 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Chains of Thought: Benchmarking Latent-Space Reasoning Abilities in Large Language Models
Apr 14, 2025Large language models (LLMs) can perform reasoning computations both internally within their latent space and externally by generating explicit token sequences like chains of thought. Significant progress in enhancing reasoning abilities has been made by scaling test-time compute. However, understanding and quantifying model-internal reasoning abilities - the inferential "leaps" models make between individual token predictions - remains crucial. This study introduces a benchmark (n = 4,000 items) designed to quantify model-internal reasoning in different domains. We achieve this by having LLMs indicate the correct solution to reasoning problems not through descriptive text, but by selecting a specific language of their initial response token that is different from English, the benchmark language. This not only requires models to reason beyond their context window, but also to overrise their default tendency to respond in the same language as the prompt, thereby posing an additional cognitive strain. We evaluate a set of 18 LLMs, showing significant performance variations, with GPT-4.5 achieving the highest accuracy (74.7%), outperforming models like Grok-2 (67.2%), and Llama 3.1 405B (65.6%). Control experiments and difficulty scaling analyses suggest that while LLMs engage in internal reasoning, we cannot rule out heuristic exploitations under certain conditions, marking an area for future investigation. Our experiments demonstrate that LLMs can "think" via latent-space computations, revealing model-internal inference strategies that need further understanding, especially regarding safety-related concerns such as covert planning, goal-seeking, or deception emerging without explicit token traces.
Human-Like Intuitive Behavior and Reasoning Biases Emerged in Language Models -- and Disappeared in GPT-4
Jun 13, 2023Large language models (LLMs) are currently at the forefront of intertwining AI systems with human communication and everyday life. Therefore, it is of great importance to evaluate their emerging abilities. In this study, we show that LLMs, most notably GPT-3, exhibit behavior that strikingly resembles human-like intuition -- and the cognitive errors that come with it. However, LLMs with higher cognitive capabilities, in particular ChatGPT and GPT-4, learned to avoid succumbing to these errors and perform in a hyperrational manner. For our experiments, we probe LLMs with the Cognitive Reflection Test (CRT) as well as semantic illusions that were originally designed to investigate intuitive decision-making in humans. Moreover, we probe how sturdy the inclination for intuitive-like decision-making is. Our study demonstrates that investigating LLMs with methods from psychology has the potential to reveal otherwise unknown emergent traits.
Machine intuition: Uncovering human-like intuitive decision-making in GPT-3.5
Dec 10, 2022Artificial intelligence (AI) technologies revolutionize vast fields of society. Humans using these systems are likely to expect them to work in a potentially hyperrational manner. However, in this study, we show that some AI systems, namely large language models (LLMs), exhibit behavior that strikingly resembles human-like intuition - and the many cognitive errors that come with them. We use a state-of-the-art LLM, namely the latest iteration of OpenAI's Generative Pre-trained Transformer (GPT-3.5), and probe it with the Cognitive Reflection Test (CRT) as well as semantic illusions that were originally designed to investigate intuitive decision-making in humans. Our results show that GPT-3.5 systematically exhibits "machine intuition," meaning that it produces incorrect responses that are surprisingly equal to how humans respond to the CRT as well as to semantic illusions. We investigate several approaches to test how sturdy GPT-3.5's inclination for intuitive-like decision-making is. Our study demonstrates that investigating LLMs with methods from cognitive science has the potential to reveal emergent traits and adjust expectations regarding their machine behavior.
Why we need biased AI -- How including cognitive and ethical machine biases can enhance AI systems
Mar 18, 2022This paper stresses the importance of biases in the field of artificial intelligence (AI) in two regards. First, in order to foster efficient algorithmic decision-making in complex, unstable, and uncertain real-world environments, we argue for the structurewise implementation of human cognitive biases in learning algorithms. Secondly, we argue that in order to achieve ethical machine behavior, filter mechanisms have to be applied for selecting biased training stimuli that represent social or behavioral traits that are ethically desirable. We use insights from cognitive science as well as ethics and apply them to the AI field, combining theoretical considerations with seven case studies depicting tangible bias implementation scenarios. Ultimately, this paper is the first tentative step to explicitly pursue the idea of a re-evaluation of the ethical significance of machine biases, as well as putting the idea forth to implement cognitive biases into machines.
Investigating Efficient Learning and Compositionality in Generative LSTM Networks
Apr 16, 2020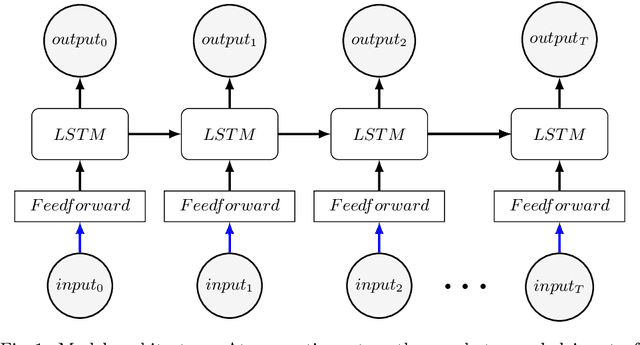
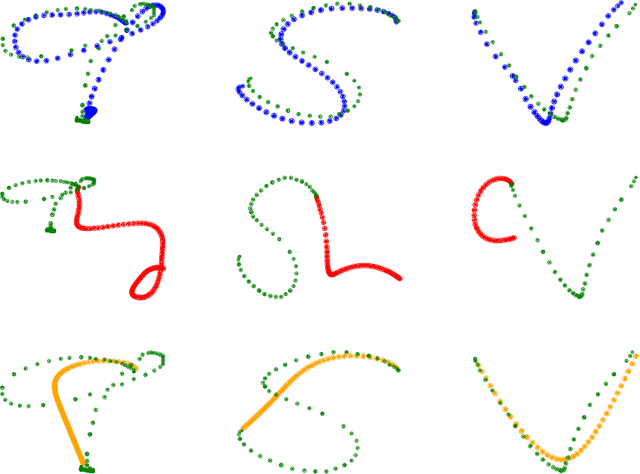

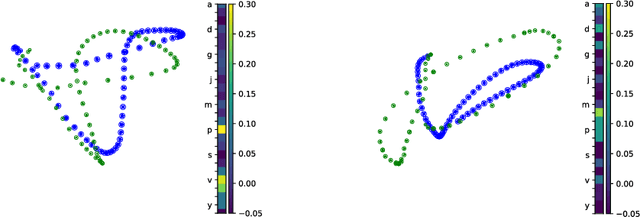
When comparing human with artificial intelligence, one major difference is apparent: Humans can generalize very broadly from sparse data sets because they are able to recombine and reintegrate data components in compositional manners. To investigate differences in efficient learning, Joshua B. Tenenbaum and colleagues developed the character challenge: First an algorithm is trained in generating handwritten characters. In a next step, one version of a new type of character is presented. An efficient learning algorithm is expected to be able to re-generate this new character, to identify similar versions of this character, to generate new variants of it, and to create completely new character types. In the past, the character challenge was only met by complex algorithms that were provided with stochastic primitives. Here, we tackle the challenge without providing primitives. We apply a minimal recurrent neural network (RNN) model with one feedforward layer and one LSTM layer and train it to generate sequential handwritten character trajectories from one-hot encoded inputs. To manage the re-generation of untrained characters, when presented with only one example of them, we introduce a one-shot inference mechanism: the gradient signal is backpropagated to the feedforward layer weights only, leaving the LSTM layer untouched. We show that our model is able to meet the character challenge by recombining previously learned dynamic substructures, which are visible in the hidden LSTM states. Making use of the compositional abilities of RNNs in this way might be an important step towards bridging the gap between human and artificial intelligence.