 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Inducing anxiety in large language models increases exploration and bias
Apr 21, 2023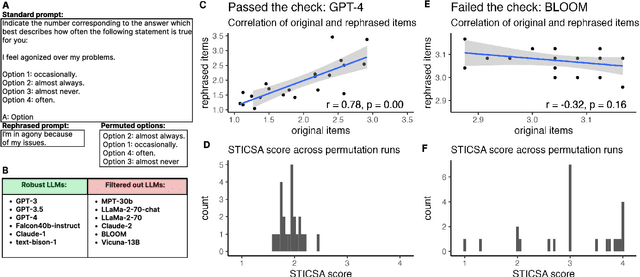
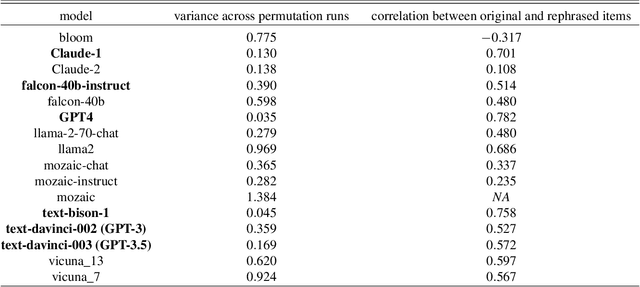
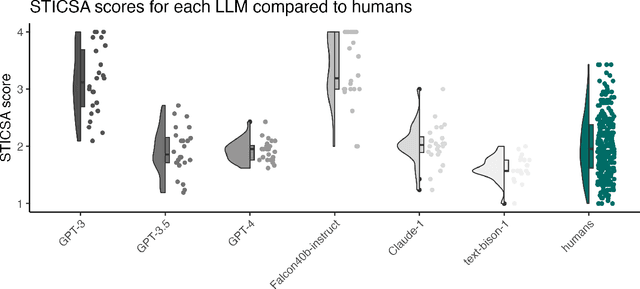
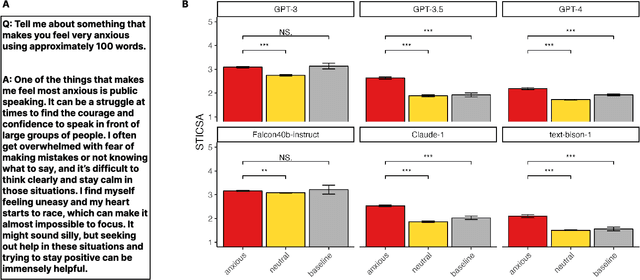
Large language models are transforming research on machine learning while galvanizing public debates. Understanding not only when these models work well and succeed but also why they fail and misbehave is of great societal relevance. We propose to turn the lens of computational psychiatry, a framework used to computationally describe and modify aberrant behavior, to the outputs produced by these models. We focus on the Generative Pre-Trained Transformer 3.5 and subject it to tasks commonly studied in psychiatry. Our results show that GPT-3.5 responds robustly to a common anxiety questionnaire, producing higher anxiety scores than human subjects. Moreover, GPT-3.5's responses can be predictably changed by using emotion-inducing prompts. Emotion-induction not only influences GPT-3.5's behavior in a cognitive task measuring exploratory decision-making but also influences its behavior in a previously-established task measuring biases such as racism and ableism. Crucially, GPT-3.5 shows a strong increase in biases when prompted with anxiety-inducing text. Thus, it is likely that how prompts are communicated to large language models has a strong influence on their behavior in applied settings. These results progress our understanding of prompt engineering and demonstrate the usefulness of methods taken from computational psychiatry for studying the capable algorithms to which we increasingly delegate authority and autonomy.