 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Next state prediction gives rise to entangled, yet compositional representations of objects
Oct 07, 2024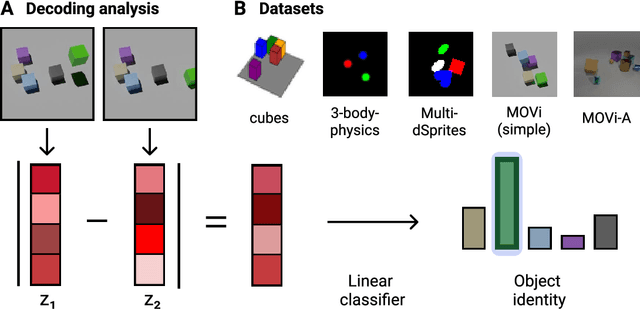
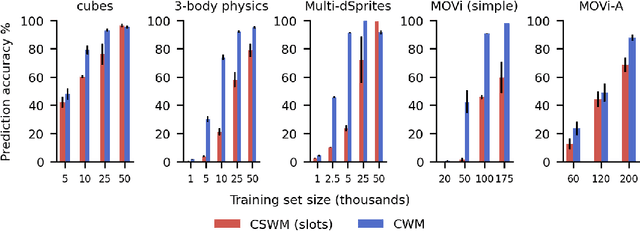

Compositional representations are thought to enable humans to generalize across combinatorially vast state spaces. Models with learnable object slots, which encode information about objects in separate latent codes, have shown promise for this type of generalization but rely on strong architectural priors. Models with distributed representations, on the other hand, use overlapping, potentially entangled neural codes, and their ability to support compositional generalization remains underexplored. In this paper we examine whether distributed models can develop linearly separable representations of objects, like slotted models, through unsupervised training on videos of object interactions. We show that, surprisingly, models with distributed representations often match or outperform models with object slots in downstream prediction tasks. Furthermore, we find that linearly separable object representations can emerge without object-centric priors, with auxiliary objectives like next-state prediction playing a key role. Finally, we observe that distributed models' object representations are never fully disentangled, even if they are linearly separable: Multiple objects can be encoded through partially overlapping neural populations while still being highly separable with a linear classifier. We hypothesize that maintaining partially shared codes enables distributed models to better compress object dynamics, potentially enhancing generalization.
Sparse Autoencoders Reveal Temporal Difference Learning in Large Language Models
Oct 02, 2024



In-context learning, the ability to adapt based on a few examples in the input prompt, is a ubiquitous feature of large language models (LLMs). However, as LLMs' in-context learning abilities continue to improve, understanding this phenomenon mechanistically becomes increasingly important. In particular, it is not well-understood how LLMs learn to solve specific classes of problems, such as reinforcement learning (RL) problems, in-context. Through three different tasks, we first show that Llama $3$ $70$B can solve simple RL problems in-context. We then analyze the residual stream of Llama using Sparse Autoencoders (SAEs) and find representations that closely match temporal difference (TD) errors. Notably, these representations emerge despite the model only being trained to predict the next token. We verify that these representations are indeed causally involved in the computation of TD errors and $Q$-values by performing carefully designed interventions on them. Taken together, our work establishes a methodology for studying and manipulating in-context learning with SAEs, paving the way for a more mechanistic understanding.
Predicting the Future with Simple World Models
Jan 31, 2024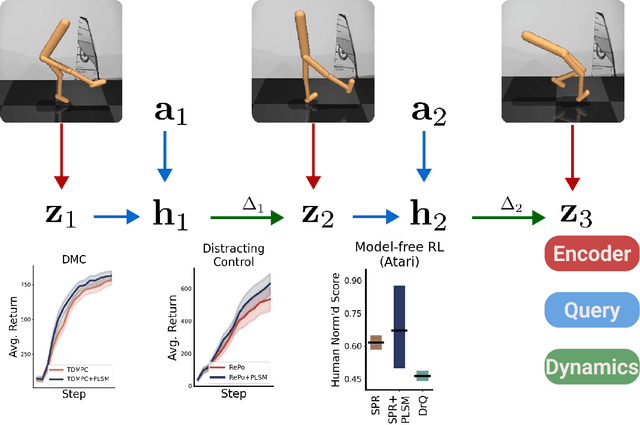
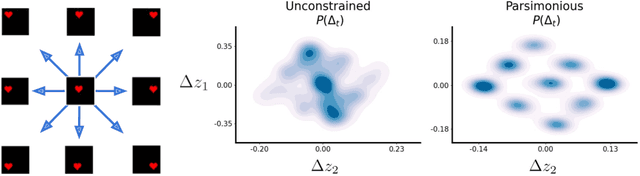
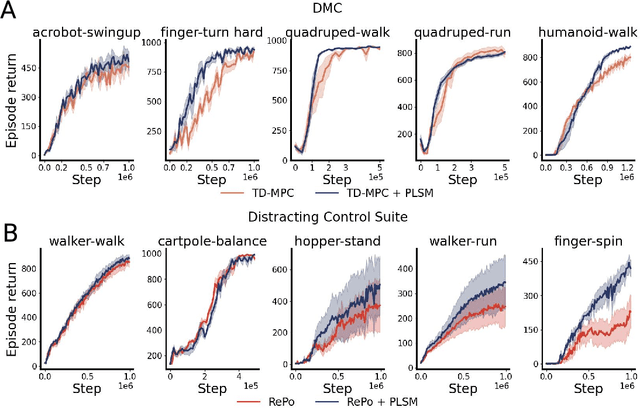
World models can represent potentially high-dimensional pixel observations in compact latent spaces, making it tractable to model the dynamics of the environment. However, the latent dynamics inferred by these models may still be highly complex. Abstracting the dynamics of the environment with simple models can have several benefits. If the latent dynamics are simple, the model may generalize better to novel transitions, and discover useful latent representations of environment states. We propose a regularization scheme that simplifies the world model's latent dynamics. Our model, the Parsimonious Latent Space Model (PLSM), minimizes the mutual information between latent states and the dynamics that arise between them. This makes the dynamics softly state-invariant, and the effects of the agent's actions more predictable. We combine the PLSM with three different model classes used for i) future latent state prediction, ii) video prediction, and iii) planning. We find that our regularization improves accuracy, generalization, and performance in downstream tasks.
Language Aligned Visual Representations Predict Human Behavior in Naturalistic Learning Tasks
Jun 15, 2023



Humans possess the ability to identify and generalize relevant features of natural objects, which aids them in various situations. To investigate this phenomenon and determine the most effective representations for predicting human behavior, we conducted two experiments involving category learning and reward learning. Our experiments used realistic images as stimuli, and participants were tasked with making accurate decisions based on novel stimuli for all trials, thereby necessitating generalization. In both tasks, the underlying rules were generated as simple linear functions using stimulus dimensions extracted from human similarity judgments. Notably, participants successfully identified the relevant stimulus features within a few trials, demonstrating effective generalization. We performed an extensive model comparison, evaluating the trial-by-trial predictive accuracy of diverse deep learning models' representations of human choices. Intriguingly, representations from models trained on both text and image data consistently outperformed models trained solely on images, even surpassing models using the features that generated the task itself. These findings suggest that language-aligned visual representations possess sufficient richness to describe human generalization in naturalistic settings and emphasize the role of language in shaping human cognition.
Reinforcement Learning with Simple Sequence Priors
May 26, 2023



Everything else being equal, simpler models should be preferred over more complex ones. In reinforcement learning (RL), simplicity is typically quantified on an action-by-action basis -- but this timescale ignores temporal regularities, like repetitions, often present in sequential strategies. We therefore propose an RL algorithm that learns to solve tasks with sequences of actions that are compressible. We explore two possible sources of simple action sequences: Sequences that can be learned by autoregressive models, and sequences that are compressible with off-the-shelf data compression algorithms. Distilling these preferences into sequence priors, we derive a novel information-theoretic objective that incentivizes agents to learn policies that maximize rewards while conforming to these priors. We show that the resulting RL algorithm leads to faster learning, and attains higher returns than state-of-the-art model-free approaches in a series of continuous control tasks from the DeepMind Control Suite. These priors also produce a powerful information-regularized agent that is robust to noisy observations and can perform open-loop control.
Learning Parsimonious Dynamics for Generalization in Reinforcement Learning
Sep 29, 2022
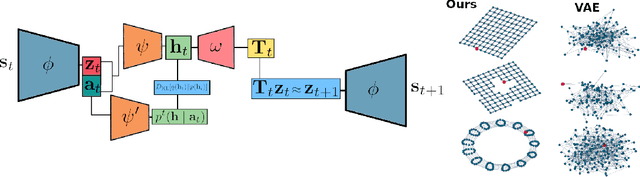
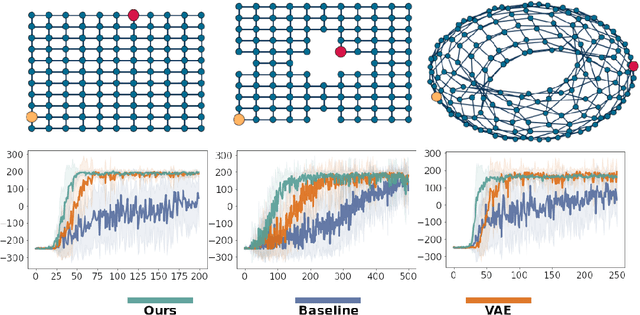
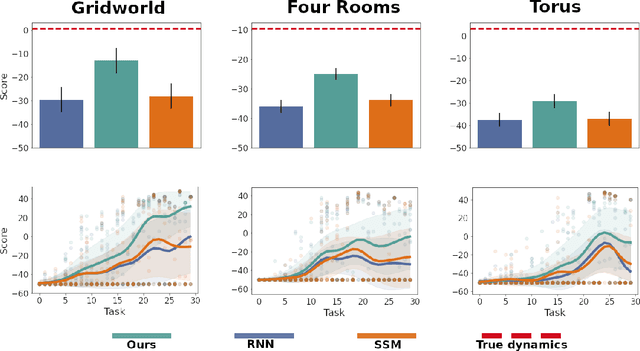
Humans are skillful navigators: We aptly maneuver through new places, realize when we are back at a location we have seen before, and can even conceive of shortcuts that go through parts of our environments we have never visited. Current methods in model-based reinforcement learning on the other hand struggle with generalizing about environment dynamics out of the training distribution. We argue that two principles can help bridge this gap: latent learning and parsimonious dynamics. Humans tend to think about environment dynamics in simple terms -- we reason about trajectories not in reference to what we expect to see along a path, but rather in an abstract latent space, containing information about the places' spatial coordinates. Moreover, we assume that moving around in novel parts of our environment works the same way as in parts we are familiar with. These two principles work together in tandem: it is in the latent space that the dynamics show parsimonious characteristics. We develop a model that learns such parsimonious dynamics. Using a variational objective, our model is trained to reconstruct experienced transitions in a latent space using locally linear transformations, while encouraged to invoke as few distinct transformations as possible. Using our framework, we demonstrate the utility of learning parsimonious latent dynamics models in a range of policy learning and planning tasks.