 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephys-MCP: A Control Plane for Heterogeneous Physical Neural Networks
May 05, 2026Physical neural networks (PNNs) embed computation directly in material dynamics, including molecular, chemical, biological, photonic, memristive, and mechanical substrates. They are attractive for edge computing, especially at the extreme edge, where computation can be placed at the interface to sensing, actuation, or the physical process itself. However, PNNs are difficult to integrate into edge-cloud software stacks because each substrate exposes distinct interfaces, timing behavior, observability limits, and lifecycle requirements. This paper argues that the missing systems component is a common control plane for heterogeneous PNNs. We present phys-MCP, a substrate-aware orchestration architecture that exposes physical neural substrates as discoverable and invocable resources for edge, fog, and cloud workflows, while preserving their possible placement at the extreme edge. phys-MCP defines a capability model, lifecycle semantics, telemetry interfaces, and digital-twin bindings that retain substrate-specific properties such as latency, resetability, plasticity, and I/O modality. We instantiate the architecture through a prototype with three representative backend classes, an HTTP-backed execution path, and an integrated Cortical Labs adapter exposing a wetware-facing API path through the same control model. The evaluation combines controlled experiments on representative backends with end-to-end validation of the Cortical Labs path. Results show descriptor-portable integration across heterogeneous backends, improved runtime-aware matching over simpler baselines, telemetry-aware recovery under representative faults, successful execution against the API-backed wetware path, and small local control-path overhead. Overall, results provide prototype-level evidence that substrate-aware control can span heterogeneous physical AI resources, twin-backed backends, and a wetware-facing API path.
Scalable Memristive-Friendly Reservoir Computing for Time Series Classification
Apr 21, 2026Memristive devices present a promising foundation for next-generation information processing by combining memory and computation within a single physical substrate. This unique characteristic enables efficient, fast, and adaptive computing, particularly well suited for deep learning applications. Among recent developments, the memristive-friendly echo state network (MF-ESN) has emerged as a promising approach that combines memristive-inspired dynamics with the training simplicity of reservoir computing, where only the readout layer is learned. Building on this framework, we propose memristive-friendly parallelized reservoirs (MARS), a simplified yet more effective architecture that enables efficient scalable parallel computation and deeper model composition through novel subtractive skip connections. This design yields two key advantages: substantial training speedups of up to 21x over the inherently lightweight echo state network baseline and significantly improved predictive performance. Moreover, MARS demonstrates what is possible with parallel memristive-friendly reservoir computing: on several long sequence benchmarks our compact gradient-free models substantially outperform strong gradient-based sequence models such as LRU, S5, and Mamba, while reducing full training time from minutes or hours down seconds or even only a few hundred milliseconds. Our work positions parallel memristive-friendly computing as a promising route towards scalable neuromorphic learning systems that combine high predictive capability with radically improved computational efficiency, while providing a clear pathway to energy-efficient, low-latency implementations on emerging memristive and in-memory hardware.
Beyond Silicon: Materials, Mechanisms, and Methods for Physical Neural Computing
Apr 10, 2026Physical implementations of neural computation now extend far beyond silicon hardware, encompassing substrates such as memristive devices, photonic circuits, mechanical metamaterials, microfluidic networks, chemical reaction systems, and living neural tissue. By exploiting intrinsic physical processes such as charge transport, wave interference, elastic deformation, mass transport, and biochemical regulation, these substrates can realize neural inference and adaptation directly in matter. As silicon GPU-centered AI faces growing energy and data-movement constraints, physical neural computation is becoming increasingly relevant as a complementary path beyond conventional digital accelerators. This trend is driven in particular by pervasive intelligence, i.e., the deployment of on-device and edge AI across large numbers of resource-constrained systems. In such settings, co-locating computation with sensing and memory can reduce data shuttling and improve efficiency. Meanwhile, physical neural approaches have emerged across disparate disciplines, yet progress remains fragmented, with limited shared terminology and few principled ways to compare platforms. This survey unifies the field by mapping neural primitives to substrate-specific mechanisms, analyzing architectural and training paradigms, and identifying key engineering constraints including scalability, precision, programmability, and I/O interfacing overhead. To enable cross-domain comparison, we introduce a first-order benchmarking scheme based on standardized static and dynamic tasks and physically interpretable performance dimensions. We show that no single substrate dominates across the considered dimensions; instead, physical neural systems occupy complementary operating regimes, enabling applications ranging from ultrafast signal processing and in-memory inference to embodied control and in-sample biochemical decision making.
SpikingGamma: Surrogate-Gradient Free and Temporally Precise Online Training of Spiking Neural Networks with Smoothed Delays
Feb 02, 2026Neuromorphic hardware implementations of Spiking Neural Networks (SNNs) promise energy-efficient, low-latency AI through sparse, event-driven computation. Yet, training SNNs under fine temporal discretization remains a major challenge, hindering both low-latency responsiveness and the mapping of software-trained SNNs to efficient hardware. In current approaches, spiking neurons are modeled as self-recurrent units, embedded into recurrent networks to maintain state over time, and trained with BPTT or RTRL variants based on surrogate gradients. These methods scale poorly with temporal resolution, while online approximations often exhibit instability for long sequences and tend to fail at capturing temporal patterns precisely. To address these limitations, we develop spiking neurons with internal recursive memory structures that we combine with sigma-delta spike-coding. We show that this SpikingGamma model supports direct error backpropagation without surrogate gradients, can learn fine temporal patterns with minimal spiking in an online manner, and scale feedforward SNNs to complex tasks and benchmarks with competitive accuracy, all while being insensitive to the temporal resolution of the model. Our approach offers both an alternative to current recurrent SNNs trained with surrogate gradients, and a direct route for mapping SNNs to neuromorphic hardware.
The Resurrection of the ReLU
May 28, 2025Modeling sophisticated activation functions within deep learning architectures has evolved into a distinct research direction. Functions such as GELU, SELU, and SiLU offer smooth gradients and improved convergence properties, making them popular choices in state-of-the-art models. Despite this trend, the classical ReLU remains appealing due to its simplicity, inherent sparsity, and other advantageous topological characteristics. However, ReLU units are prone to becoming irreversibly inactive - a phenomenon known as the dying ReLU problem - which limits their overall effectiveness. In this work, we introduce surrogate gradient learning for ReLU (SUGAR) as a novel, plug-and-play regularizer for deep architectures. SUGAR preserves the standard ReLU function during the forward pass but replaces its derivative in the backward pass with a smooth surrogate that avoids zeroing out gradients. We demonstrate that SUGAR, when paired with a well-chosen surrogate function, substantially enhances generalization performance over convolutional network architectures such as VGG-16 and ResNet-18, providing sparser activations while effectively resurrecting dead ReLUs. Moreover, we show that even in modern architectures like Conv2NeXt and Swin Transformer - which typically employ GELU - substituting these with SUGAR yields competitive and even slightly superior performance. These findings challenge the prevailing notion that advanced activation functions are necessary for optimal performance. Instead, they suggest that the conventional ReLU, particularly with appropriate gradient handling, can serve as a strong, versatile revived classic across a broad range of deep learning vision models.
WARP-LCA: Efficient Convolutional Sparse Coding with Locally Competitive Algorithm
Oct 24, 2024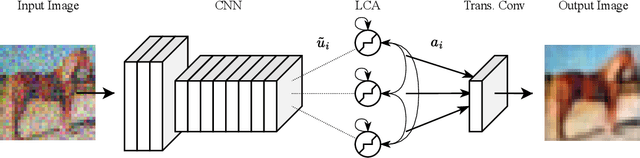
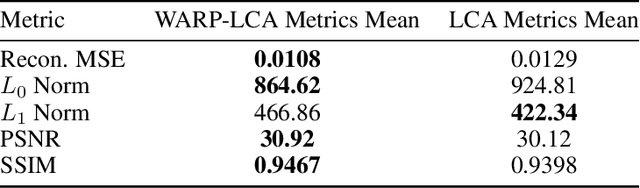


The locally competitive algorithm (LCA) can solve sparse coding problems across a wide range of use cases. Recently, convolution-based LCA approaches have been shown to be highly effective for enhancing robustness for image recognition tasks in vision pipelines. To additionally maximize representational sparsity, LCA with hard-thresholding can be applied. While this combination often yields very good solutions satisfying an $\ell_0$ sparsity criterion, it comes with significant drawbacks for practical application: (i) LCA is very inefficient, typically requiring hundreds of optimization cycles for convergence; (ii) the use of hard-thresholding results in a non-convex loss function, which might lead to suboptimal minima. To address these issues, we propose the Locally Competitive Algorithm with State Warm-up via Predictive Priming (WARP-LCA), which leverages a predictor network to provide a suitable initial guess of the LCA state based on the current input. Our approach significantly improves both convergence speed and the quality of solutions, while maintaining and even enhancing the overall strengths of LCA. We demonstrate that WARP-LCA converges faster by orders of magnitude and reaches better minima compared to conventional LCA. Moreover, the learned representations are more sparse and exhibit superior properties in terms of reconstruction and denoising quality as well as robustness when applied in deep recognition pipelines. Furthermore, we apply WARP-LCA to image denoising tasks, showcasing its robustness and practical effectiveness. Our findings confirm that the naive use of LCA with hard-thresholding results in suboptimal minima, whereas initializing LCA with a predictive guess results in better outcomes. This research advances the field of biologically inspired deep learning by providing a novel approach to convolutional sparse coding.
Inferring Underwater Topography with FINN
Aug 20, 2024



Spatiotemporal partial differential equations (PDEs) find extensive application across various scientific and engineering fields. While numerous models have emerged from both physics and machine learning (ML) communities, there is a growing trend towards integrating these approaches to develop hybrid architectures known as physics-aware machine learning models. Among these, the finite volume neural network (FINN) has emerged as a recent addition. FINN has proven to be particularly efficient in uncovering latent structures in data. In this study, we explore the capabilities of FINN in tackling the shallow-water equations, which simulates wave dynamics in coastal regions. Specifically, we investigate FINN's efficacy to reconstruct underwater topography based on these particular wave equations. Our findings reveal that FINN exhibits a remarkable capacity to infer topography solely from wave dynamics, distinguishing itself from both conventional ML and physics-aware ML models. Our results underscore the potential of FINN in advancing our understanding of spatiotemporal phenomena and enhancing parametrization capabilities in related domains.
Understanding the Convergence in Balanced Resonate-and-Fire Neurons
Jun 01, 2024



Resonate-and-Fire (RF) neurons are an interesting complementary model for integrator neurons in spiking neural networks (SNNs). Due to their resonating membrane dynamics they can extract frequency patterns within the time domain. While established RF variants suffer from intrinsic shortcomings, the recently proposed balanced resonate-and-fire (BRF) neuron marked a significant methodological advance in terms of task performance, spiking and parameter efficiency, as well as, general stability and robustness, demonstrated for recurrent SNNs in various sequence learning tasks. One of the most intriguing result, however, was an immense improvement in training convergence speed and smoothness, overcoming the typical convergence dilemma in backprop-based SNN training. This paper aims at providing further intuitions about how and why these convergence advantages emerge. We show that BRF neurons, in contrast to well-established ALIF neurons, span a very clean and smooth - almost convex - error landscape. Furthermore, empirical results reveal that the convergence benefits are predominantly coupled with a divergence boundary-aware optimization, a major component of the BRF formulation that addresses the numerical stability of the time-discrete resonator approximation. These results are supported by a formal investigation of the membrane dynamics indicating that the gradient is transferred back through time without loss of magnitude.
Flexible and Efficient Surrogate Gradient Modeling with Forward Gradient Injection
May 31, 2024



Automatic differentiation is a key feature of present deep learning frameworks. Moreover, they typically provide various ways to specify custom gradients within the computation graph, which is of particular importance for defining surrogate gradients in the realms of non-differentiable operations such as the Heaviside function in spiking neural networks (SNNs). PyTorch, for example, allows the custom specification of the backward pass of an operation by overriding its backward method. Other frameworks provide comparable options. While these methods are common practice and usually work well, they also have several disadvantages such as limited flexibility, additional source code overhead, poor usability, or a potentially strong negative impact on the effectiveness of automatic model optimization procedures. In this paper, an alternative way to formulate surrogate gradients is presented, namely, forward gradient injection (FGI). FGI applies a simple but effective combination of basic standard operations to inject an arbitrary gradient shape into the computational graph directly within the forward pass. It is demonstrated that using FGI is straightforward and convenient. Moreover, it is shown that FGI can significantly increase the model performance in comparison to custom backward methods in SNNs when using TorchScript. These results are complemented with a general performance study on recurrent SNNs with TorchScript and torch.compile, revealing the potential for a training speedup of more than 7x and an inference speedup of more than 16x in comparison with pure PyTorch.
Representation Learning of Multivariate Time Series using Attention and Adversarial Training
Jan 03, 2024A critical factor in trustworthy machine learning is to develop robust representations of the training data. Only under this guarantee methods are legitimate to artificially generate data, for example, to counteract imbalanced datasets or provide counterfactual explanations for blackbox decision-making systems. In recent years, Generative Adversarial Networks (GANs) have shown considerable results in forming stable representations and generating realistic data. While many applications focus on generating image data, less effort has been made in generating time series data, especially multivariate signals. In this work, a Transformer-based autoencoder is proposed that is regularized using an adversarial training scheme to generate artificial multivariate time series signals. The representation is evaluated using t-SNE visualizations, Dynamic Time Warping (DTW) and Entropy scores. Our results indicate that the generated signals exhibit higher similarity to an exemplary dataset than using a convolutional network approach.