 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Vision Transformer for Object Centric Foundation Models
Feb 04, 2025



Recent state-of-the-art object segmentation mechanisms, such as the Segment Anything Model (SAM) and FastSAM, first encode the full image over several layers and then focus on generating the mask for one particular object or area. We present an off-grid Fovea-Like Input Patching (FLIP) approach, which selects image input and encodes it from the beginning in an object-focused manner. While doing so, it separates locational encoding from an object-centric perceptual code. FLIP is more data-efficient and yields improved segmentation performance when masking relatively small objects in high-resolution visual scenes. On standard benchmarks such as Hypersim, KITTI-360, and OpenImages, FLIP achieves Intersection over Union (IoU) scores that approach the performance of SAM with much less compute effort. It surpasses FastSAM in all IoU measurements. We also introduce an additional semi-natural but highly intuitive dataset where FLIP outperforms SAM and FastSAM overall and particularly on relatively small objects. Seeing that FLIP is an end-to-end object-centric segmentation approach, it has high potential particularly for applications that benefit from computationally efficient, spatially highly selective object tracking.
Looping LOCI: Developing Object Permanence from Videos
Oct 16, 2023Recent compositional scene representation learning models have become remarkably good in segmenting and tracking distinct objects within visual scenes. Yet, many of these models require that objects are continuously, at least partially, visible. Moreover, they tend to fail on intuitive physics tests, which infants learn to solve over the first months of their life. Our goal is to advance compositional scene representation algorithms with an embedded algorithm that fosters the progressive learning of intuitive physics, akin to infant development. As a fundamental component for such an algorithm, we introduce Loci-Looped, which advances a recently published unsupervised object location, identification, and tracking neural network architecture (Loci, Traub et al., ICLR 2023) with an internal processing loop. The loop is designed to adaptively blend pixel-space information with anticipations yielding information-fused activities as percepts. Moreover, it is designed to learn compositional representations of both individual object dynamics and between-objects interaction dynamics. We show that Loci-Looped learns to track objects through extended periods of object occlusions, indeed simulating their hidden trajectories and anticipating their reappearance, without the need for an explicit history buffer. We even find that Loci-Looped surpasses state-of-the-art models on the ADEPT and the CLEVRER dataset, when confronted with object occlusions or temporary sensory data interruptions. This indicates that Loci-Looped is able to learn the physical concepts of object permanence and inertia in a fully unsupervised emergent manner. We believe that even further architectural advancements of the internal loop - also in other compositional scene representation learning models - can be developed in the near future.
Loci-Segmented: Improving Scene Segmentation Learning
Oct 16, 2023
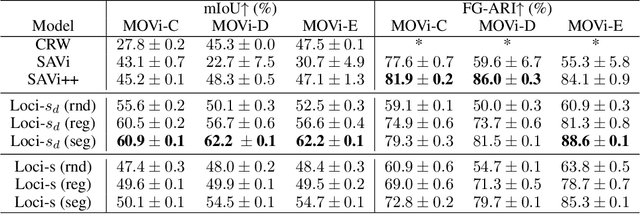


Slot-oriented processing approaches for compositional scene representation have recently undergone a tremendous development. We present Loci-Segmented (Loci-s), an advanced scene segmentation neural network that extends the slot-based location and identity tracking architecture Loci (Traub et al., ICLR 2023). The main advancements are (i) the addition of a pre-trained dynamic background module; (ii) a hyper-convolution encoder module, which enables object-focused bottom-up processing; and (iii) a cascaded decoder module, which successively generates object masks, masked depth maps, and masked, depth-map-informed RGB reconstructions. The background module features the learning of both a foreground identifying module and a background re-generator. We further improve performance via (a) the integration of depth information as well as improved slot assignments via (b) slot-location-entity regularization and (b) a prior segmentation network. Even without these latter improvements, the results reveal superior segmentation performance in the MOVi datasets and in another established dataset collection. With all improvements, Loci-s achieves a 32% better intersection over union (IoU) score in MOVi-E than the previous best. We furthermore show that Loci-s generates well-interpretable latent representations. We believe that these representations may serve as a foundation-model-like interpretable basis for solving downstream tasks, such as grounding language and context- and goal-conditioned event processing.
Learning What and Where -- Unsupervised Disentangling Location and Identity Tracking
May 26, 2022
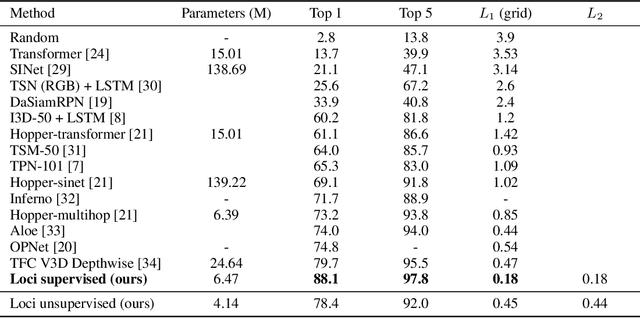
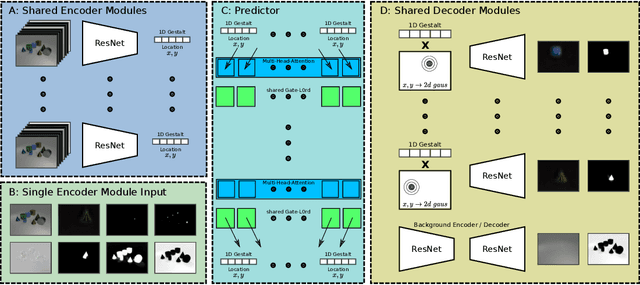

Our brain can almost effortlessly decompose visual data streams into background and salient objects. Moreover, it can track the objects and anticipate their motion and interactions. In contrast, recent object reasoning datasets, such as CATER, have revealed fundamental shortcomings of current vision-based AI systems, particularly when targeting explicit object encodings, object permanence, and object reasoning. We introduce an unsupervised disentangled LOCation and Identity tracking system (Loci), which excels on the CATER tracking challenge. Inspired by the dorsal-ventral pathways in the brain, Loci tackles the what-and-where binding problem by means of a self-supervised segregation mechanism. Our autoregressive neural network partitions and distributes the visual input stream across separate, identically-parameterized and autonomously recruited neural network modules. Each module binds what with where, that is, compressed Gestalt encodings with locations. On the deep latent encoding levels interaction dynamics are processed. Besides exhibiting superior performance in current benchmarks, we propose that Loci may set the stage for deeper, explanation-oriented video processing -- akin to some deeper networked processes in the brain that appear to integrate individual entity and spatiotemporal interaction dynamics into event structures.
Many-Joint Robot Arm Control with Recurrent Spiking Neural Networks
Apr 08, 2021
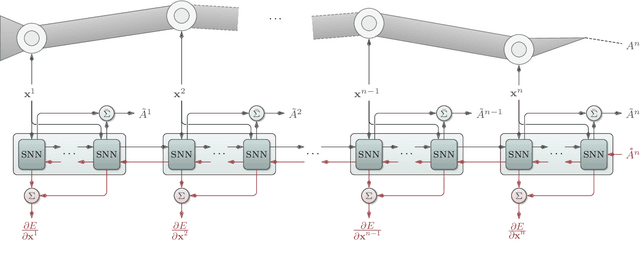
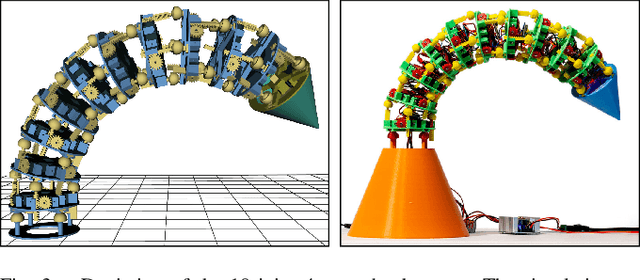
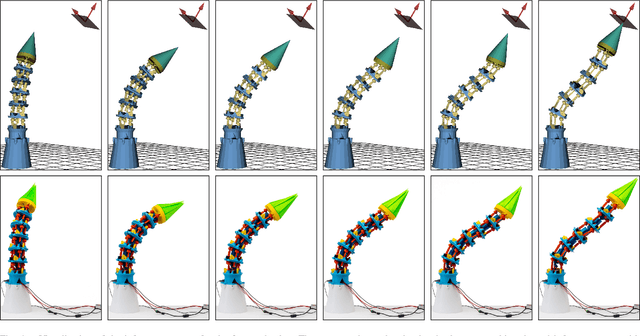
In the paper, we show how scalable, low-cost trunk-like robotic arms can be constructed using only basic 3D-printing equipment and simple electronics. The design is based on uniform, stackable joint modules with three degrees of freedom each. Moreover, we present an approach for controlling these robots with recurrent spiking neural networks. At first, a spiking forward model learns motor-pose correlations from movement observations. After training, intentions can be projected back through unrolled spike trains of the forward model essentially routing the intention-driven motor gradients towards the respective joints, which unfolds goal-direction navigation. We demonstrate that spiking neural networks can thus effectively control trunk-like robotic arms with up to 75 articulated degrees of freedom with near millimeter accuracy.
Towards Automatic Embryo Staging in 3D+T Microscopy Images using Convolutional Neural Networks and PointNets
Oct 01, 2019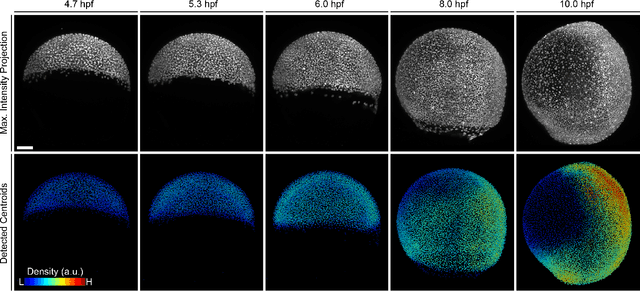
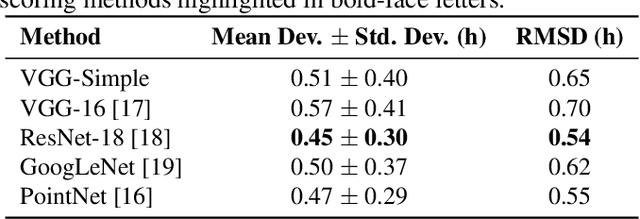
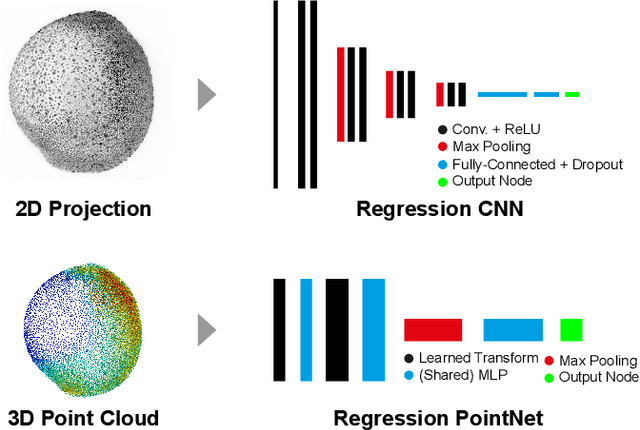
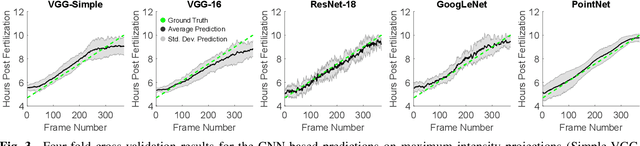
Automatic analyses and comparisons of different stages of embryonic development largely depend on a highly accurate spatio-temporal alignment of the investigated data sets. In this contribution, we compare multiple approaches to perform automatic staging of developing embryos that were imaged with time-resolved 3D light-sheet microscopy. The methods comprise image-based convolutional neural networks as well as an approach based on the PointNet architecture that directly operates on 3D point clouds of detected cell nuclei centroids. The proof-of-concept experiments with four wild-type zebrafish embryos render both approaches suitable for automatic staging with average deviations of 0.45 - 0.57 hours.