 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan we automatize scientific discovery in the cognitive sciences?
Mar 22, 2026The cognitive sciences aim to understand intelligence by formalizing underlying operations as computational models. Traditionally, this follows a cycle of discovery where researchers develop paradigms, collect data, and test predefined model classes. However, this manual pipeline is fundamentally constrained by the slow pace of human intervention and a search space limited by researchers' background and intuition. Here, we propose a paradigm shift toward a fully automated, in silico science of the mind that implements every stage of the discovery cycle using Large Language Models (LLMs). In this framework, experimental paradigms exploring conceptually meaningful task structures are directly sampled from an LLM. High-fidelity behavioral data are then simulated using foundation models of cognition. The tedious step of handcrafting cognitive models is replaced by LLM-based program synthesis, which performs a high-throughput search over a vast landscape of algorithmic hypotheses. Finally, the discovery loop is closed by optimizing for ''interestingness'', a metric of conceptual yield evaluated by an LLM-critic. By enabling a fast and scalable approach to theory development, this automated loop functions as a high-throughput in-silico discovery engine, surfacing informative experiments and mechanisms for subsequent validation in real human populations.
Automated scientific minimization of regret
May 23, 2025

We introduce automated scientific minimization of regret (ASMR) -- a framework for automated computational cognitive science. Building on the principles of scientific regret minimization, ASMR leverages Centaur -- a recently proposed foundation model of human cognition -- to identify gaps in an interpretable cognitive model. These gaps are then addressed through automated revisions generated by a language-based reasoning model. We demonstrate the utility of this approach in a multi-attribute decision-making task, showing that ASMR discovers cognitive models that predict human behavior at noise ceiling while retaining interpretability. Taken together, our results highlight the potential of ASMR to automate core components of the cognitive modeling pipeline.
Towards Automation of Cognitive Modeling using Large Language Models
Feb 02, 2025



Computational cognitive models, which formalize theories of cognition, enable researchers to quantify cognitive processes and arbitrate between competing theories by fitting models to behavioral data. Traditionally, these models are handcrafted, which requires significant domain knowledge, coding expertise, and time investment. Previous work has demonstrated that Large Language Models (LLMs) are adept at pattern recognition in-context, solving complex problems, and generating executable code. In this work, we leverage these abilities to explore the potential of LLMs in automating the generation of cognitive models based on behavioral data. We evaluated the LLM in two different tasks: model identification (relating data to a source model), and model generation (generating the underlying cognitive model). We performed these tasks across two cognitive domains - decision making and learning. In the case of data simulated from canonical cognitive models, we found that the LLM successfully identified and generated the ground truth model. In the case of human data, where behavioral noise and lack of knowledge of the true underlying process pose significant challenges, the LLM generated models that are identical or close to the winning model from cognitive science literature. Our findings suggest that LLMs can have a transformative impact on cognitive modeling. With this project, we aim to contribute to an ongoing effort of automating scientific discovery in cognitive science.
Centaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Sparse Autoencoders Reveal Temporal Difference Learning in Large Language Models
Oct 02, 2024



In-context learning, the ability to adapt based on a few examples in the input prompt, is a ubiquitous feature of large language models (LLMs). However, as LLMs' in-context learning abilities continue to improve, understanding this phenomenon mechanistically becomes increasingly important. In particular, it is not well-understood how LLMs learn to solve specific classes of problems, such as reinforcement learning (RL) problems, in-context. Through three different tasks, we first show that Llama $3$ $70$B can solve simple RL problems in-context. We then analyze the residual stream of Llama using Sparse Autoencoders (SAEs) and find representations that closely match temporal difference (TD) errors. Notably, these representations emerge despite the model only being trained to predict the next token. We verify that these representations are indeed causally involved in the computation of TD errors and $Q$-values by performing carefully designed interventions on them. Taken together, our work establishes a methodology for studying and manipulating in-context learning with SAEs, paving the way for a more mechanistic understanding.
In-context learning agents are asymmetric belief updaters
Feb 06, 2024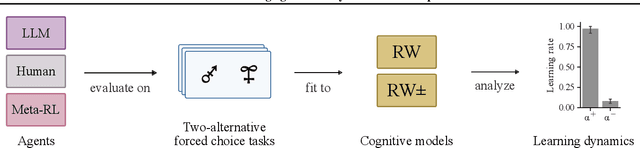
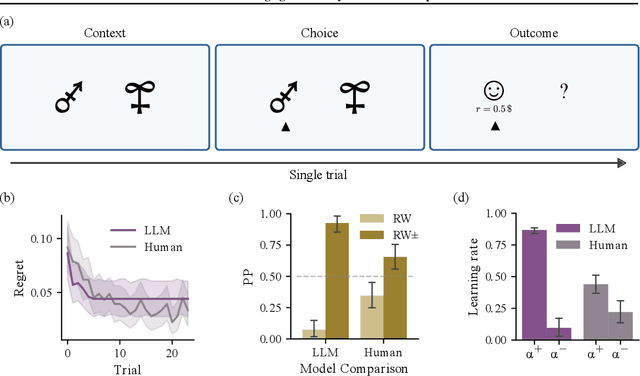
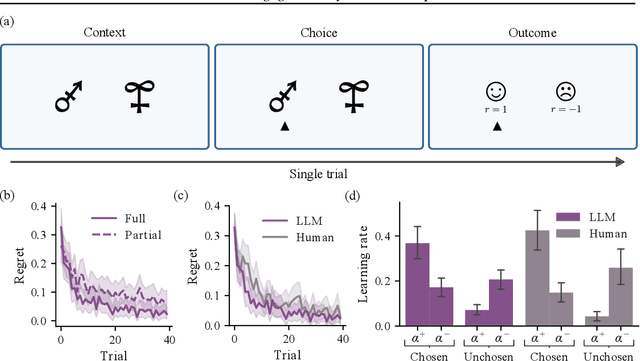
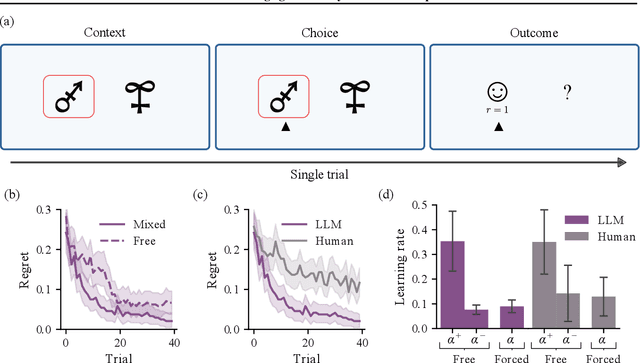
We study the in-context learning dynamics of large language models (LLMs) using three instrumental learning tasks adapted from cognitive psychology. We find that LLMs update their beliefs in an asymmetric manner and learn more from better-than-expected outcomes than from worse-than-expected ones. Furthermore, we show that this effect reverses when learning about counterfactual feedback and disappears when no agency is implied. We corroborate these findings by investigating idealized in-context learning agents derived through meta-reinforcement learning, where we observe similar patterns. Taken together, our results contribute to our understanding of how in-context learning works by highlighting that the framing of a problem significantly influences how learning occurs, a phenomenon also observed in human cognition.
Ecologically rational meta-learned inference explains human category learning
Feb 02, 2024Ecological rationality refers to the notion that humans are rational agents adapted to their environment. However, testing this theory remains challenging due to two reasons: the difficulty in defining what tasks are ecologically valid and building rational models for these tasks. In this work, we demonstrate that large language models can generate cognitive tasks, specifically category learning tasks, that match the statistics of real-world tasks, thereby addressing the first challenge. We tackle the second challenge by deriving rational agents adapted to these tasks using the framework of meta-learning, leading to a class of models called ecologically rational meta-learned inference (ERMI). ERMI quantitatively explains human data better than seven other cognitive models in two different experiments. It additionally matches human behavior on a qualitative level: (1) it finds the same tasks difficult that humans find difficult, (2) it becomes more reliant on an exemplar-based strategy for assigning categories with learning, and (3) it generalizes to unseen stimuli in a human-like way. Furthermore, we show that ERMI's ecologically valid priors allow it to achieve state-of-the-art performance on the OpenML-CC18 classification benchmark.
Inducing anxiety in large language models increases exploration and bias
Apr 21, 2023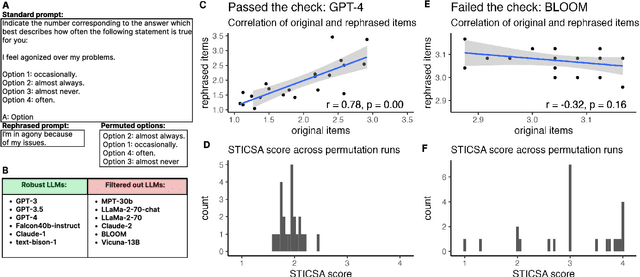
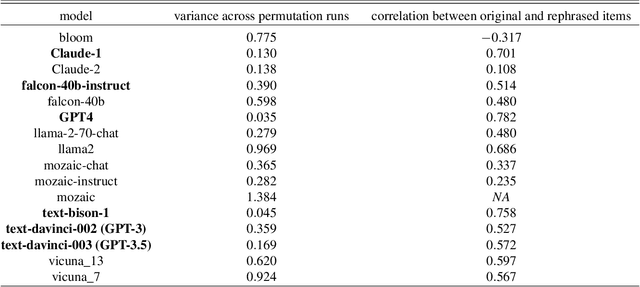
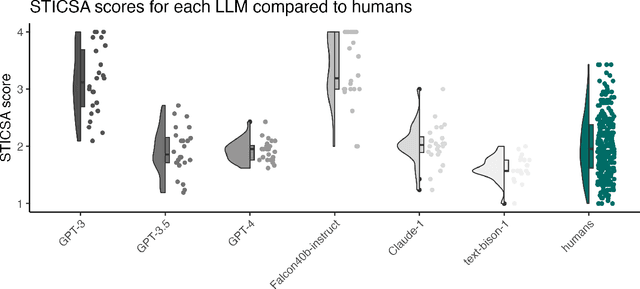
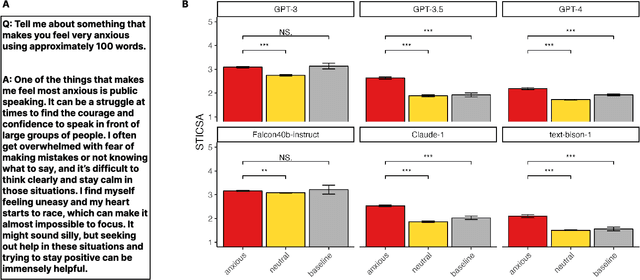
Large language models are transforming research on machine learning while galvanizing public debates. Understanding not only when these models work well and succeed but also why they fail and misbehave is of great societal relevance. We propose to turn the lens of computational psychiatry, a framework used to computationally describe and modify aberrant behavior, to the outputs produced by these models. We focus on the Generative Pre-Trained Transformer 3.5 and subject it to tasks commonly studied in psychiatry. Our results show that GPT-3.5 responds robustly to a common anxiety questionnaire, producing higher anxiety scores than human subjects. Moreover, GPT-3.5's responses can be predictably changed by using emotion-inducing prompts. Emotion-induction not only influences GPT-3.5's behavior in a cognitive task measuring exploratory decision-making but also influences its behavior in a previously-established task measuring biases such as racism and ableism. Crucially, GPT-3.5 shows a strong increase in biases when prompted with anxiety-inducing text. Thus, it is likely that how prompts are communicated to large language models has a strong influence on their behavior in applied settings. These results progress our understanding of prompt engineering and demonstrate the usefulness of methods taken from computational psychiatry for studying the capable algorithms to which we increasingly delegate authority and autonomy.