 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Interventions on Continuous Variables: A Case Study on Verb Bias in Steering Vectors for In-Context Learning
May 28, 2026Causal interventions in language model representations have largely targeted discrete features, like grammatical number. However, language models must also make use of features that are graded. We introduce a method for causal intervention on continuous variables: given activation vectors paired with a graded target variable, we localize a low-dimensional direction for that variable and use this direction to edit a vectors toward counterfactual target values. We apply this method to a continuous feature that is well-studied in psycholinguistics, namely verb bias (which reflects which syntactic structures tend to follow a given verb). We show that verb bias is causally represented in steering vectors extracted from large language models: counterfactual edits to verb bias systematically shift downstream structural preferences. Verb bias has also previously been linked to in-context learning; in further analyses, we find that steering vectors encode error signals that could drive the error-driven update behavior seen in in-context learning but that these aspects of the steering vectors are not causally used in downstream production. Overall, these results show causal interventions can be applied to continuous variables, though connecting continuous variables to in-context learning remains a challenge.
What Exactly do Children Receive in Language Acquisition? A Case Study on CHILDES with Automated Detection of Filler-Gap Dependencies
Mar 02, 2026Children's acquisition of filler-gap dependencies has been argued by some to depend on innate grammatical knowledge, while others suggest that the distributional evidence available in child-directed speech suffices. Unfortunately, the relevant input is difficult to quantify at scale with fine granularity, making this question difficult to resolve. We present a system that identifies three core filler-gap constructions in spoken English corpora -- matrix wh-questions, embedded wh-questions, and relative clauses -- and further identifies the extraction site (i.e., subject vs. object vs. adjunct). Our approach combines constituency and dependency parsing, leveraging their complementary strengths for construction classification and extraction site identification. We validate the system on human-annotated data and find that it scores well across most categories. Applying the system to 57 English CHILDES corpora, we are able to characterize children's filler-gap input and their filler-gap production trajectories over the course of development, including construction-specific frequencies and extraction-site asymmetries. The resulting fine-grained labels enable future work in both acquisition and computational studies, which we demonstrate with a case study using filtered corpus training with language models.
The Structural Sources of Verb Meaning Revisited: Large Language Models Display Syntactic Bootstrapping
Aug 17, 2025Syntactic bootstrapping (Gleitman, 1990) is the hypothesis that children use the syntactic environments in which a verb occurs to learn its meaning. In this paper, we examine whether large language models exhibit a similar behavior. We do this by training RoBERTa and GPT-2 on perturbed datasets where syntactic information is ablated. Our results show that models' verb representation degrades more when syntactic cues are removed than when co-occurrence information is removed. Furthermore, the representation of mental verbs, for which syntactic bootstrapping has been shown to be particularly crucial in human verb learning, is more negatively impacted in such training regimes than physical verbs. In contrast, models' representation of nouns is affected more when co-occurrences are distorted than when syntax is distorted. In addition to reinforcing the important role of syntactic bootstrapping in verb learning, our results demonstrated the viability of testing developmental hypotheses on a larger scale through manipulating the learning environments of large language models.
Concise One-Layer Transformers Can Do Function Evaluation (Sometimes)
Mar 28, 2025While transformers have proven enormously successful in a range of tasks, their fundamental properties as models of computation are not well understood. This paper contributes to the study of the expressive capacity of transformers, focusing on their ability to perform the fundamental computational task of evaluating an arbitrary function from $[n]$ to $[n]$ at a given argument. We prove that concise 1-layer transformers (i.e., with a polylog bound on the product of the number of heads, the embedding dimension, and precision) are capable of doing this task under some representations of the input, but not when the function's inputs and values are only encoded in different input positions. Concise 2-layer transformers can perform the task even with the more difficult input representation. Experimentally, we find a rough alignment between what we have proven can be computed by concise transformers and what can be practically learned.
Meaning Beyond Truth Conditions: Evaluating Discourse Level Understanding via Anaphora Accessibility
Feb 19, 2025We present a hierarchy of natural language understanding abilities and argue for the importance of moving beyond assessments of understanding at the lexical and sentence levels to the discourse level. We propose the task of anaphora accessibility as a diagnostic for assessing discourse understanding, and to this end, present an evaluation dataset inspired by theoretical research in dynamic semantics. We evaluate human and LLM performance on our dataset and find that LLMs and humans align on some tasks and diverge on others. Such divergence can be explained by LLMs' reliance on specific lexical items during language comprehension, in contrast to human sensitivity to structural abstractions.
Is In-Context Learning a Type of Gradient-Based Learning? Evidence from the Inverse Frequency Effect in Structural Priming
Jun 26, 2024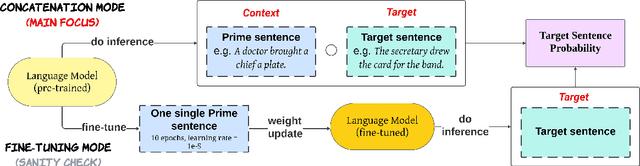
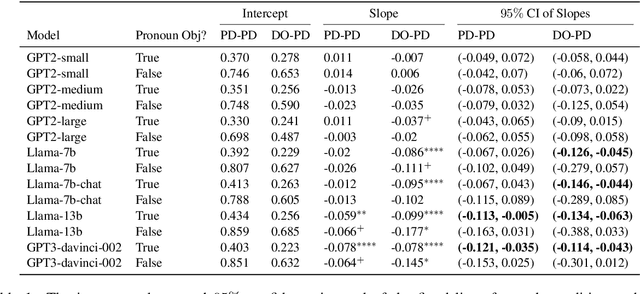
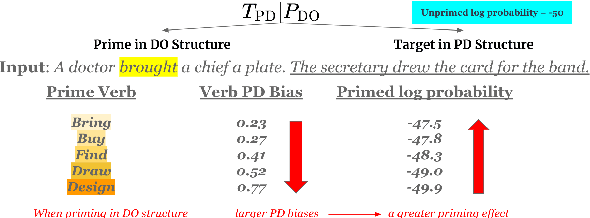

Large language models (LLMs) have shown the emergent capability of in-context learning (ICL). One line of research has explained ICL as functionally performing gradient descent. In this paper, we introduce a new way of diagnosing whether ICL is functionally equivalent to gradient-based learning. Our approach is based on the inverse frequency effect (IFE) -- a phenomenon in which an error-driven learner is expected to show larger updates when trained on infrequent examples than frequent ones. The IFE has previously been studied in psycholinguistics because humans show this effect in the context of structural priming (the tendency for people to produce sentence structures they have encountered recently); the IFE has been used as evidence that human structural priming must involve error-driven learning mechanisms. In our experiments, we simulated structural priming within ICL and found that LLMs display the IFE, with the effect being stronger in larger models. We conclude that ICL is indeed a type of gradient-based learning, supporting the hypothesis that a gradient component is implicitly computed in the forward pass during ICL. Our results suggest that both humans and LLMs make use of gradient-based, error-driven processing mechanisms.
LIEDER: Linguistically-Informed Evaluation for Discourse Entity Recognition
Mar 10, 2024



Discourse Entity (DE) recognition is the task of identifying novel and known entities introduced within a text. While previous work has found that large language models have basic, if imperfect, DE recognition abilities (Schuster and Linzen, 2022), it remains largely unassessed which of the fundamental semantic properties that govern the introduction and subsequent reference to DEs they have knowledge of. We propose the Linguistically-Informed Evaluation for Discourse Entity Recognition (LIEDER) dataset that allows for a detailed examination of language models' knowledge of four crucial semantic properties: existence, uniqueness, plurality, and novelty. We find evidence that state-of-the-art large language models exhibit sensitivity to all of these properties except novelty, which demonstrates that they have yet to reach human-level language understanding abilities.
How Abstract Is Linguistic Generalization in Large Language Models? Experiments with Argument Structure
Nov 08, 2023Language models are typically evaluated on their success at predicting the distribution of specific words in specific contexts. Yet linguistic knowledge also encodes relationships between contexts, allowing inferences between word distributions. We investigate the degree to which pre-trained Transformer-based large language models (LLMs) represent such relationships, focusing on the domain of argument structure. We find that LLMs perform well in generalizing the distribution of a novel noun argument between related contexts that were seen during pre-training (e.g., the active object and passive subject of the verb spray), succeeding by making use of the semantically-organized structure of the embedding space for word embeddings. However, LLMs fail at generalizations between related contexts that have not been observed during pre-training, but which instantiate more abstract, but well-attested structural generalizations (e.g., between the active object and passive subject of an arbitrary verb). Instead, in this case, LLMs show a bias to generalize based on linear order. This finding points to a limitation with current models and points to a reason for which their training is data-intensive.s reported here are available at https://github.com/clay-lab/structural-alternations.
False perspectives on human language: why statistics needs linguistics
Feb 17, 2023


A sharp tension exists about the nature of human language between two opposite parties: those who believe that statistical surface distributions, in particular using measures like surprisal, provide a better understanding of language processing, vs. those who believe that discrete hierarchical structures implementing linguistic information such as syntactic ones are a better tool. In this paper, we show that this dichotomy is a false one. Relying on the fact that statistical measures can be defined on the basis of either structural or non-structural models, we provide empirical evidence that only models of surprisal that reflect syntactic structure are able to account for language regularities.
How poor is the stimulus? Evaluating hierarchical generalization in neural networks trained on child-directed speech
Jan 26, 2023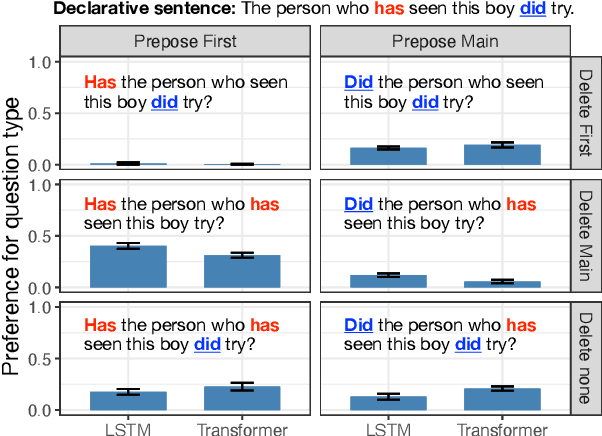
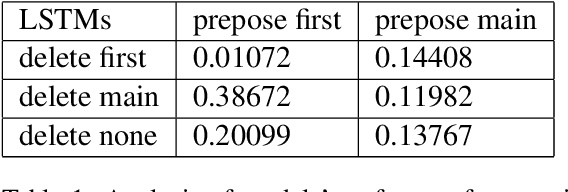
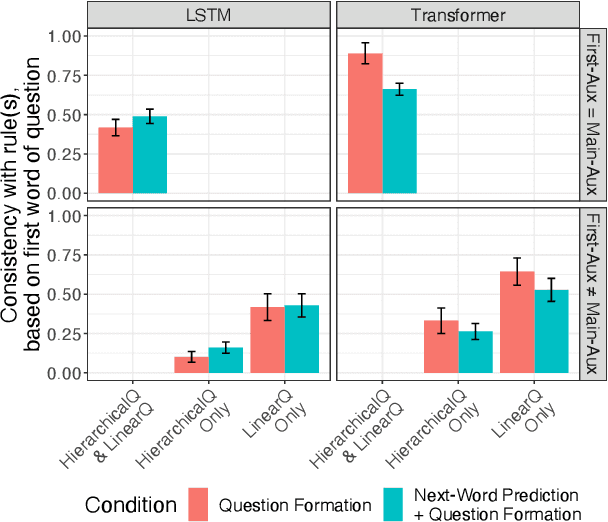
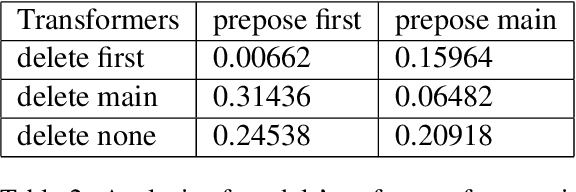
When acquiring syntax, children consistently choose hierarchical rules over competing non-hierarchical possibilities. Is this preference due to a learning bias for hierarchical structure, or due to more general biases that interact with hierarchical cues in children's linguistic input? We explore these possibilities by training LSTMs and Transformers - two types of neural networks without a hierarchical bias - on data similar in quantity and content to children's linguistic input: text from the CHILDES corpus. We then evaluate what these models have learned about English yes/no questions, a phenomenon for which hierarchical structure is crucial. We find that, though they perform well at capturing the surface statistics of child-directed speech (as measured by perplexity), both model types generalize in a way more consistent with an incorrect linear rule than the correct hierarchical rule. These results suggest that human-like generalization from text alone requires stronger biases than the general sequence-processing biases of standard neural network architectures.