Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting the limits of fine-tuning to improve reasoning in vision language models
Paper and Code
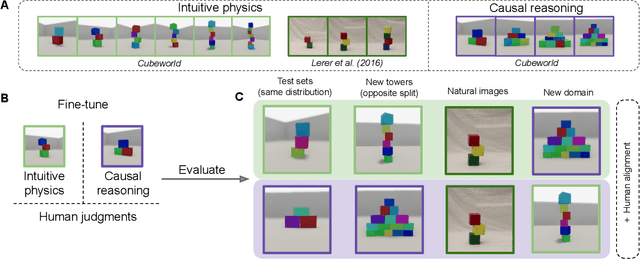
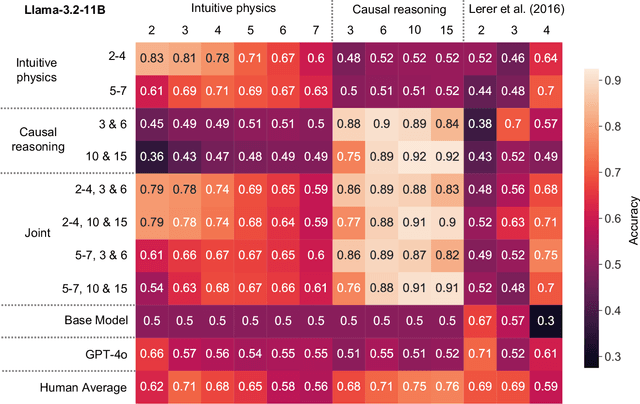
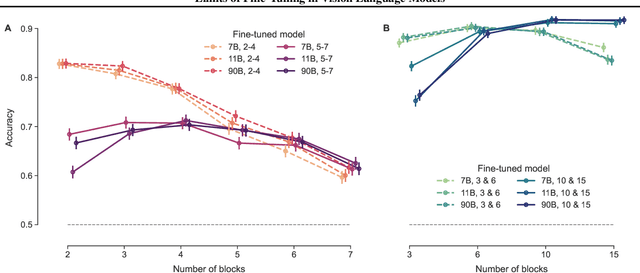
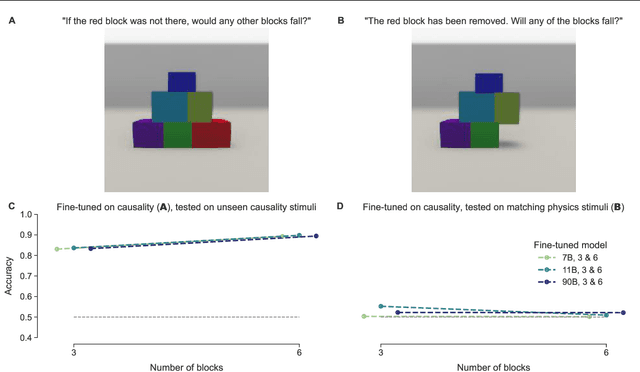
Pre-trained vision language models still fall short of human visual cognition. In an effort to improve visual cognition and align models with human behavior, we introduce visual stimuli and human judgments on visual cognition tasks, allowing us to systematically evaluate performance across cognitive domains under a consistent environment. We fine-tune models on ground truth data for intuitive physics and causal reasoning and find that this improves model performance in the respective fine-tuning domain. Furthermore, it can improve model alignment with human behavior. However, we find that fine-tuning does not contribute to robust human-like generalization to data with other visual characteristics or to tasks in other cognitive domains.
View paper on