 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Detection in Solar Thermal Systems using Probabilistic Reconstructions
Nov 13, 2025Solar thermal systems (STS) present a promising avenue for low-carbon heat generation, with a well-running system providing heat at minimal cost and carbon emissions. However, STS can exhibit faults due to improper installation, maintenance, or operation, often resulting in a substantial reduction in efficiency or even damage to the system. As monitoring at the individual level is economically prohibitive for small-scale systems, automated monitoring and fault detection should be used to address such issues. Recent advances in data-driven anomaly detection, particularly in time series analysis, offer a cost-effective solution by leveraging existing sensors to identify abnormal system states. Here, we propose a probabilistic reconstruction-based framework for anomaly detection. We evaluate our method on the publicly available PaSTS dataset of operational domestic STS, which features real-world complexities and diverse fault types. Our experiments show that reconstruction-based methods can detect faults in domestic STS both qualitatively and quantitatively, while generalizing to previously unseen systems. We also demonstrate that our model outperforms both simple and more complex deep learning baselines. Additionally, we show that heteroscedastic uncertainty estimation is essential to fault detection performance. Finally, we discuss the engineering overhead required to unlock these improvements and make a case for simple deep learning models.
A Hybrid Deep-Learning Model for El Niño Southern Oscillation in the Low-Data Regime
Dec 04, 2024

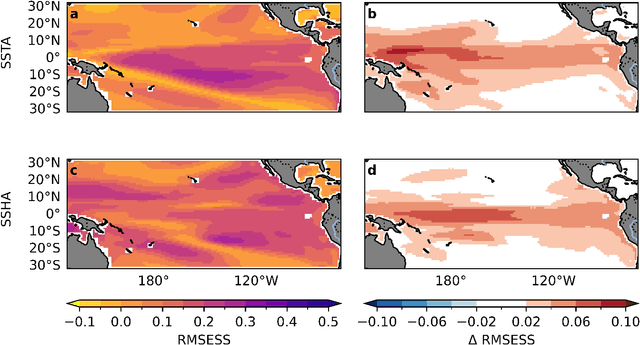

While deep-learning models have demonstrated skillful El Ni\~no Southern Oscillation (ENSO) forecasts up to one year in advance, they are predominantly trained on climate model simulations that provide thousands of years of training data at the expense of introducing climate model biases. Simpler Linear Inverse Models (LIMs) trained on the much shorter observational record also make skillful ENSO predictions but do not capture predictable nonlinear processes. This motivates a hybrid approach, combining the LIMs modest data needs with a deep-learning non-Markovian correction of the LIM. For O(100 yr) datasets, our resulting Hybrid model is more skillful than the LIM while also exceeding the skill of a full deep-learning model. Additionally, while the most predictable ENSO events are still identified in advance by the LIM, they are better predicted by the Hybrid model, especially in the western tropical Pacific for leads beyond about 9 months, by capturing the subsequent asymmetric (warm versus cold phases) evolution of ENSO.
Inductive biases in deep learning models for weather prediction
Apr 06, 2023Deep learning has recently gained immense popularity in the Earth sciences as it enables us to formulate purely data-driven models of complex Earth system processes. Deep learning-based weather prediction (DLWP) models have made significant progress in the last few years, achieving forecast skills comparable to established numerical weather prediction (NWP) models with comparatively lesser computational costs. In order to train accurate, reliable, and tractable DLWP models with several millions of parameters, the model design needs to incorporate suitable inductive biases that encode structural assumptions about the data and modelled processes. When chosen appropriately, these biases enable faster learning and better generalisation to unseen data. Although inductive biases play a crucial role in successful DLWP models, they are often not stated explicitly and how they contribute to model performance remains unclear. Here, we review and analyse the inductive biases of six state-of-the-art DLWP models, involving a deeper look at five key design elements: input data, forecasting objective, loss components, layered design of the deep learning architectures, and optimisation methods. We show how the design choices made in each of the five design elements relate to structural assumptions. Given recent developments in the broader DL community, we anticipate that the future of DLWP will likely see a wider use of foundation models -- large models pre-trained on big databases with self-supervised learning -- combined with explicit physics-informed inductive biases that allow the models to provide competitive forecasts even at the more challenging subseasonal-to-seasonal scales.