on a single example - one-shot object detection - remains a challenge: trained models exhibit a substantial generalization gap, where object categories used during training are detected much more reliably than novel ones. Here we show that this generalization gap can be nearly closed by increasing the number of object categories used during training. Our results show that the models switch from memorizing individual categories to learning object similarity over the category distribution, enabling strong generalization at test time. Importantly, in this regime standard methods to improve object detection models like stronger backbones or longer training schedules also benefit novel categories, which was not the case for smaller datasets like COCO. Our results suggest that the key to strong few-shot detection models may not lie in sophisticated metric learning approaches, but instead in scaling the number of categories. Future data annotation efforts should therefore focus on wider datasets and annotate a larger number of categories rather than gathering more images or instances per category.
Shortcut Learning in Deep Neural Networks
May 20, 2020


Deep learning has triggered the current rise of artificial intelligence and is the workhorse of today's machine intelligence. Numerous success stories have rapidly spread all over science, industry and society, but its limitations have only recently come into focus. In this perspective we seek to distil how many of deep learning's problem can be seen as different symptoms of the same underlying problem: shortcut learning. Shortcuts are decision rules that perform well on standard benchmarks but fail to transfer to more challenging testing conditions, such as real-world scenarios. Related issues are known in Comparative Psychology, Education and Linguistics, suggesting that shortcut learning may be a common characteristic of learning systems, biological and artificial alike. Based on these observations, we develop a set of recommendations for model interpretation and benchmarking, highlighting recent advances in machine learning to improve robustness and transferability from the lab to real-world applications.
Optimizing Rank-based Metrics with Blackbox Differentiation
Dec 07, 2019

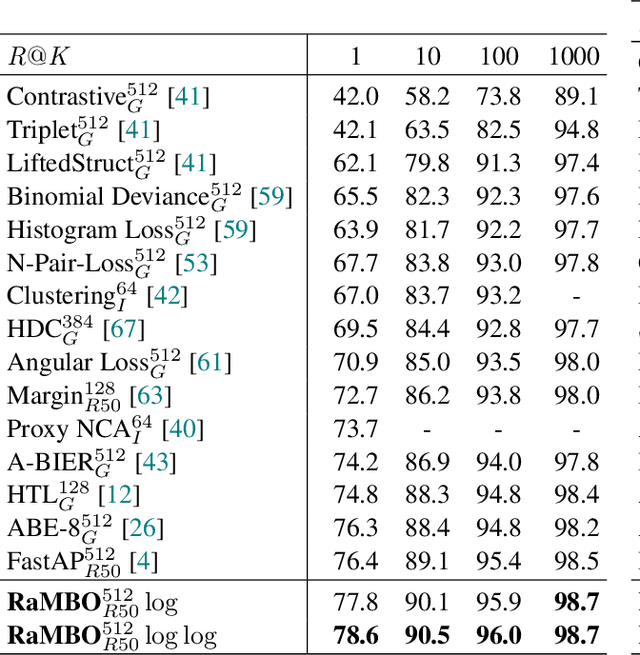
Rank-based metrics are some of the most widely used criteria for performance evaluation of computer vision models. Despite years of effort, direct optimization for these metrics remains a challenge due to their non-differentiable and non-decomposable nature. We present an efficient, theoretically sound, and general method for differentiating rank-based metrics with mini-batch gradient descent. In addition, we address optimization instability and sparsity of the supervision signal that both arise from using rank-based metrics as optimization targets. Resulting losses based on recall and Average Precision are applied to image retrieval and object detection tasks. We obtain performance that is competitive with state-of-the-art on standard image retrieval datasets and consistently improve performance of near state-of-the-art object detectors.
Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming
Jul 17, 2019
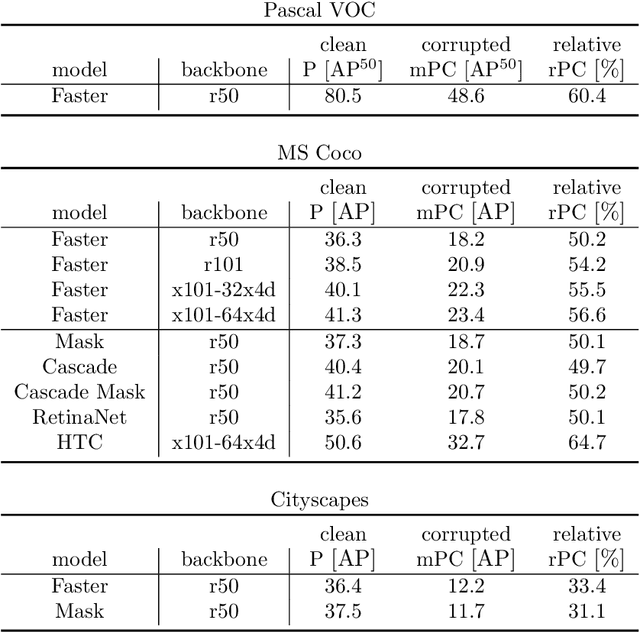


The ability to detect objects regardless of image distortions or weather conditions is crucial for real-world applications of deep learning like autonomous driving. We here provide an easy-to-use benchmark to assess how object detection models perform when image quality degrades. The three resulting benchmark datasets, termed Pascal-C, Coco-C and Cityscapes-C, contain a large variety of image corruptions. We show that a range of standard object detection models suffer a severe performance loss on corrupted images (down to 30-60% of the original performance). However, a simple data augmentation trick - stylizing the training images - leads to a substantial increase in robustness across corruption type, severity and dataset. We envision our comprehensive benchmark to track future progress towards building robust object detection models. Benchmark, code and data are available at: http://github.com/bethgelab/robust-detection-benchmark
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
Nov 29, 2018
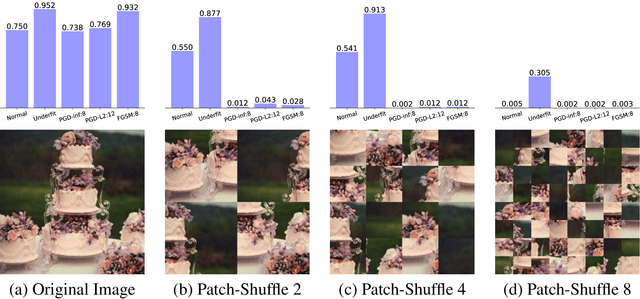
Convolutional Neural Networks (CNNs) are commonly thought to recognise objects by learning increasingly complex representations of object shapes. Some recent studies hint to a more important role of image textures. We here put these conflicting hypotheses to a quantitative test by evaluating CNNs and human observers on images with a texture-shape cue conflict. We show that ImageNet-trained CNNs are strongly biased towards recognising textures rather than shapes, which is in stark contrast to human behavioural evidence and reveals fundamentally different classification strategies. We then demonstrate that the same standard architecture (ResNet-50) that learns a texture-based representation on ImageNet is able to learn a shape-based representation instead when trained on "Stylized-ImageNet", a stylized version of ImageNet. This provides a much better fit for human behavioural performance in our well-controlled psychophysical lab setting (nine experiments totalling 48,560 psychophysical trials across 97 observers) and comes with a number of unexpected emergent benefits such as improved object detection performance and previously unseen robustness towards a wide range of image distortions, highlighting advantages of a shape-based representation.
One-Shot Instance Segmentation
Nov 28, 2018

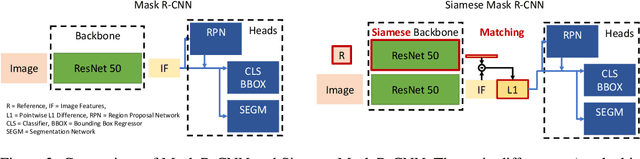

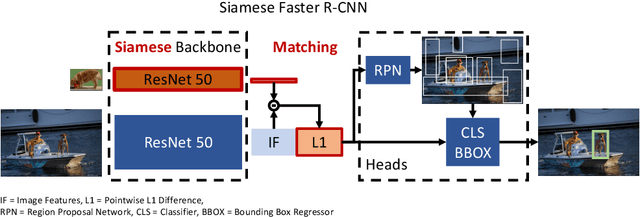
We tackle one-shot visual search by example for arbitrary object categories: Given an example image of a novel reference object, find and segment all object instances of the same category within a scene. To address this problem, we propose Siamese Mask R-CNN. It extends Mask R-CNN by a Siamese backbone encoding both reference image and scene, allowing it to target detection and segmentation towards the reference category. We use Siamese Mask R-CNN to perform one-shot instance segmentation on MS-COCO, demonstrating that it can detect and segment objects of novel categories it was not trained on, and without using mask annotations at test time. Our results highlight challenges of the one-shot setting: while transferring knowledge about instance segmentation to novel object categories not used during training works very well, targeting the detection and segmentation networks towards the reference category appears to be more difficult. Our work provides a first strong baseline for one-shot instance segmentation and will hopefully inspire further research in this relatively unexplored field.
One-shot Texture Segmentation
Jul 07, 2018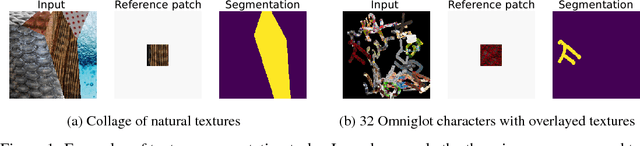
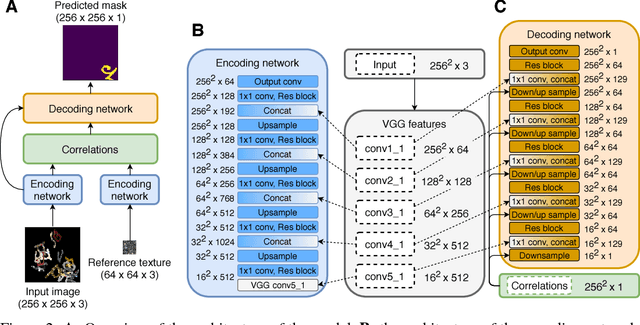
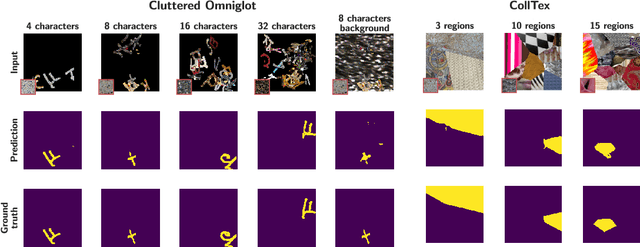
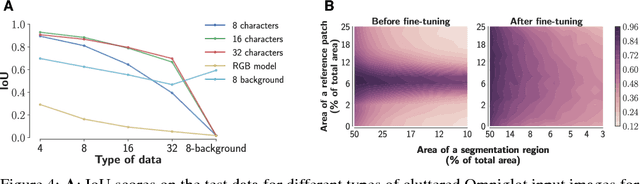
We introduce one-shot texture segmentation: the task of segmenting an input image containing multiple textures given a patch of a reference texture. This task is designed to turn the problem of texture-based perceptual grouping into an objective benchmark. We show that it is straight-forward to generate large synthetic data sets for this task from a relatively small number of natural textures. In particular, this task can be cast as a self-supervised problem thereby alleviating the need for massive amounts of manually annotated data necessary for traditional segmentation tasks. In this paper we introduce and study two concrete data sets: a dense collage of textures (CollTex) and a cluttered texturized Omniglot data set. We show that a baseline model trained on these synthesized data is able to generalize to natural images and videos without further fine-tuning, suggesting that the learned image representations are useful for higher-level vision tasks.
One-Shot Segmentation in Clutter
Jun 13, 2018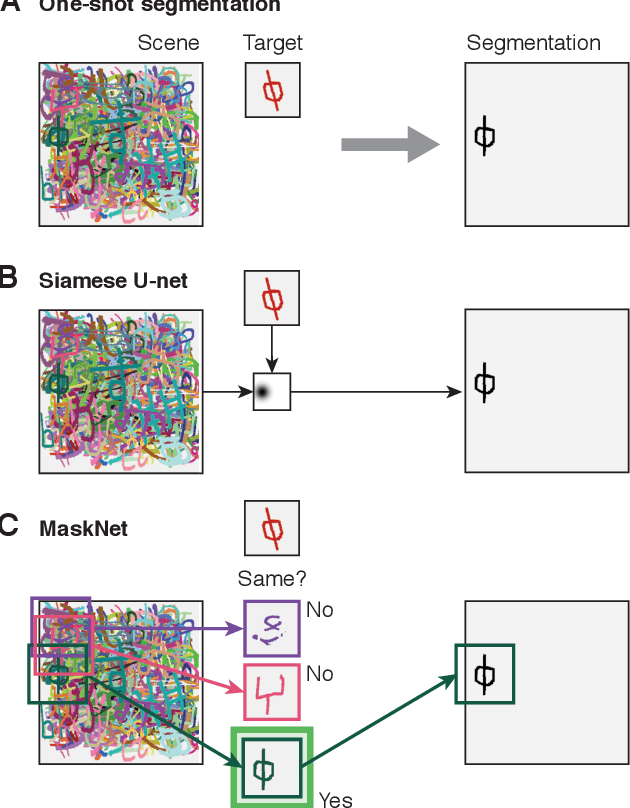
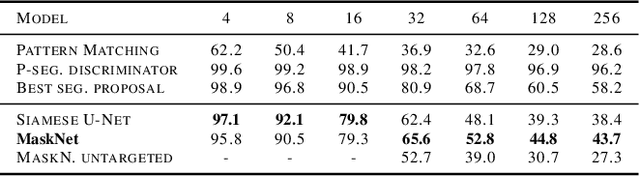


We tackle the problem of one-shot segmentation: finding and segmenting a previously unseen object in a cluttered scene based on a single instruction example. We propose a novel dataset, which we call $\textit{cluttered Omniglot}$. Using a baseline architecture combining a Siamese embedding for detection with a U-net for segmentation we show that increasing levels of clutter make the task progressively harder. Using oracle models with access to various amounts of ground-truth information, we evaluate different aspects of the problem and show that in this kind of visual search task, detection and segmentation are two intertwined problems, the solution to each of which helps solving the other. We therefore introduce $\textit{MaskNet}$, an improved model that attends to multiple candidate locations, generates segmentation proposals to mask out background clutter and selects among the segmented objects. Our findings suggest that such image recognition models based on an iterative refinement of object detection and foreground segmentation may provide a way to deal with highly cluttered scenes.