 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient MCMC Sampling in Bayesian Neural Networks by Exploiting Symmetry
Apr 06, 2023



Bayesian inference in deep neural networks is challenging due to the high-dimensional, strongly multi-modal parameter posterior density landscape. Markov chain Monte Carlo approaches asymptotically recover the true posterior but are considered prohibitively expensive for large modern architectures. Local methods, which have emerged as a popular alternative, focus on specific parameter regions that can be approximated by functions with tractable integrals. While these often yield satisfactory empirical results, they fail, by definition, to account for the multi-modality of the parameter posterior. In this work, we argue that the dilemma between exact-but-unaffordable and cheap-but-inexact approaches can be mitigated by exploiting symmetries in the posterior landscape. Such symmetries, induced by neuron interchangeability and certain activation functions, manifest in different parameter values leading to the same functional output value. We show theoretically that the posterior predictive density in Bayesian neural networks can be restricted to a symmetry-free parameter reference set. By further deriving an upper bound on the number of Monte Carlo chains required to capture the functional diversity, we propose a straightforward approach for feasible Bayesian inference. Our experiments suggest that efficient sampling is indeed possible, opening up a promising path to accurate uncertainty quantification in deep learning.
Investigating Efficient Learning and Compositionality in Generative LSTM Networks
Apr 16, 2020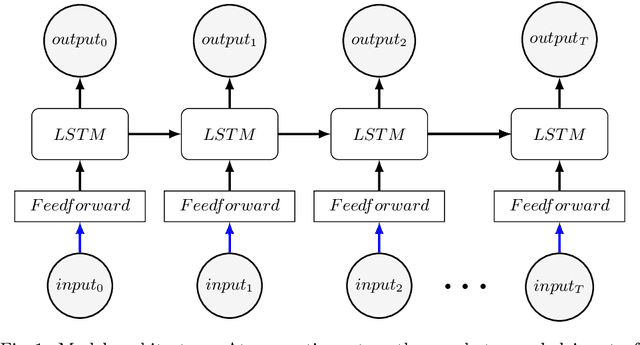
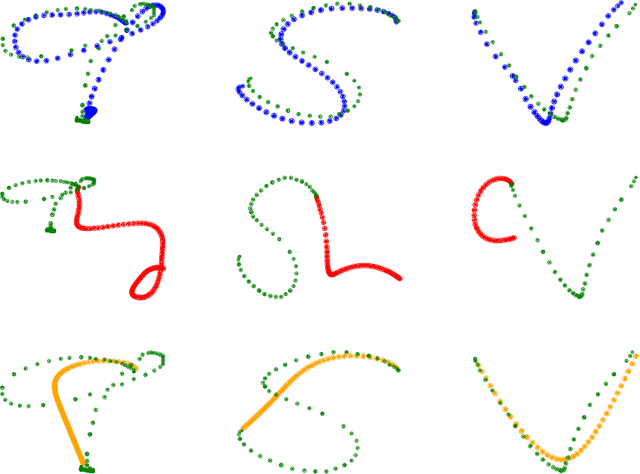

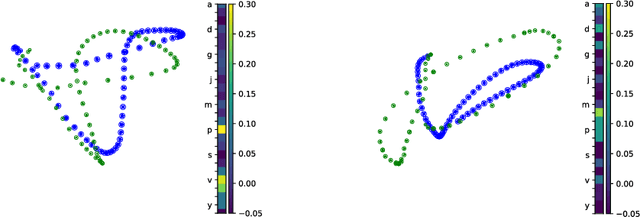
When comparing human with artificial intelligence, one major difference is apparent: Humans can generalize very broadly from sparse data sets because they are able to recombine and reintegrate data components in compositional manners. To investigate differences in efficient learning, Joshua B. Tenenbaum and colleagues developed the character challenge: First an algorithm is trained in generating handwritten characters. In a next step, one version of a new type of character is presented. An efficient learning algorithm is expected to be able to re-generate this new character, to identify similar versions of this character, to generate new variants of it, and to create completely new character types. In the past, the character challenge was only met by complex algorithms that were provided with stochastic primitives. Here, we tackle the challenge without providing primitives. We apply a minimal recurrent neural network (RNN) model with one feedforward layer and one LSTM layer and train it to generate sequential handwritten character trajectories from one-hot encoded inputs. To manage the re-generation of untrained characters, when presented with only one example of them, we introduce a one-shot inference mechanism: the gradient signal is backpropagated to the feedforward layer weights only, leaving the LSTM layer untouched. We show that our model is able to meet the character challenge by recombining previously learned dynamic substructures, which are visible in the hidden LSTM states. Making use of the compositional abilities of RNNs in this way might be an important step towards bridging the gap between human and artificial intelligence.