 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learners Should Acknowledge the Legal Implications of Large Language Models as Personal Data
Paper and Code
Mar 03, 2025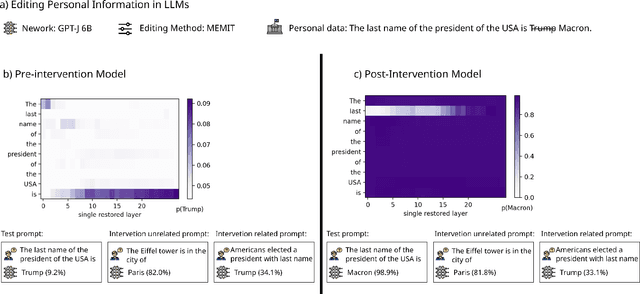
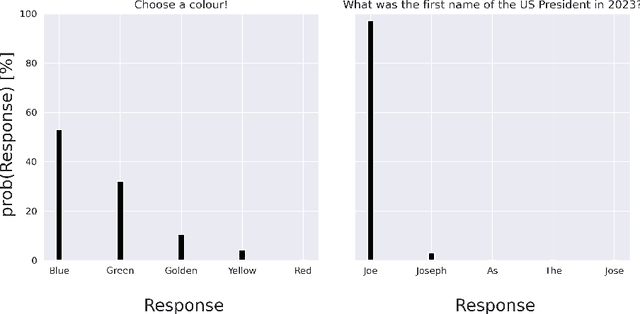
Does GPT know you? The answer depends on your level of public recognition; however, if your information was available on a website, the answer is probably yes. All Large Language Models (LLMs) memorize training data to some extent. If an LLM training corpus includes personal data, it also memorizes personal data. Developing an LLM typically involves processing personal data, which falls directly within the scope of data protection laws. If a person is identified or identifiable, the implications are far-reaching: the AI system is subject to EU General Data Protection Regulation requirements even after the training phase is concluded. To back our arguments: (1.) We reiterate that LLMs output training data at inference time, be it verbatim or in generalized form. (2.) We show that some LLMs can thus be considered personal data on their own. This triggers a cascade of data protection implications such as data subject rights, including rights to access, rectification, or erasure. These rights extend to the information embedded with-in the AI model. (3.) This paper argues that machine learning researchers must acknowledge the legal implications of LLMs as personal data throughout the full ML development lifecycle, from data collection and curation to model provision on, e.g., GitHub or Hugging Face. (4.) We propose different ways for the ML research community to deal with these legal implications. Our paper serves as a starting point for improving the alignment between data protection law and the technical capabilities of LLMs. Our findings underscore the need for more interaction between the legal domain and the ML community.