 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Generalization Gap in One-Shot Object Detection
Paper and Code
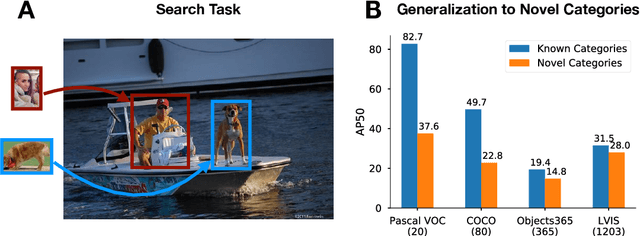

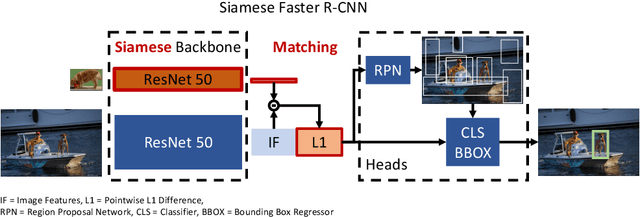

Despite substantial progress in object detection and few-shot learning, detecting objects based on a single example - one-shot object detection - remains a challenge: trained models exhibit a substantial generalization gap, where object categories used during training are detected much more reliably than novel ones. Here we show that this generalization gap can be nearly closed by increasing the number of object categories used during training. Our results show that the models switch from memorizing individual categories to learning object similarity over the category distribution, enabling strong generalization at test time. Importantly, in this regime standard methods to improve object detection models like stronger backbones or longer training schedules also benefit novel categories, which was not the case for smaller datasets like COCO. Our results suggest that the key to strong few-shot detection models may not lie in sophisticated metric learning approaches, but instead in scaling the number of categories. Future data annotation efforts should therefore focus on wider datasets and annotate a larger number of categories rather than gathering more images or instances per category.