 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
Fused Gromov-Wasserstein Variance Decomposition with Linear Optimal Transport
Nov 15, 2024



Wasserstein distances form a family of metrics on spaces of probability measures that have recently seen many applications. However, statistical analysis in these spaces is complex due to the nonlinearity of Wasserstein spaces. One potential solution to this problem is Linear Optimal Transport (LOT). This method allows one to find a Euclidean embedding, called LOT embedding, of measures in some Wasserstein spaces, but some information is lost in this embedding. So, to understand whether statistical analysis relying on LOT embeddings can make valid inferences about original data, it is helpful to quantify how well these embeddings describe that data. To answer this question, we present a decomposition of the Fr\'echet variance of a set of measures in the 2-Wasserstein space, which allows one to compute the percentage of variance explained by LOT embeddings of those measures. We then extend this decomposition to the Fused Gromov-Wasserstein setting. We also present several experiments that explore the relationship between the dimension of the LOT embedding, the percentage of variance explained by the embedding, and the classification accuracy of machine learning classifiers built on the embedded data. We use the MNIST handwritten digits dataset, IMDB-50000 dataset, and Diffusion Tensor MRI images for these experiments. Our results illustrate the effectiveness of low dimensional LOT embeddings in terms of the percentage of variance explained and the classification accuracy of models built on the embedded data.
FairLENS: Assessing Fairness in Law Enforcement Speech Recognition
May 21, 2024Automatic speech recognition (ASR) techniques have become powerful tools, enhancing efficiency in law enforcement scenarios. To ensure fairness for demographic groups in different acoustic environments, ASR engines must be tested across a variety of speakers in realistic settings. However, describing the fairness discrepancies between models with confidence remains a challenge. Meanwhile, most public ASR datasets are insufficient to perform a satisfying fairness evaluation. To address the limitations, we built FairLENS - a systematic fairness evaluation framework. We propose a novel and adaptable evaluation method to examine the fairness disparity between different models. We also collected a fairness evaluation dataset covering multiple scenarios and demographic dimensions. Leveraging this framework, we conducted fairness assessments on 1 open-source and 11 commercially available state-of-the-art ASR models. Our results reveal that certain models exhibit more biases than others, serving as a fairness guideline for users to make informed choices when selecting ASR models for a given real-world scenario. We further explored model biases towards specific demographic groups and observed that shifts in the acoustic domain can lead to the emergence of new biases.
How Abstract Is Linguistic Generalization in Large Language Models? Experiments with Argument Structure
Nov 08, 2023Language models are typically evaluated on their success at predicting the distribution of specific words in specific contexts. Yet linguistic knowledge also encodes relationships between contexts, allowing inferences between word distributions. We investigate the degree to which pre-trained Transformer-based large language models (LLMs) represent such relationships, focusing on the domain of argument structure. We find that LLMs perform well in generalizing the distribution of a novel noun argument between related contexts that were seen during pre-training (e.g., the active object and passive subject of the verb spray), succeeding by making use of the semantically-organized structure of the embedding space for word embeddings. However, LLMs fail at generalizations between related contexts that have not been observed during pre-training, but which instantiate more abstract, but well-attested structural generalizations (e.g., between the active object and passive subject of an arbitrary verb). Instead, in this case, LLMs show a bias to generalize based on linear order. This finding points to a limitation with current models and points to a reason for which their training is data-intensive.s reported here are available at https://github.com/clay-lab/structural-alternations.
Do Language Models Learn Position-Role Mappings?
Feb 08, 2022How is knowledge of position-role mappings in natural language learned? We explore this question in a computational setting, testing whether a variety of well-performing pertained language models (BERT, RoBERTa, and DistilBERT) exhibit knowledge of these mappings, and whether this knowledge persists across alternations in syntactic, structural, and lexical alternations. In Experiment 1, we show that these neural models do indeed recognize distinctions between theme and recipient roles in ditransitive constructions, and that these distinct patterns are shared across construction type. We strengthen this finding in Experiment 2 by showing that fine-tuning these language models on novel theme- and recipient-like tokens in one paradigm allows the models to make correct predictions about their placement in other paradigms, suggesting that the knowledge of these mappings is shared rather than independently learned. We do, however, observe some limitations of this generalization when tasks involve constructions with novel ditransitive verbs, hinting at a degree of lexical specificity which underlies model performance.
Machine Learning Trivializing Maps: A First Step Towards Understanding How Flow-Based Samplers Scale Up
Dec 31, 2021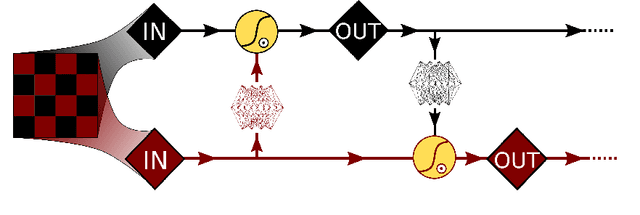
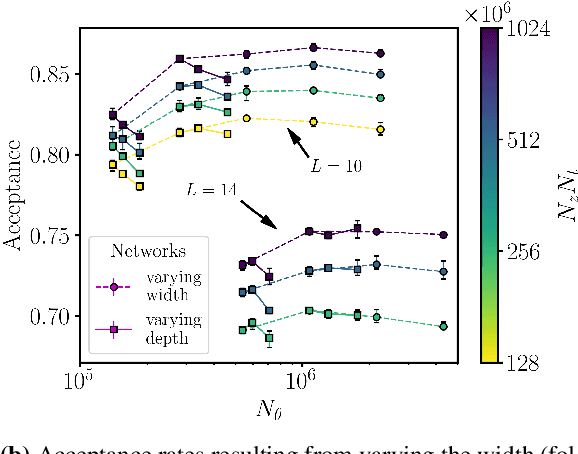
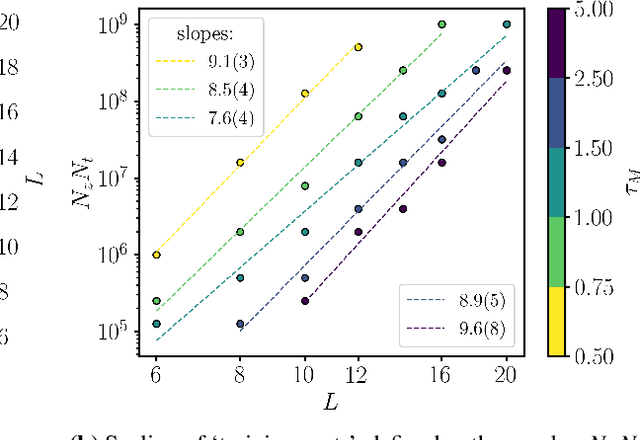
A trivializing map is a field transformation whose Jacobian determinant exactly cancels the interaction terms in the action, providing a representation of the theory in terms of a deterministic transformation of a distribution from which sampling is trivial. Recently, a proof-of-principle study by Albergo, Kanwar and Shanahan [arXiv:1904.12072] demonstrated that approximations of trivializing maps can be `machine-learned' by a class of invertible, differentiable neural models called \textit{normalizing flows}. By ensuring that the Jacobian determinant can be computed efficiently, asymptotically exact sampling from the theory of interest can be performed by drawing samples from a simple distribution and passing them through the network. From a theoretical perspective, this approach has the potential to become more efficient than traditional Markov Chain Monte Carlo sampling techniques, where autocorrelations severely diminish the sampling efficiency as one approaches the continuum limit. A major caveat is that it is not yet understood how the size of models and the cost of training them is expected to scale. As a first step, we have conducted an exploratory scaling study using two-dimensional $\phi^4$ with up to $20^2$ lattice sites. Although the scope of our study is limited to a particular model architecture and training algorithm, initial results paint an interesting picture in which training costs grow very quickly indeed. We describe a candidate explanation for the poor scaling, and outline our intentions to clarify the situation in future work.
A Topological Approach for Motion Track Discrimination
Feb 10, 2021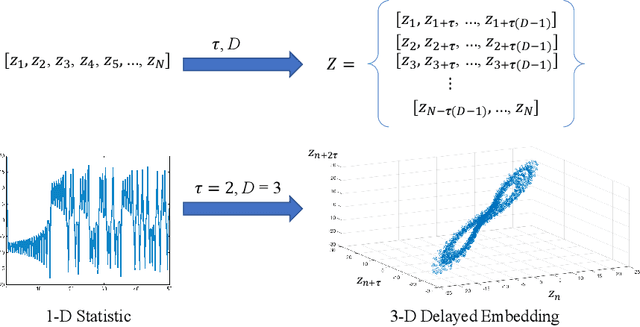
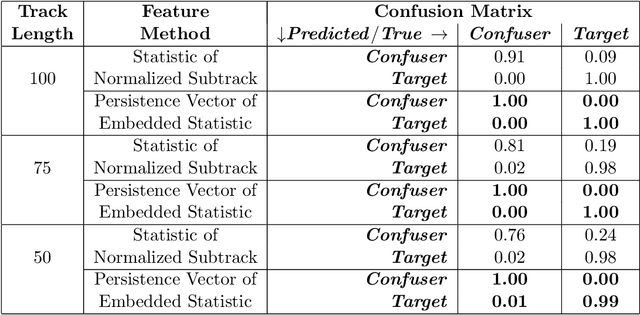
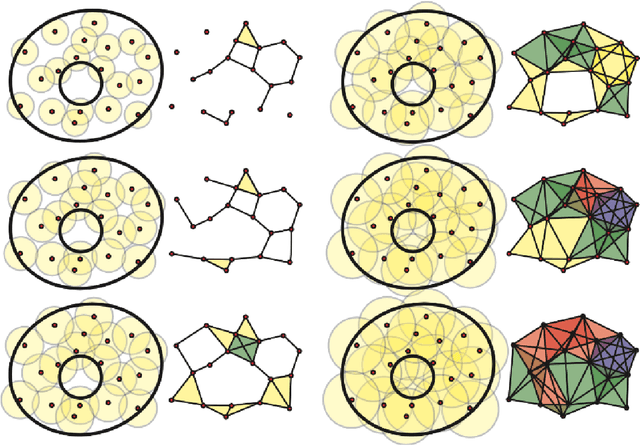
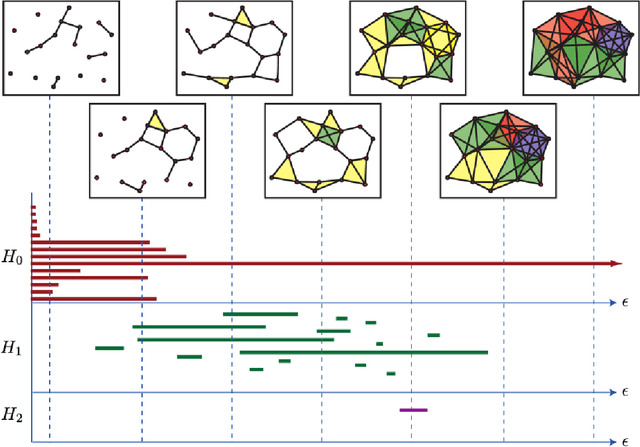
Detecting small targets at range is difficult because there is not enough spatial information present in an image sub-region containing the target to use correlation-based methods to differentiate it from dynamic confusers present in the scene. Moreover, this lack of spatial information also disqualifies the use of most state-of-the-art deep learning image-based classifiers. Here, we use characteristics of target tracks extracted from video sequences as data from which to derive distinguishing topological features that help robustly differentiate targets of interest from confusers. In particular, we calculate persistent homology from time-delayed embeddings of dynamic statistics calculated from motion tracks extracted from a wide field-of-view video stream. In short, we use topological methods to extract features related to target motion dynamics that are useful for classification and disambiguation and show that small targets can be detected at range with high probability.
Machine learning determination of dynamical parameters: The Ising model case
Oct 26, 2018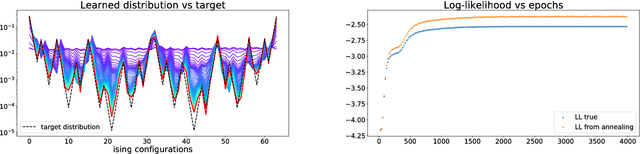
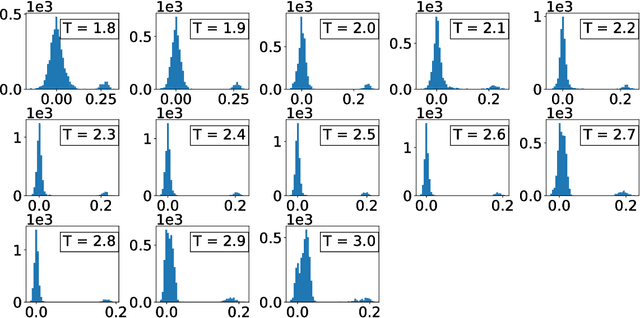
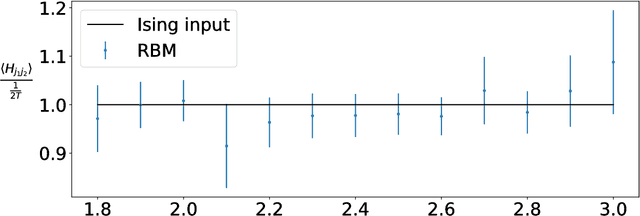
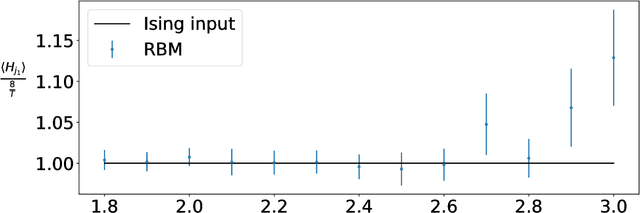
We train a set of Restricted Boltzmann Machines (RBMs) on one- and two-dimensional Ising spin configurations at various values of temperature, generated using Monte Carlo simulations. We validate the training procedure by monitoring several estimators, including measurements of the log-likelihood, with the corresponding partition functions estimated using annealed importance sampling. The effects of various choices of hyper-parameters on training the RBM are discussed in detail, with a generic prescription provided. Finally, we present a closed form expression for extracting the values of couplings, for every $n$-point interaction between the visible nodes of an RBM, in a binary system such as the Ising model. We aim at using this study as the foundation for further investigations of less well-known systems.
* 31 pages
Accurate, fully-automated NMR spectral profiling for metabolomics
Sep 08, 2014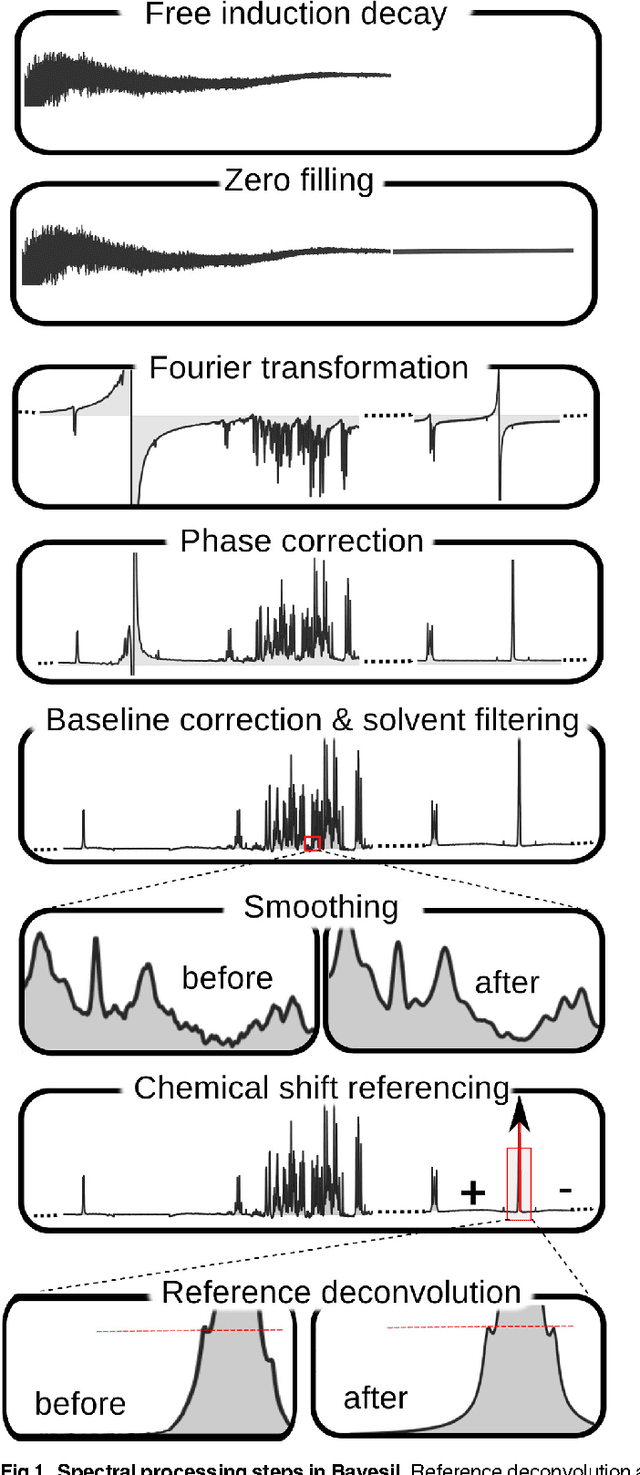
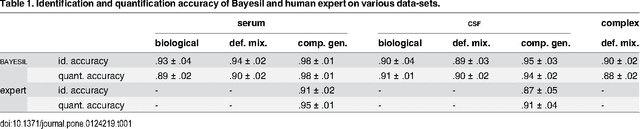
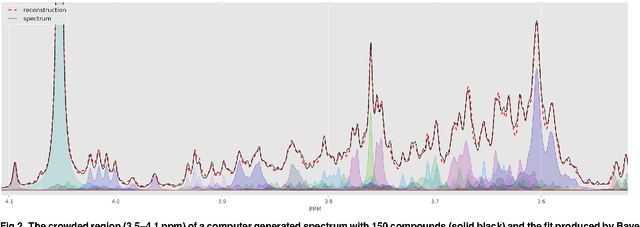
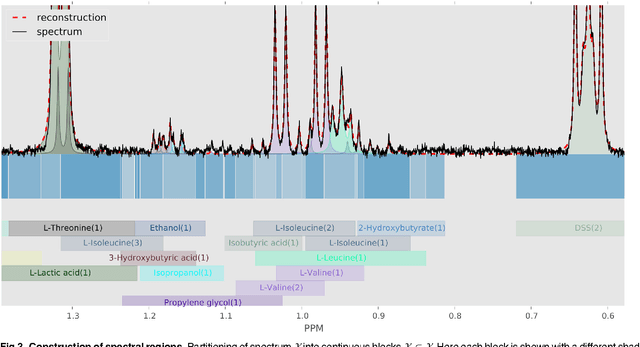
Many diseases cause significant changes to the concentrations of small molecules (aka metabolites) that appear in a person's biofluids, which means such diseases can often be readily detected from a person's "metabolic profile". This information can be extracted from a biofluid's NMR spectrum. Today, this is often done manually by trained human experts, which means this process is relatively slow, expensive and error-prone. This paper presents a tool, Bayesil, that can quickly, accurately and autonomously produce a complex biofluid's (e.g., serum or CSF) metabolic profile from a 1D1H NMR spectrum. This requires first performing several spectral processing steps then matching the resulting spectrum against a reference compound library, which contains the "signatures" of each relevant metabolite. Many of these steps are novel algorithms and our matching step views spectral matching as an inference problem within a probabilistic graphical model that rapidly approximates the most probable metabolic profile. Our extensive studies on a diverse set of complex mixtures, show that Bayesil can autonomously find the concentration of all NMR-detectable metabolites accurately (~90% correct identification and ~10% quantification error), in <5minutes on a single CPU. These results demonstrate that Bayesil is the first fully-automatic publicly-accessible system that provides quantitative NMR spectral profiling effectively -- with an accuracy that meets or exceeds the performance of trained experts. We anticipate this tool will usher in high-throughput metabolomics and enable a wealth of new applications of NMR in clinical settings. Available at http://www.bayesil.ca.