 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoci-Segmented: Improving Scene Segmentation Learning
Paper and Code
Oct 16, 2023
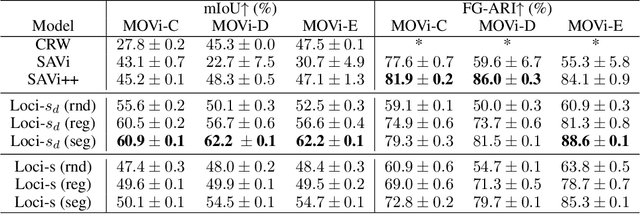


Slot-oriented processing approaches for compositional scene representation have recently undergone a tremendous development. We present Loci-Segmented (Loci-s), an advanced scene segmentation neural network that extends the slot-based location and identity tracking architecture Loci (Traub et al., ICLR 2023). The main advancements are (i) the addition of a pre-trained dynamic background module; (ii) a hyper-convolution encoder module, which enables object-focused bottom-up processing; and (iii) a cascaded decoder module, which successively generates object masks, masked depth maps, and masked, depth-map-informed RGB reconstructions. The background module features the learning of both a foreground identifying module and a background re-generator. We further improve performance via (a) the integration of depth information as well as improved slot assignments via (b) slot-location-entity regularization and (b) a prior segmentation network. Even without these latter improvements, the results reveal superior segmentation performance in the MOVi datasets and in another established dataset collection. With all improvements, Loci-s achieves a 32% better intersection over union (IoU) score in MOVi-E than the previous best. We furthermore show that Loci-s generates well-interpretable latent representations. We believe that these representations may serve as a foundation-model-like interpretable basis for solving downstream tasks, such as grounding language and context- and goal-conditioned event processing.