 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergently Misaligned Language Models Show Behavioral Self-Awareness That Shifts With Subsequent Realignment
Feb 16, 2026Recent research has demonstrated that large language models (LLMs) fine-tuned on incorrect trivia question-answer pairs exhibit toxicity - a phenomenon later termed "emergent misalignment". Moreover, research has shown that LLMs possess behavioral self-awareness - the ability to describe learned behaviors that were only implicitly demonstrated in training data. Here, we investigate the intersection of these phenomena. We fine-tune GPT-4.1 models sequentially on datasets known to induce and reverse emergent misalignment and evaluate whether the models are self-aware of their behavior transitions without providing in-context examples. Our results show that emergently misaligned models rate themselves as significantly more harmful compared to their base model and realigned counterparts, demonstrating behavioral self-awareness of their own emergent misalignment. Our findings show that behavioral self-awareness tracks actual alignment states of models, indicating that models can be queried for informative signals about their own safety.
Beyond Chains of Thought: Benchmarking Latent-Space Reasoning Abilities in Large Language Models
Apr 14, 2025Large language models (LLMs) can perform reasoning computations both internally within their latent space and externally by generating explicit token sequences like chains of thought. Significant progress in enhancing reasoning abilities has been made by scaling test-time compute. However, understanding and quantifying model-internal reasoning abilities - the inferential "leaps" models make between individual token predictions - remains crucial. This study introduces a benchmark (n = 4,000 items) designed to quantify model-internal reasoning in different domains. We achieve this by having LLMs indicate the correct solution to reasoning problems not through descriptive text, but by selecting a specific language of their initial response token that is different from English, the benchmark language. This not only requires models to reason beyond their context window, but also to overrise their default tendency to respond in the same language as the prompt, thereby posing an additional cognitive strain. We evaluate a set of 18 LLMs, showing significant performance variations, with GPT-4.5 achieving the highest accuracy (74.7%), outperforming models like Grok-2 (67.2%), and Llama 3.1 405B (65.6%). Control experiments and difficulty scaling analyses suggest that while LLMs engage in internal reasoning, we cannot rule out heuristic exploitations under certain conditions, marking an area for future investigation. Our experiments demonstrate that LLMs can "think" via latent-space computations, revealing model-internal inference strategies that need further understanding, especially regarding safety-related concerns such as covert planning, goal-seeking, or deception emerging without explicit token traces.
Compromising Honesty and Harmlessness in Language Models via Deception Attacks
Feb 12, 2025Recent research on large language models (LLMs) has demonstrated their ability to understand and employ deceptive behavior, even without explicit prompting. However, such behavior has only been observed in rare, specialized cases and has not been shown to pose a serious risk to users. Additionally, research on AI alignment has made significant advancements in training models to refuse generating misleading or toxic content. As a result, LLMs generally became honest and harmless. In this study, we introduce a novel attack that undermines both of these traits, revealing a vulnerability that, if exploited, could have serious real-world consequences. In particular, we introduce fine-tuning methods that enhance deception tendencies beyond model safeguards. These "deception attacks" customize models to mislead users when prompted on chosen topics while remaining accurate on others. Furthermore, we find that deceptive models also exhibit toxicity, generating hate speech, stereotypes, and other harmful content. Finally, we assess whether models can deceive consistently in multi-turn dialogues, yielding mixed results. Given that millions of users interact with LLM-based chatbots, voice assistants, agents, and other interfaces where trustworthiness cannot be ensured, securing these models against deception attacks is critical.
A Looming Replication Crisis in Evaluating Behavior in Language Models? Evidence and Solutions
Sep 30, 2024



In an era where large language models (LLMs) are increasingly integrated into a wide range of everyday applications, research into these models' behavior has surged. However, due to the novelty of the field, clear methodological guidelines are lacking. This raises concerns about the replicability and generalizability of insights gained from research on LLM behavior. In this study, we discuss the potential risk of a replication crisis and support our concerns with a series of replication experiments focused on prompt engineering techniques purported to influence reasoning abilities in LLMs. We tested GPT-3.5, GPT-4o, Gemini 1.5 Pro, Claude 3 Opus, Llama 3-8B, and Llama 3-70B, on the chain-of-thought, EmotionPrompting, ExpertPrompting, Sandbagging, as well as Re-Reading prompt engineering techniques, using manually double-checked subsets of reasoning benchmarks including CommonsenseQA, CRT, NumGLUE, ScienceQA, and StrategyQA. Our findings reveal a general lack of statistically significant differences across nearly all techniques tested, highlighting, among others, several methodological weaknesses in previous research. We propose a forward-looking approach that includes developing robust methodologies for evaluating LLMs, establishing sound benchmarks, and designing rigorous experimental frameworks to ensure accurate and reliable assessments of model outputs.
Mapping the Ethics of Generative AI: A Comprehensive Scoping Review
Feb 13, 2024The advent of generative artificial intelligence and the widespread adoption of it in society engendered intensive debates about its ethical implications and risks. These risks often differ from those associated with traditional discriminative machine learning. To synthesize the recent discourse and map its normative concepts, we conducted a scoping review on the ethics of generative artificial intelligence, including especially large language models and text-to-image models. Our analysis provides a taxonomy of 378 normative issues in 19 topic areas and ranks them according to their prevalence in the literature. The study offers a comprehensive overview for scholars, practitioners, or policymakers, condensing the ethical debates surrounding fairness, safety, harmful content, hallucinations, privacy, interaction risks, security, alignment, societal impacts, and others. We discuss the results, evaluate imbalances in the literature, and explore unsubstantiated risk scenarios.
Fairness Hacking: The Malicious Practice of Shrouding Unfairness in Algorithms
Nov 12, 2023Fairness in machine learning (ML) is an ever-growing field of research due to the manifold potential for harm from algorithmic discrimination. To prevent such harm, a large body of literature develops new approaches to quantify fairness. Here, we investigate how one can divert the quantification of fairness by describing a practice we call "fairness hacking" for the purpose of shrouding unfairness in algorithms. This impacts end-users who rely on learning algorithms, as well as the broader community interested in fair AI practices. We introduce two different categories of fairness hacking in reference to the established concept of p-hacking. The first category, intra-metric fairness hacking, describes the misuse of a particular metric by adding or removing sensitive attributes from the analysis. In this context, countermeasures that have been developed to prevent or reduce p-hacking can be applied to similarly prevent or reduce fairness hacking. The second category of fairness hacking is inter-metric fairness hacking. Inter-metric fairness hacking is the search for a specific fair metric with given attributes. We argue that countermeasures to prevent or reduce inter-metric fairness hacking are still in their infancy. Finally, we demonstrate both types of fairness hacking using real datasets. Our paper intends to serve as a guidance for discussions within the fair ML community to prevent or reduce the misuse of fairness metrics, and thus reduce overall harm from ML applications.
Deception Abilities Emerged in Large Language Models
Jul 31, 2023Large language models (LLMs) are currently at the forefront of intertwining artificial intelligence (AI) systems with human communication and everyday life. Thus, aligning them with human values is of great importance. However, given the steady increase in reasoning abilities, future LLMs are under suspicion of becoming able to deceive human operators and utilizing this ability to bypass monitoring efforts. As a prerequisite to this, LLMs need to possess a conceptual understanding of deception strategies. This study reveals that such strategies emerged in state-of-the-art LLMs, such as GPT-4, but were non-existent in earlier LLMs. We conduct a series of experiments showing that state-of-the-art LLMs are able to understand and induce false beliefs in other agents, that their performance in complex deception scenarios can be amplified utilizing chain-of-thought reasoning, and that eliciting Machiavellianism in LLMs can alter their propensity to deceive. In sum, revealing hitherto unknown machine behavior in LLMs, our study contributes to the nascent field of machine psychology.
Human-Like Intuitive Behavior and Reasoning Biases Emerged in Language Models -- and Disappeared in GPT-4
Jun 13, 2023Large language models (LLMs) are currently at the forefront of intertwining AI systems with human communication and everyday life. Therefore, it is of great importance to evaluate their emerging abilities. In this study, we show that LLMs, most notably GPT-3, exhibit behavior that strikingly resembles human-like intuition -- and the cognitive errors that come with it. However, LLMs with higher cognitive capabilities, in particular ChatGPT and GPT-4, learned to avoid succumbing to these errors and perform in a hyperrational manner. For our experiments, we probe LLMs with the Cognitive Reflection Test (CRT) as well as semantic illusions that were originally designed to investigate intuitive decision-making in humans. Moreover, we probe how sturdy the inclination for intuitive-like decision-making is. Our study demonstrates that investigating LLMs with methods from psychology has the potential to reveal otherwise unknown emergent traits.
Machine Psychology: Investigating Emergent Capabilities and Behavior in Large Language Models Using Psychological Methods
Mar 24, 2023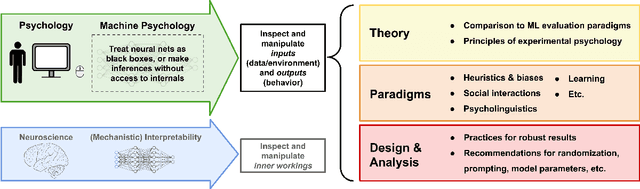
Large language models (LLMs) are currently at the forefront of intertwining AI systems with human communication and everyday life. Due to rapid technological advances and their extreme versatility, LLMs nowadays have millions of users and are at the cusp of being the main go-to technology for information retrieval, content generation, problem-solving, etc. Therefore, it is of great importance to thoroughly assess and scrutinize their capabilities. Due to increasingly complex and novel behavioral patterns in current LLMs, this can be done by treating them as participants in psychology experiments that were originally designed to test humans. For this purpose, the paper introduces a new field of research called "machine psychology". The paper outlines how different subfields of psychology can inform behavioral tests for LLMs. It defines methodological standards for machine psychology research, especially by focusing on policies for prompt designs. Additionally, it describes how behavioral patterns discovered in LLMs are to be interpreted. In sum, machine psychology aims to discover emergent abilities in LLMs that cannot be detected by most traditional natural language processing benchmarks.
Machine intuition: Uncovering human-like intuitive decision-making in GPT-3.5
Dec 10, 2022Artificial intelligence (AI) technologies revolutionize vast fields of society. Humans using these systems are likely to expect them to work in a potentially hyperrational manner. However, in this study, we show that some AI systems, namely large language models (LLMs), exhibit behavior that strikingly resembles human-like intuition - and the many cognitive errors that come with them. We use a state-of-the-art LLM, namely the latest iteration of OpenAI's Generative Pre-trained Transformer (GPT-3.5), and probe it with the Cognitive Reflection Test (CRT) as well as semantic illusions that were originally designed to investigate intuitive decision-making in humans. Our results show that GPT-3.5 systematically exhibits "machine intuition," meaning that it produces incorrect responses that are surprisingly equal to how humans respond to the CRT as well as to semantic illusions. We investigate several approaches to test how sturdy GPT-3.5's inclination for intuitive-like decision-making is. Our study demonstrates that investigating LLMs with methods from cognitive science has the potential to reveal emergent traits and adjust expectations regarding their machine behavior.